 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribe-Then-Act: Proactive Agent Steering via Distilled Language-Action World Models
Mar 24, 2026Deploying safety-critical agents requires anticipating the consequences of actions before they are executed. While world models offer a paradigm for this proactive foresight, current approaches relying on visual simulation incur prohibitive latencies, often exceeding several seconds per step. In this work, we challenge the assumption that visual processing is necessary for failure prevention. We show that a trained policy's latent state, combined with its planned actions, already encodes sufficient information to anticipate action outcomes, making visual simulation redundant for failure prevention. To this end, we introduce DILLO (DIstiLLed Language-ActiOn World Model), a fast steering layer that shifts the paradigm from "simulate-then-act" to "describe-then-act." DILLO is trained via cross-modal distillation, where a privileged Vision Language Model teacher annotates offline trajectories and a latent-conditioned Large Language Model student learns to predict semantic outcomes. This creates a text-only inference path, bypassing heavy visual generation entirely, achieving a 14x speedup over baselines. Experiments on MetaWorld and LIBERO demonstrate that DILLO produces high-fidelity descriptions of the next state and is able to steer the policy, improving episode success rate by up to 15 pp and 9.3 pp on average across tasks.
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
Mar 19, 2026Effective collaboration begins with knowing when to ask for help. For example, when trying to identify an occluded object, a human would ask someone to remove the obstruction. Can MLLMs exhibit a similar "proactive" behavior by requesting simple user interventions? To investigate this, we introduce ProactiveBench, a benchmark built from seven repurposed datasets that tests proactiveness across different tasks such as recognizing occluded objects, enhancing image quality, and interpreting coarse sketches. We evaluate 22 MLLMs on ProactiveBench, showing that (i) they generally lack proactiveness; (ii) proactiveness does not correlate with model capacity; (iii) "hinting" at proactiveness yields only marginal gains. Surprisingly, we found that conversation histories and in-context learning introduce negative biases, hindering performance. Finally, we explore a simple fine-tuning strategy based on reinforcement learning: its results suggest that proactiveness can be learned, even generalizing to unseen scenarios. We publicly release ProactiveBench as a first step toward building proactive multimodal models.
Diffusion Reinforcement Learning via Centered Reward Distillation
Mar 14, 2026Diffusion and flow models achieve State-Of-The-Art (SOTA) generative performance, yet many practically important behaviors such as fine-grained prompt fidelity, compositional correctness, and text rendering are weakly specified by score or flow matching pretraining objectives. Reinforcement Learning (RL) fine-tuning with external, black-box rewards is a natural remedy, but diffusion RL is often brittle. Trajectory-based methods incur high memory cost and high-variance gradient estimates; forward-process approaches converge faster but can suffer from distribution drift, and hence reward hacking. In this work, we present \textbf{Centered Reward Distillation (CRD)}, a diffusion RL framework derived from KL-regularized reward maximization built on forward-process-based fine-tuning. The key insight is that the intractable normalizing constant cancels under \emph{within-prompt centering}, yielding a well-posed reward-matching objective. To enable reliable text-to-image fine-tuning, we introduce techniques that explicitly control distribution drift: (\textit{i}) decoupling the sampler from the moving reference to prevent ratio-signal collapse, (\textit{ii}) KL anchoring to a CFG-guided pretrained model to control long-run drift and align with the inference-time semantics of the pre-trained model, and (\textit{iii}) reward-adaptive KL strength to accelerate early learning under large KL regularization while reducing late-stage exploitation of reward-model loopholes. Experiments on text-to-image post-training with \texttt{GenEval} and \texttt{OCR} rewards show that CRD achieves competitive SOTA reward optimization results with fast convergence and reduced reward hacking, as validated on unseen preference metrics.
Residual Tokens Enhance Masked Autoencoders for Speech Modeling
Jan 27, 2026Recent speech modeling relies on explicit attributes such as pitch, content, and speaker identity, but these alone cannot capture the full richness of natural speech. We introduce RT-MAE, a novel masked autoencoder framework that augments the supervised attributes-based modeling with unsupervised residual trainable tokens, designed to encode the information not explained by explicit labeled factors (e.g., timbre variations, noise, emotion etc). Experiments show that RT-MAE improves reconstruction quality, preserving content and speaker similarity while enhancing expressivity. We further demonstrate its applicability to speech enhancement, removing noise at inference while maintaining controllability and naturalness.
