 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Conditioning with Representation-Aligned Visual Features
Feb 03, 2026While representation alignment with self-supervised models has been shown to improve diffusion model training, its potential for enhancing inference-time conditioning remains largely unexplored. We introduce Representation-Aligned Guidance (REPA-G), a framework that leverages these aligned representations, with rich semantic properties, to enable test-time conditioning from features in generation. By optimizing a similarity objective (the potential) at inference, we steer the denoising process toward a conditioned representation extracted from a pre-trained feature extractor. Our method provides versatile control at multiple scales, ranging from fine-grained texture matching via single patches to broad semantic guidance using global image feature tokens. We further extend this to multi-concept composition, allowing for the faithful combination of distinct concepts. REPA-G operates entirely at inference time, offering a flexible and precise alternative to often ambiguous text prompts or coarse class labels. We theoretically justify how this guidance enables sampling from the potential-induced tilted distribution. Quantitative results on ImageNet and COCO demonstrate that our approach achieves high-quality, diverse generations. Code is available at https://github.com/valeoai/REPA-G.
Leveraging 3D Representation Alignment and RGB Pretrained Priors for LiDAR Scene Generation
Jan 12, 2026LiDAR scene synthesis is an emerging solution to scarcity in 3D data for robotic tasks such as autonomous driving. Recent approaches employ diffusion or flow matching models to generate realistic scenes, but 3D data remains limited compared to RGB datasets with millions of samples. We introduce R3DPA, the first LiDAR scene generation method to unlock image-pretrained priors for LiDAR point clouds, and leverage self-supervised 3D representations for state-of-the-art results. Specifically, we (i) align intermediate features of our generative model with self-supervised 3D features, which substantially improves generation quality; (ii) transfer knowledge from large-scale image-pretrained generative models to LiDAR generation, mitigating limited LiDAR datasets; and (iii) enable point cloud control at inference for object inpainting and scene mixing with solely an unconditional model. On the KITTI-360 benchmark R3DPA achieves state of the art performance. Code and pretrained models are available at https://github.com/valeoai/R3DPA.
Driving on Registers
Jan 08, 2026We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving. Code and checkpoints will be made available via the project page.
LOSC: LiDAR Open-voc Segmentation Consolidator
Jul 10, 2025We study the use of image-based Vision-Language Models (VLMs) for open-vocabulary segmentation of lidar scans in driving settings. Classically, image semantics can be back-projected onto 3D point clouds. Yet, resulting point labels are noisy and sparse. We consolidate these labels to enforce both spatio-temporal consistency and robustness to image-level augmentations. We then train a 3D network based on these refined labels. This simple method, called LOSC, outperforms the SOTA of zero-shot open-vocabulary semantic and panoptic segmentation on both nuScenes and SemanticKITTI, with significant margins.
LOGen: Toward Lidar Object Generation by Point Diffusion
Dec 10, 2024



A common strategy to improve lidar segmentation results on rare semantic classes consists of pasting objects from one lidar scene into another. While this augments the quantity of instances seen at training time and varies their context, the instances fundamentally remain the same. In this work, we explore how to enhance instance diversity using a lidar object generator. We introduce a novel diffusion-based method to produce lidar point clouds of dataset objects, including reflectance, and with an extensive control of the generation via conditioning information. Our experiments on nuScenes show the quality of our object generations measured with new 3D metrics developed to suit lidar objects.
MILAN: Milli-Annotations for Lidar Semantic Segmentation
Jul 22, 2024



Annotating lidar point clouds for autonomous driving is a notoriously expensive and time-consuming task. In this work, we show that the quality of recent self-supervised lidar scan representations allows a great reduction of the annotation cost. Our method has two main steps. First, we show that self-supervised representations allow a simple and direct selection of highly informative lidar scans to annotate: training a network on these selected scans leads to much better results than a random selection of scans and, more interestingly, to results on par with selections made by SOTA active learning methods. In a second step, we leverage the same self-supervised representations to cluster points in our selected scans. Asking the annotator to classify each cluster, with a single click per cluster, then permits us to close the gap with fully-annotated training sets, while only requiring one thousandth of the point labels.
