 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
Apr 14, 2025
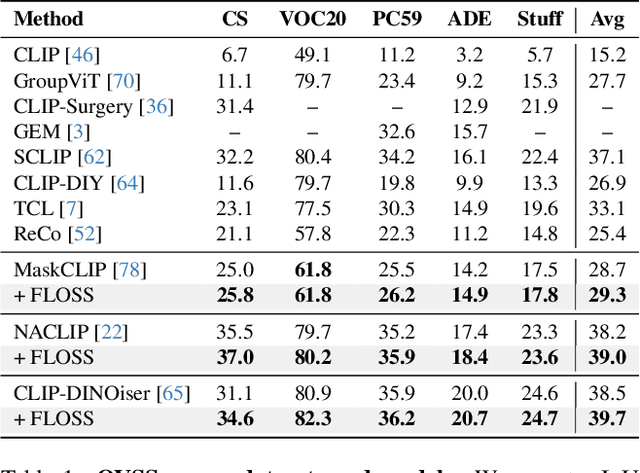


Recent Open-Vocabulary Semantic Segmentation (OVSS) models extend the CLIP model to segmentation while maintaining the use of multiple templates (e.g., a photo of <class>, a sketch of a <class>, etc.) for constructing class-wise averaged text embeddings, acting as a classifier. In this paper, we challenge this status quo and investigate the impact of templates for OVSS. Empirically, we observe that for each class, there exist single-template classifiers significantly outperforming the conventional averaged classifier. We refer to them as class-experts. Given access to unlabeled images and without any training involved, we estimate these experts by leveraging the class-wise prediction entropy of single-template classifiers, selecting as class-wise experts those which yield the lowest entropy. All experts, each specializing in a specific class, collaborate in a newly proposed fusion method to generate more accurate OVSS predictions. Our plug-and-play method, coined FLOSS, is orthogonal and complementary to existing OVSS methods, offering a ''free lunch'' to systematically improve OVSS without labels and additional training. Extensive experiments demonstrate that FLOSS consistently boosts state-of-the-art methods on various OVSS benchmarks. Moreover, the selected expert templates can generalize well from one dataset to others sharing the same semantic categories, yet exhibiting distribution shifts. Additionally, we obtain satisfactory improvements under a low-data regime, where only a few unlabeled images are available. Our code is available at https://github.com/yasserben/FLOSS .
Collaborating Foundation models for Domain Generalized Semantic Segmentation
Dec 15, 2023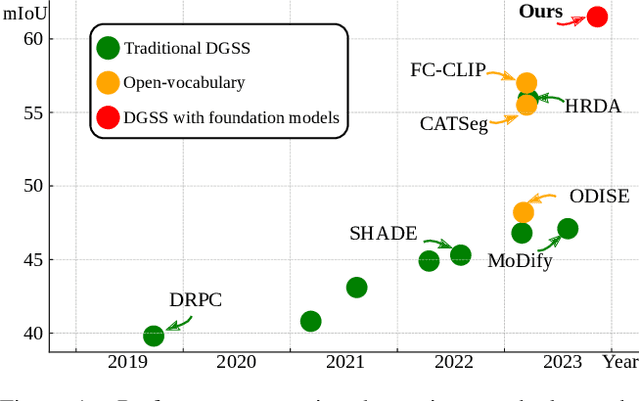
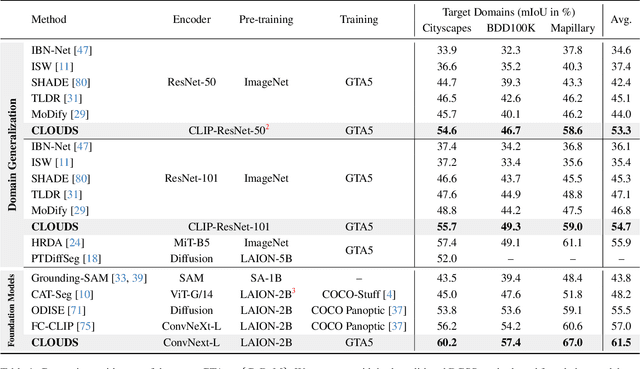

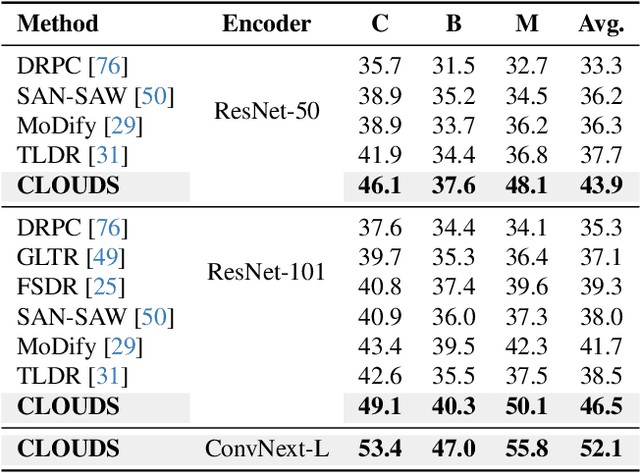
Domain Generalized Semantic Segmentation (DGSS) deals with training a model on a labeled source domain with the aim of generalizing to unseen domains during inference. Existing DGSS methods typically effectuate robust features by means of Domain Randomization (DR). Such an approach is often limited as it can only account for style diversification and not content. In this work, we take an