Don't Forget your Inverse DDIM for Image Editing
May 14, 2025



The field of text-to-image generation has undergone significant advancements with the introduction of diffusion models. Nevertheless, the challenge of editing real images persists, as most methods are either computationally intensive or produce poor reconstructions. This paper introduces SAGE (Self-Attention Guidance for image Editing) - a novel technique leveraging pre-trained diffusion models for image editing. SAGE builds upon the DDIM algorithm and incorporates a novel guidance mechanism utilizing the self-attention layers of the diffusion U-Net. This mechanism computes a reconstruction objective based on attention maps generated during the inverse DDIM process, enabling efficient reconstruction of unedited regions without the need to precisely reconstruct the entire input image. Thus, SAGE directly addresses the key challenges in image editing. The superiority of SAGE over other methods is demonstrated through quantitative and qualitative evaluations and confirmed by a statistically validated comprehensive user study, in which all 47 surveyed users preferred SAGE over competing methods. Additionally, SAGE ranks as the top-performing method in seven out of 10 quantitative analyses and secures second and third places in the remaining three.
Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator
Mar 19, 2025![Figure 1 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F6-Table1-1.png&w=640&q=75)
![Figure 2 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F3-Figure2-1.png&w=640&q=75)
![Figure 3 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F8-Table2-1.png&w=640&q=75)
![Figure 4 for Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c219ad77dbeec39e8440063d2e7b0d4c97cbd9a%2F5-Figure3-1.png&w=640&q=75)
Masked Diffusion Models (MDMs) have emerged as a powerful generative modeling technique. Despite their remarkable results, they typically suffer from slow inference with several steps. In this paper, we propose Di$\mathtt{[M]}$O, a novel approach that distills masked diffusion models into a one-step generator. Di$\mathtt{[M]}$O addresses two key challenges: (1) the intractability of using intermediate-step information for one-step generation, which we solve through token-level distribution matching that optimizes model output logits by an 'on-policy framework' with the help of an auxiliary model; and (2) the lack of entropy in the initial distribution, which we address through a token initialization strategy that injects randomness while maintaining similarity to teacher training distribution. We show Di$\mathtt{[M]}$O's effectiveness on both class-conditional and text-conditional image generation, impressively achieving performance competitive to multi-step teacher outputs while drastically reducing inference time. To our knowledge, we are the first to successfully achieve one-step distillation of masked diffusion models and the first to apply discrete distillation to text-to-image generation, opening new paths for efficient generative modeling.
