 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPA: An Information-Preserving Input Projection Framework for Efficient Foundation Model Adaptation
Sep 04, 2025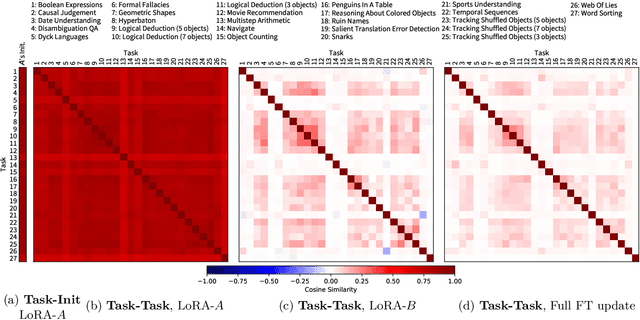
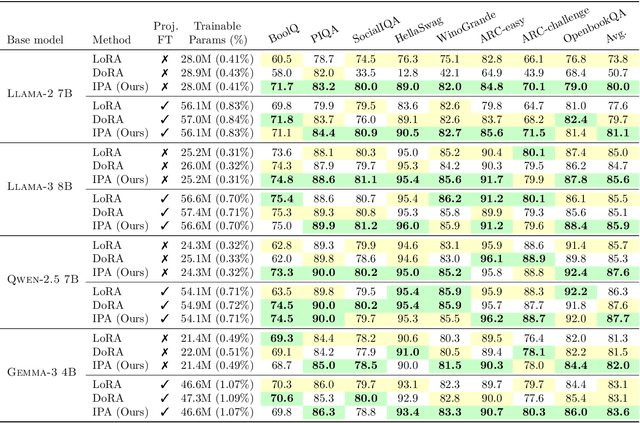
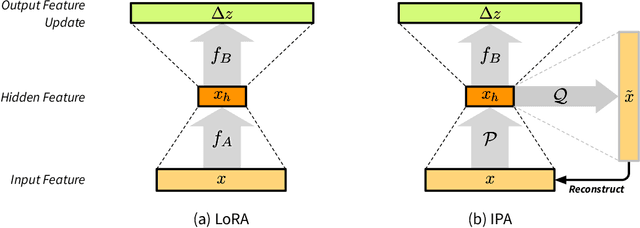
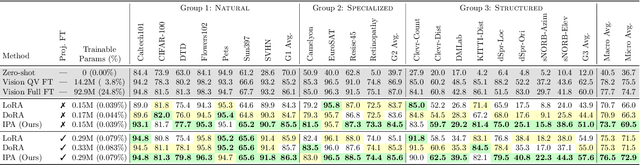
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA's down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly preserves information in the reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen.
FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
Apr 14, 2025Recent Open-Vocabulary Semantic Segmentation (OVSS) models extend the CLIP model to segmentation while maintaining the use of multiple templates (e.g., a photo of <class>, a sketch of a <class>, etc.) for constructing class-wise averaged text embeddings, acting as a classifier. In this paper, we challenge this status quo and investigate the impact of templates for OVSS. Empirically, we observe that for each class, there exist single-template classifiers significantly outperforming the conventional averaged classifier. We refer to them as class-experts. Given access to unlabeled images and without any training involved, we estimate these experts by leveraging the class-wise prediction entropy of single-template classifiers, selecting as class-wise experts those which yield the lowest entropy. All experts, each specializing in a specific class, collaborate in a newly proposed fusion method to generate more accurate OVSS predictions. Our plug-and-play method, coined FLOSS, is orthogonal and complementary to existing OVSS methods, offering a ''free lunch'' to systematically improve OVSS without labels and additional training. Extensive experiments demonstrate that FLOSS consistently boosts state-of-the-art methods on various OVSS benchmarks. Moreover, the selected expert templates can generalize well from one dataset to others sharing the same semantic categories, yet exhibiting distribution shifts. Additionally, we obtain satisfactory improvements under a low-data regime, where only a few unlabeled images are available. Our code is available at https://github.com/yasserben/FLOSS .
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
PPT: Pre-Training with Pseudo-Labeled Trajectories for Motion Forecasting
Dec 09, 2024Motion forecasting (MF) for autonomous driving aims at anticipating trajectories of surrounding agents in complex urban scenarios. In this work, we investigate a mixed strategy in MF training that first pre-train motion forecasters on pseudo-labeled data, then fine-tune them on annotated data. To obtain pseudo-labeled trajectories, we propose a simple pipeline that leverages off-the-shelf single-frame 3D object detectors and non-learning trackers. The whole pre-training strategy including pseudo-labeling is coined as PPT. Our extensive experiments demonstrate that: (1) combining PPT with supervised fine-tuning on annotated data achieves superior performance on diverse testbeds, especially under annotation-efficient regimes, (2) scaling up to multiple datasets improves the previous state-of-the-art and (3) PPT helps enhance cross-dataset generalization. Our findings showcase PPT as a promising pre-training solution for robust motion forecasting in diverse autonomous driving contexts.