orthogonal approach to DGSS and propose to use an assembly of CoLlaborative FOUndation models for Domain Generalized Semantic Segmentation (CLOUDS). In detail, CLOUDS is a framework that integrates FMs of various kinds: (i) CLIP backbone for its robust feature representation, (ii) generative models to diversify the content, thereby covering various modes of the possible target distribution, and (iii) Segment Anything Model (SAM) for iteratively refining the predictions of the segmentation model. Extensive experiments show that our CLOUDS excels in adapting from synthetic to real DGSS benchmarks and under varying weather conditions, notably outperforming prior methods by 5.6% and 6.7% on averaged miou, respectively. The code is available at : https://github.com/yasserben/CLOUDS
One-shot Unsupervised Domain Adaptation with Personalized Diffusion Models
Mar 31, 2023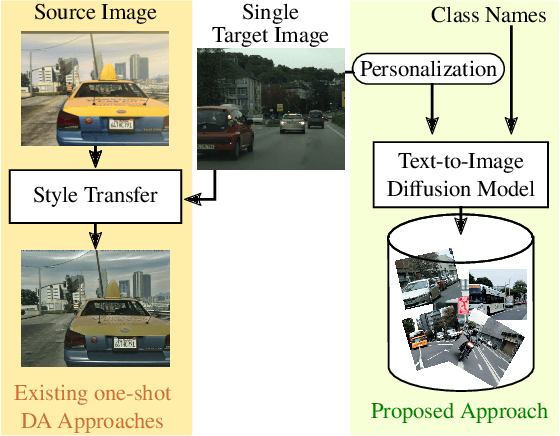
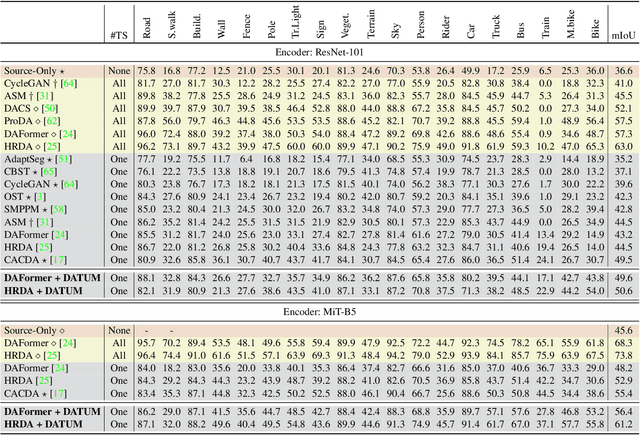
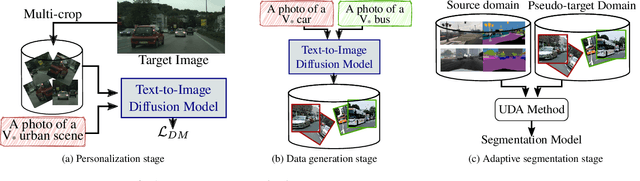
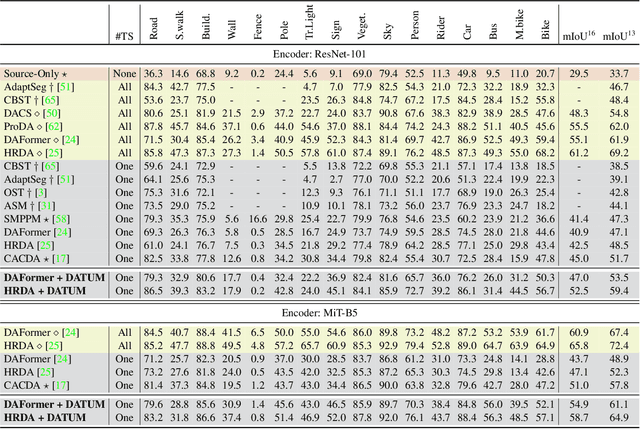
Adapting a segmentation model from a labeled source domain to a target domain, where a single unlabeled datum is available, is one the most challenging problems in domain adaptation and is otherwise known as one-shot unsupervised domain adaptation (OSUDA). Most of the prior works have addressed the problem by relying on style transfer techniques, where the source images are stylized to have the appearance of the target domain. Departing from the common notion of transferring only the target ``texture'' information, we leverage text-to-image diffusion models (e.g., Stable Diffusion) to generate a synthetic target dataset with photo-realistic images that not only faithfully depict the style of the target domain, but are also characterized by novel scenes in diverse contexts. The text interface in our method Data AugmenTation with diffUsion Models (DATUM) endows us with the possibility of guiding the generation of images towards desired semantic concepts while respecting the original spatial context of a single training image, which is not possible in existing OSUDA methods. Extensive experiments on standard benchmarks show that our DATUM surpasses the state-of-the-art OSUDA methods by up to +7.1%. The implementation is available at https://github.com/yasserben/DATUM