Group-robust Machine Unlearning
Mar 12, 2025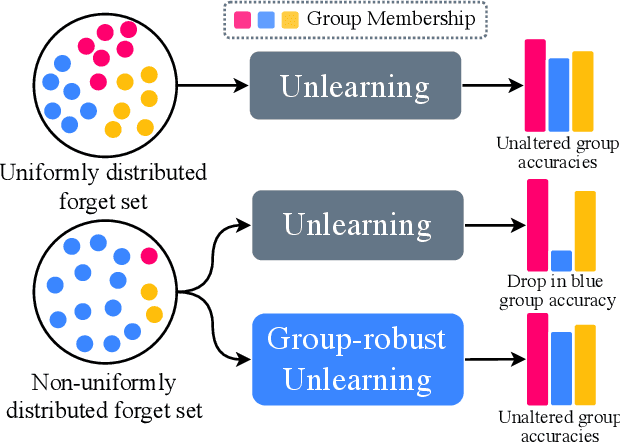
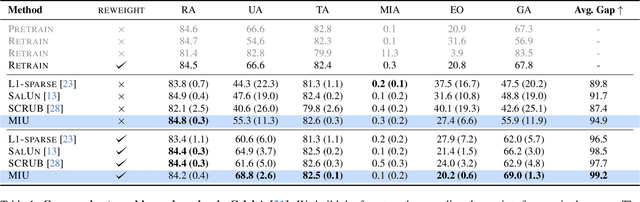
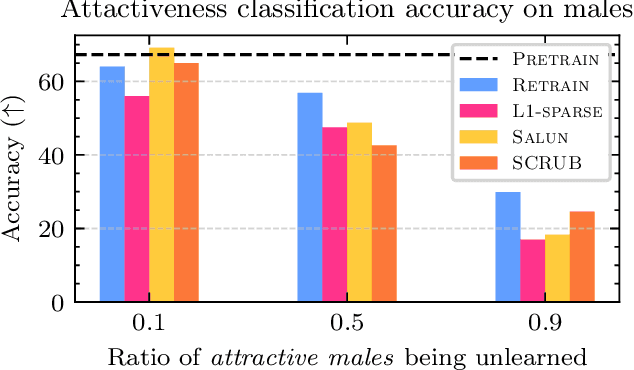
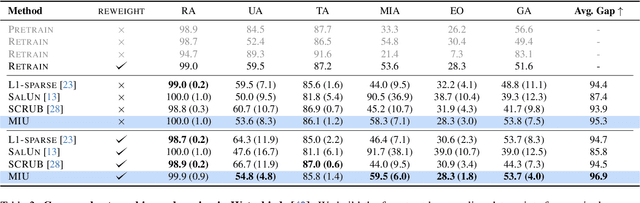
Machine unlearning is an emerging paradigm to remove the influence of specific training data (i.e., the forget set) from a model while preserving its knowledge of the rest of the data (i.e., the retain set). Previous approaches assume the forget data to be uniformly distributed from all training datapoints. However, if the data to unlearn is dominant in one group, we empirically show that performance for this group degrades, leading to fairness issues. This work tackles the overlooked problem of non-uniformly distributed forget sets, which we call group-robust machine unlearning, by presenting a simple, effective strategy that mitigates the performance loss in dominant groups via sample distribution reweighting. Moreover, we present MIU (Mutual Information-aware Machine Unlearning), the first approach for group robustness in approximate machine unlearning. MIU minimizes the mutual information between model features and group information, achieving unlearning while reducing performance degradation in the dominant group of the forget set. Additionally, MIU exploits sample distribution reweighting and mutual information calibration with the original model to preserve group robustness. We conduct experiments on three datasets and show that MIU outperforms standard methods, achieving unlearning without compromising model robustness. Source code available at https://github.com/tdemin16/group-robust_machine_unlearning.
OVOSE: Open-Vocabulary Semantic Segmentation in Event-Based Cameras
Aug 18, 2024



Event cameras, known for low-latency operation and superior performance in challenging lighting conditions, are suitable for sensitive computer vision tasks such as semantic segmentation in autonomous driving. However, challenges arise due to limited event-based data and the absence of large-scale segmentation benchmarks. Current works are confined to closed-set semantic segmentation, limiting their adaptability to other applications. In this paper, we introduce OVOSE, the first Open-Vocabulary Semantic Segmentation algorithm for Event cameras. OVOSE leverages synthetic event data and knowledge distillation from a pre-trained image-based foundation model to an event-based counterpart, effectively preserving spatial context and transferring open-vocabulary semantic segmentation capabilities. We evaluate the performance of OVOSE on two driving semantic segmentation datasets DDD17, and DSEC-Semantic, comparing it with existing conventional image open-vocabulary models adapted for event-based data. Similarly, we compare OVOSE with state-of-the-art methods designed for closed-set settings in unsupervised domain adaptation for event-based semantic segmentation. OVOSE demonstrates superior performance, showcasing its potential for real-world applications. The code is available at https://github.com/ram95d/OVOSE.