Domain Adaptation with a Single Vision-Language Embedding
Oct 28, 2024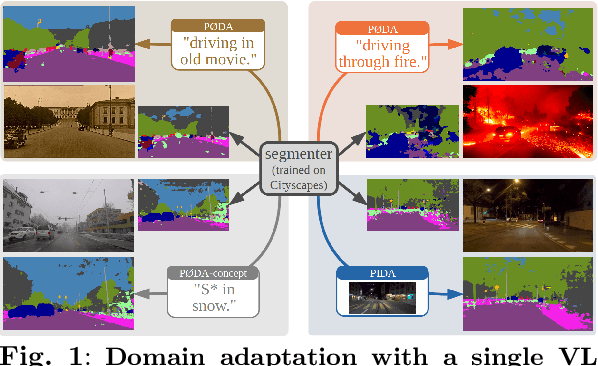
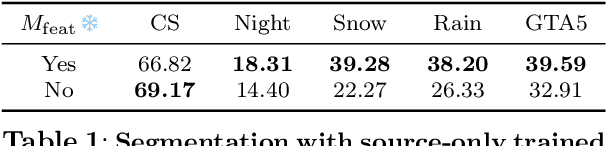
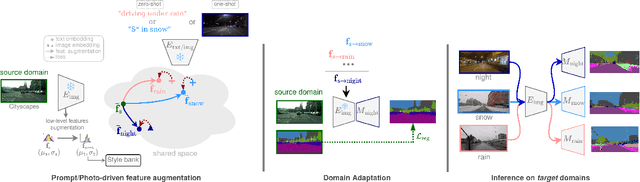
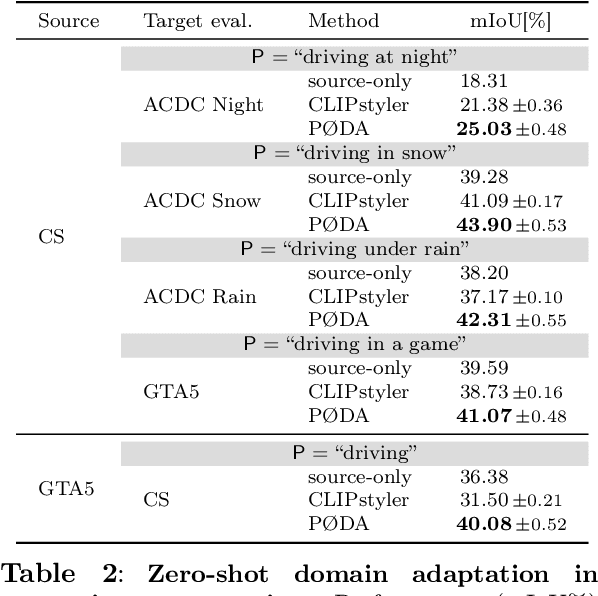
Domain adaptation has been extensively investigated in computer vision but still requires access to target data at the training time, which might be difficult to obtain in some uncommon conditions. In this paper, we present a new framework for domain adaptation relying on a single Vision-Language (VL) latent embedding instead of full target data. First, leveraging a contrastive language-image pre-training model (CLIP), we propose prompt/photo-driven instance normalization (PIN). PIN is a feature augmentation method that mines multiple visual styles using a single target VL latent embedding, by optimizing affine transformations of low-level source features. The VL embedding can come from a language prompt describing the target domain, a partially optimized language prompt, or a single unlabeled target image. Second, we show that these mined styles (i.e., augmentations) can be used for zero-shot (i.e., target-free) and one-shot unsupervised domain adaptation. Experiments on semantic segmentation demonstrate the effectiveness of the proposed method, which outperforms relevant baselines in the zero-shot and one-shot settings.