PAFUSE: Part-based Diffusion for 3D Whole-Body Pose Estimation
Jul 14, 2024We introduce a novel approach for 3D whole-body pose estimation, addressing the challenge of scale- and deformability- variance across body parts brought by the challenge of extending the 17 major joints on the human body to fine-grained keypoints on the face and hands. In addition to addressing the challenge of exploiting motion in unevenly sampled data, we combine stable diffusion to a hierarchical part representation which predicts the relative locations of fine-grained keypoints within each part (e.g., face) with respect to the part's local reference frame. On the H3WB dataset, our method greatly outperforms the current state of the art, which fails to exploit the temporal information. We also show considerable improvements compared to other spatiotemporal 3D human-pose estimation approaches that fail to account for the body part specificities. Code is available at https://github.com/valeoai/PAFUSE.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024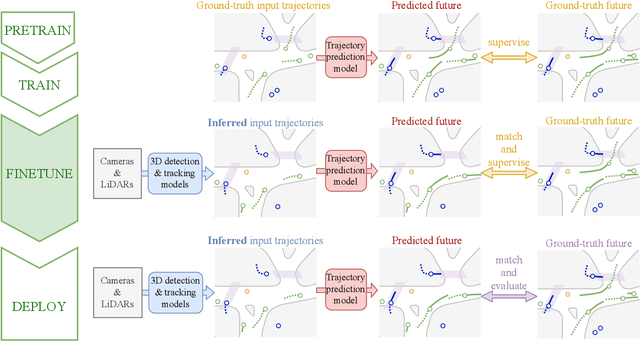
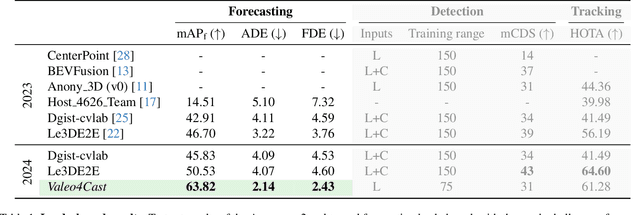
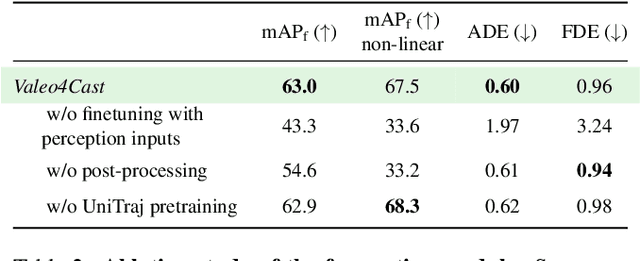
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
ManiPose: Manifold-Constrained Multi-Hypothesis 3D Human Pose Estimation
Dec 11, 2023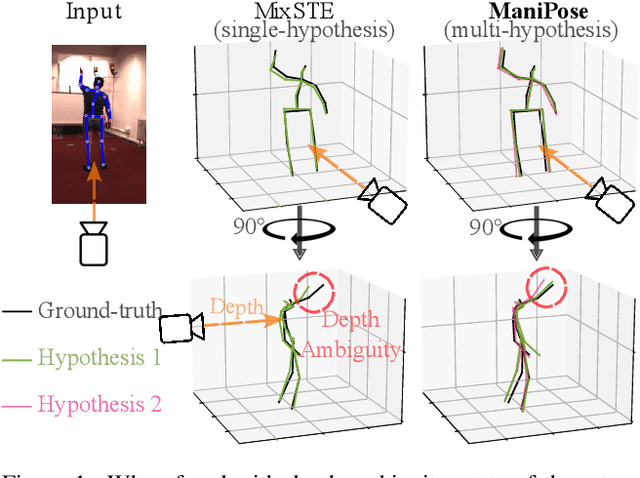
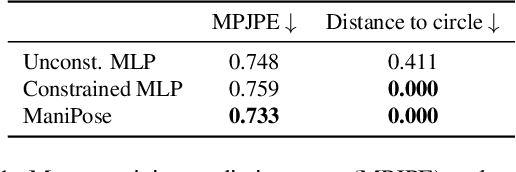
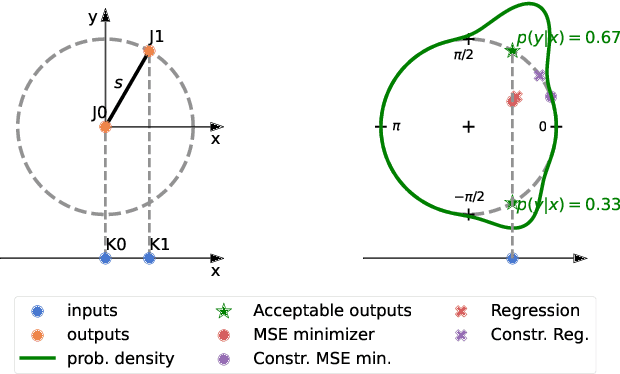
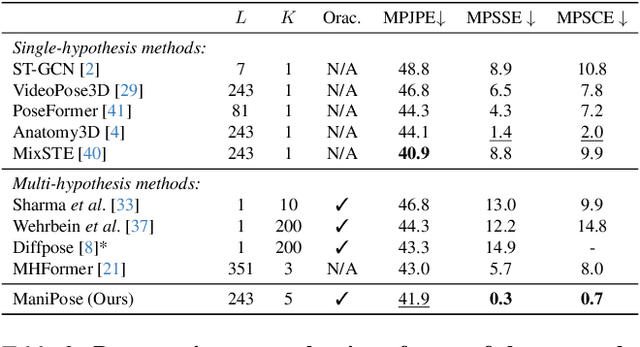
Monocular 3D human pose estimation (3D-HPE) is an inherently ambiguous task, as a 2D pose in an image might originate from different possible 3D poses. Yet, most 3D-HPE methods rely on regression models, which assume a one-to-one mapping between inputs and outputs. In this work, we provide theoretical and empirical evidence that, because of this ambiguity, common regression models are bound to predict topologically inconsistent poses, and that traditional evaluation metrics, such as the MPJPE, P-MPJPE and PCK, are insufficient to assess this aspect. As a solution, we propose ManiPose, a novel manifold-constrained multi-hypothesis model capable of proposing multiple candidate 3D poses for each 2D input, together