Specify and Edit: Overcoming Ambiguity in Text-Based Image Editing
Jul 29, 2024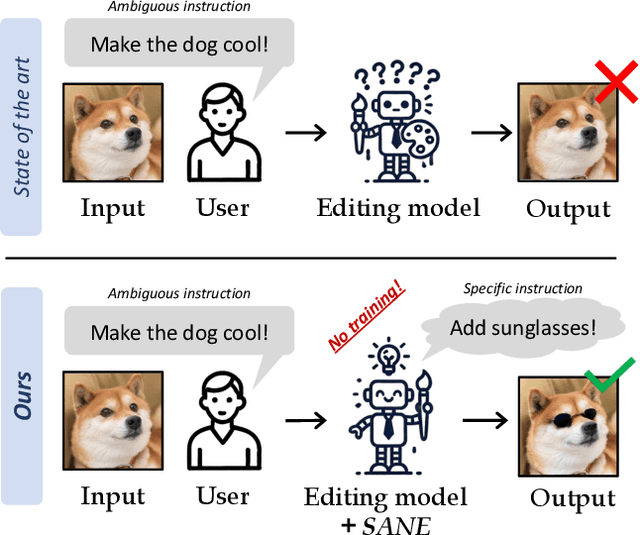
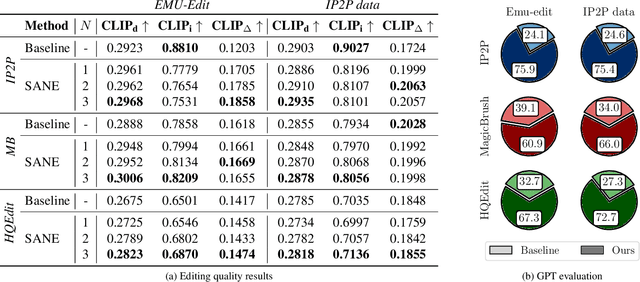
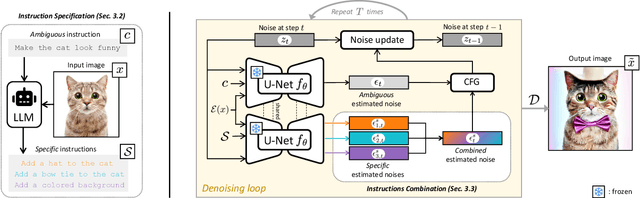

Text-based editing diffusion models exhibit limited performance when the user's input instruction is ambiguous. To solve this problem, we propose $\textit{Specify ANd Edit}$ (SANE), a zero-shot inference pipeline for diffusion-based editing systems. We use a large language model (LLM) to decompose the input instruction into specific instructions, i.e. well-defined interventions to apply to the input image to satisfy the user's request. We benefit from the LLM-derived instructions along the original one, thanks to a novel denoising guidance strategy specifically designed for the task. Our experiments with three baselines and on two datasets demonstrate the benefits of SANE in all setups. Moreover, our pipeline improves the interpretability of editing models, and boosts the output diversity. We also demonstrate that our approach can be applied to any edit, whether ambiguous or not. Our code is public at https://github.com/fabvio/SANE.
Privacy-Preserving Adaptive Re-Identification without Image Transfer
Jul 17, 2024



Re-Identification systems (Re-ID) are crucial for public safety but face the challenge of having to adapt to environments that differ from their training distribution. Furthermore, rigorous privacy protocols in public places are being enforced as apprehensions regarding individual freedom rise, adding layers of complexity to the deployment of accurate Re-ID systems in new environments. For example, in the European Union, the principles of ``Data Minimization'' and ``Purpose Limitation'' restrict the retention and processing of images to what is strictly necessary. These regulations pose a challenge to the conventional Re-ID training schemes that rely on centralizing data on servers. In this work, we present a novel setting for privacy-preserving Distributed Unsupervised Domain Adaptation for person Re-ID (DUDA-Rid) to address the problem of domain shift without requiring any image transfer outside the camera devices. To address this setting, we introduce Fed-Protoid, a novel solution that adapts person Re-ID models directly within the edge devices. Our proposed solution employs prototypes derived from the source domain to align feature statistics within edge devices. Those source prototypes are distributed across the edge devices to minimize a distributed Maximum Mean Discrepancy (MMD) loss tailored for the DUDA-Rid setting. Our experiments provide compelling evidence that Fed-Protoid outperforms all evaluated methods in terms of both accuracy and communication efficiency, all while maintaining data privacy.