Fine-Tuning CLIP's Last Visual Projector: A Few-Shot Cornucopia
Oct 07, 2024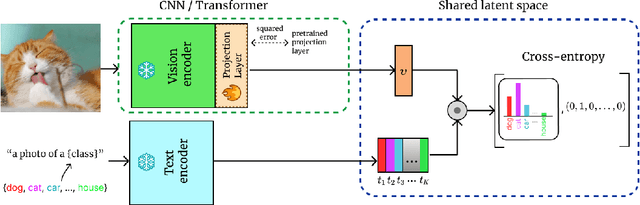
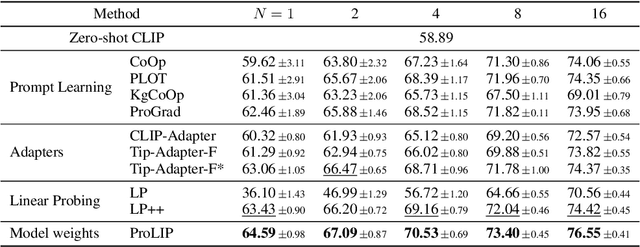

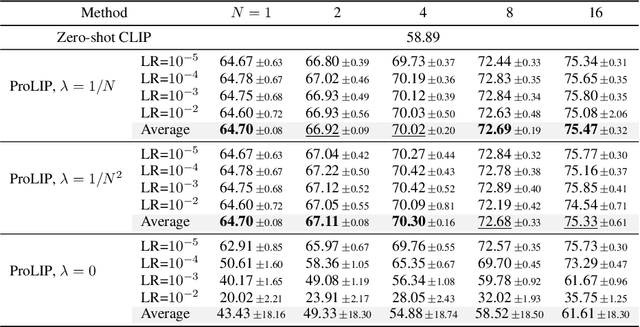
We consider the problem of adapting a contrastively pretrained vision-language model like CLIP (Radford et al., 2021) for few-shot classification. The existing literature addresses this problem by learning a linear classifier of the frozen visual features, optimizing word embeddings, or learning external feature adapters. This paper introduces an alternative way for CLIP adaptation without adding 'external' parameters to optimize. We find that simply fine-tuning the last projection matrix of the vision encoder leads to strong performance compared to the existing baselines. Furthermore, we show that regularizing training with the distance between the fine-tuned and pretrained matrices adds reliability for adapting CLIP through this layer. Perhaps surprisingly, this approach, coined ProLIP, yields performances on par or better than state of the art on 11 few-shot classification benchmarks, few-shot domain generalization, cross-dataset transfer and test-time adaptation. Code will be made available at https://github.com/astra-vision/ProLIP .
Train Till You Drop: Towards Stable and Robust Source-free Unsupervised 3D Domain Adaptation
Sep 06, 2024We tackle the challenging problem of source-free unsupervised domain adaptation (SFUDA) for 3D semantic segmentation. It amounts to performing domain adaptation on an unlabeled target domain without any access to source data; the available information is a model trained to achieve good performance on the source domain. A common issue with existing SFUDA approaches is that performance degrades after some training time, which is a by product of an under-constrained and ill-posed problem. We discuss two strategies to alleviate this issue. First, we propose a sensible way to regularize the learning problem. Second, we introduce a novel criterion based on agreement with a reference model. It is used (1) to stop the training when appropriate and (2) as validator to select hyperparameters without any knowledge on the target domain. Our contributions are easy to implement and readily amenable for all SFUDA methods, ensuring stable improvements over all baselines. We validate our findings on various 3D lidar settings, achieving state-of-the-art performance. The project repository (with code) is: github.com/valeoai/TTYD.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024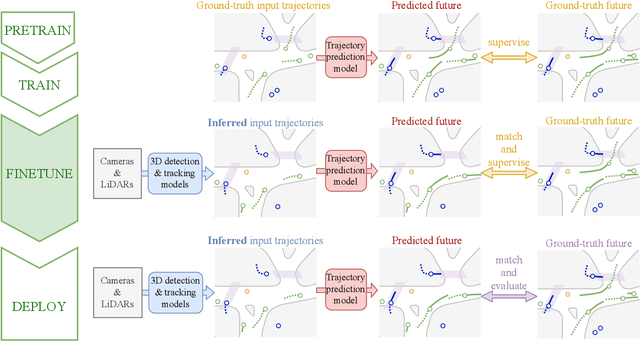
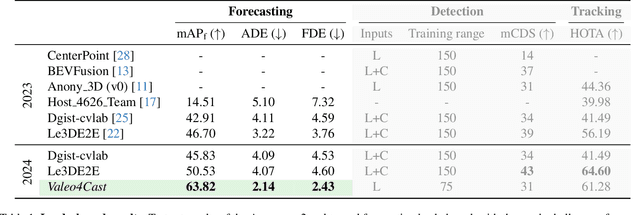
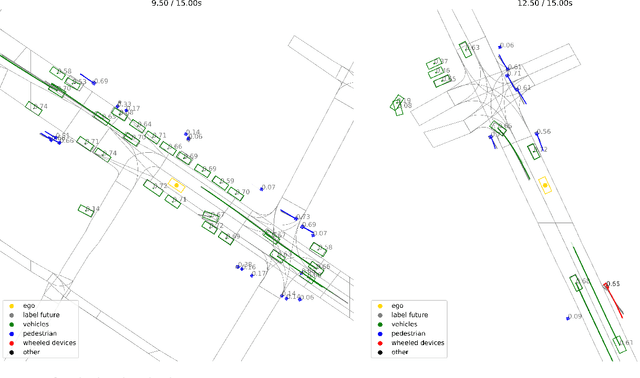
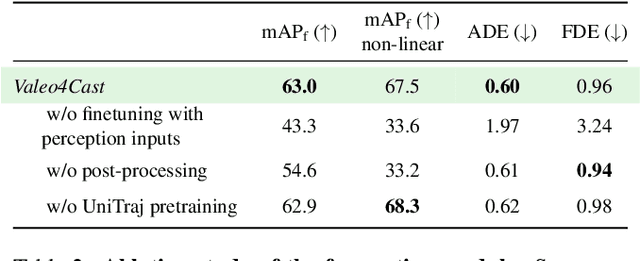
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
Reliability in Semantic Segmentation: Can We Use Synthetic Data?