with their corresponding plausibility. Unlike previous multi-hypothesis approaches, our solution is completely supervised and does not rely on complex generative models, thus greatly facilitating its training and usage. Furthermore, by constraining our model to lie within the human pose manifold, we can guarantee the consistency of all hypothetical poses predicted with our approach, which was not possible in previous works. We illustrate the usefulness of ManiPose in a synthetic 1D-to-2D lifting setting and demonstrate on real-world datasets that it outperforms state-of-the-art models in pose consistency by a large margin, while still reaching competitive MPJPE performance.
WAIT: Feature Warping for Animation to Illustration video Translation using GANs
Oct 07, 2023In this paper, we explore a new domain for video-to-video translation. Motivated by the availability of animation movies that are adopted from illustrated books for children, we aim to stylize these videos with the style of the original illustrations. Current state-of-the-art video-to-video translation models rely on having a video sequence or a single style image to stylize an input video. We introduce a new problem for video stylizing where an unordered set of images are used. This is a challenging task for two reasons: i) we do not have the advantage of temporal consistency as in video sequences; ii) it is more difficult to obtain consistent styles for video frames from a set of unordered images compared to using a single image. Most of the video-to-video translation methods are built on an image-to-image translation model, and integrate additional networks such as optical flow, or temporal predictors to capture temporal relations. These additional networks make the model training and inference complicated and slow down the process. To ensure temporal coherency in video-to-video style transfer, we propose a new generator network with feature warping layers which overcomes the limitations of the previous methods. We show the effectiveness of our method on three datasets both qualitatively and quantitatively. Code and pretrained models are available at https://github.com/giddyyupp/wait.