Dec 14, 2023
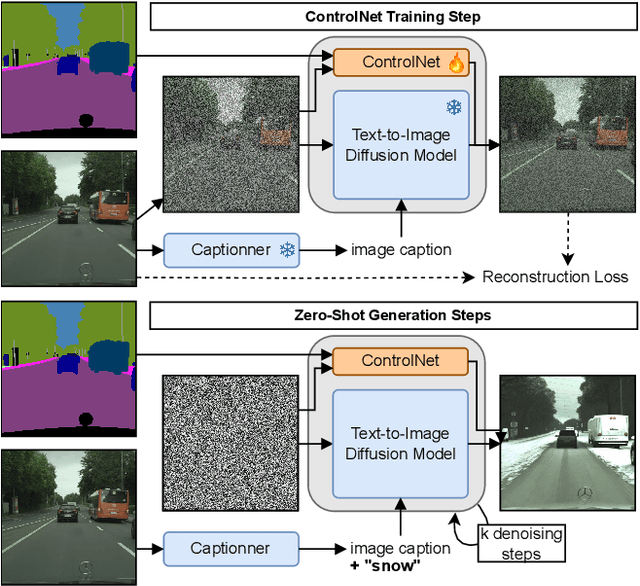
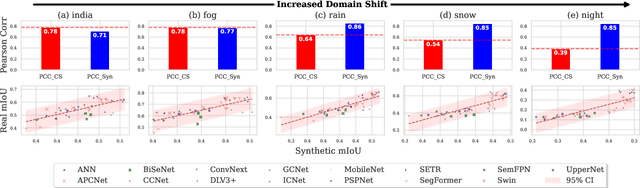
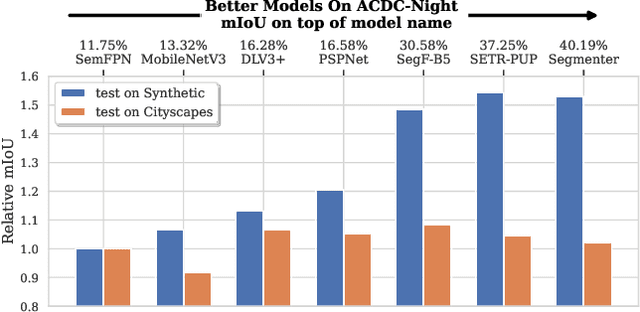
Assessing the reliability of perception models to covariate shifts and out-of-distribution (OOD) detection is crucial for safety-critical applications such as autonomous vehicles. By nature of the task, however, the relevant data is difficult to collect and annotate. In this paper, we challenge cutting-edge generative models to automatically synthesize data for assessing reliability in semantic segmentation. By fine-tuning Stable Diffusion, we perform zero-shot generation of synthetic data in OOD domains or inpainted with OOD objects. Synthetic data is employed to provide an initial assessment of pretrained segmenters, thereby offering insights into their performance when confronted with real edge cases. Through extensive experiments, we demonstrate a high correlation between the performance on synthetic data and the performance on real OOD data, showing the validity approach. Furthermore, we illustrate how synthetic data can be utilized to enhance the calibration and OOD detection capabilities of segmenters.
A Simple Recipe for Language-guided Domain Generalized Segmentation
Nov 29, 2023



Generalization to new domains not seen during training is one of the long-standing goals and challenges in deploying neural networks in real-world applications. Existing generalization techniques necessitate substantial data augmentation, potentially sourced from external datasets, and aim at learning invariant representations by imposing various alignment constraints. Large-scale pretraining has recently shown promising generalization capabilities, along with the potential of bridging different modalities. For instance, the recent advent of vision-language models like CLIP has opened the doorway for vision models to exploit the textual modality. In this paper, we introduce a simple framework for generalizing semantic segmentation networks by employing language as the source of randomization. Our recipe comprises three key ingredients: i) the preservation of the intrinsic CLIP robustness through minimal fine-tuning, ii) language-driven local style augmentation, and iii) randomization by locally mixing the source and augmented styles during training. Extensive experiments report state-of-the-art results on various generalization benchmarks. The code will be made available.