 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAIT: Feature Warping for Animation to Illustration video Translation using GANs
Oct 07, 2023In this paper, we explore a new domain for video-to-video translation. Motivated by the availability of animation movies that are adopted from illustrated books for children, we aim to stylize these videos with the style of the original illustrations. Current state-of-the-art video-to-video translation models rely on having a video sequence or a single style image to stylize an input video. We introduce a new problem for video stylizing where an unordered set of images are used. This is a challenging task for two reasons: i) we do not have the advantage of temporal consistency as in video sequences; ii) it is more difficult to obtain consistent styles for video frames from a set of unordered images compared to using a single image. Most of the video-to-video translation methods are built on an image-to-image translation model, and integrate additional networks such as optical flow, or temporal predictors to capture temporal relations. These additional networks make the model training and inference complicated and slow down the process. To ensure temporal coherency in video-to-video style transfer, we propose a new generator network with feature warping layers which overcomes the limitations of the previous methods. We show the effectiveness of our method on three datasets both qualitatively and quantitatively. Code and pretrained models are available at https://github.com/giddyyupp/wait.
HybridAugment++: Unified Frequency Spectra Perturbations for Model Robustness
Jul 21, 2023



Convolutional Neural Networks (CNN) are known to exhibit poor generalization performance under distribution shifts. Their generalization have been studied extensively, and one line of work approaches the problem from a frequency-centric perspective. These studies highlight the fact that humans and CNNs might focus on different frequency components of an image. First, inspired by these observations, we propose a simple yet effective data augmentation method HybridAugment that reduces the reliance of CNNs on high-frequency components, and thus improves their robustness while keeping their clean accuracy high. Second, we propose HybridAugment++, which is a hierarchical augmentation method that attempts to unify various frequency-spectrum augmentations. HybridAugment++ builds on HybridAugment, and also reduces the reliance of CNNs on the amplitude component of images, and promotes phase information instead. This unification results in competitive to or better than state-of-the-art results on clean accuracy (CIFAR-10/100 and ImageNet), corruption benchmarks (ImageNet-C, CIFAR-10-C and CIFAR-100-C), adversarial robustness on CIFAR-10 and out-of-distribution detection on various datasets. HybridAugment and HybridAugment++ are implemented in a few lines of code, does not require extra data, ensemble models or additional networks.
Improving Sketch Colorization using Adversarial Segmentation Consistency
Jan 20, 2023We propose a new method for producing color images from sketches. Current solutions in sketch colorization either necessitate additional user instruction or are restricted to the "paired" translation strategy. We leverage semantic image segmentation from a general-purpose panoptic segmentation network to generate an additional adversarial loss function. The proposed loss function is compatible with any GAN model. Our method is not restricted to datasets with segmentation labels and can be applied to unpaired translation tasks as well. Using qualitative, and quantitative analysis, and based on a user study, we demonstrate the efficacy of our method on four distinct image datasets. On the FID metric, our model improves the baseline by up to 35 points. Our code, pretrained models, scripts to produce newly introduced datasets and corresponding sketch images are available at https://github.com/giddyyupp/AdvSegLoss.
How Robust are Discriminatively Trained Zero-Shot Learning Models?
Jan 27, 2022
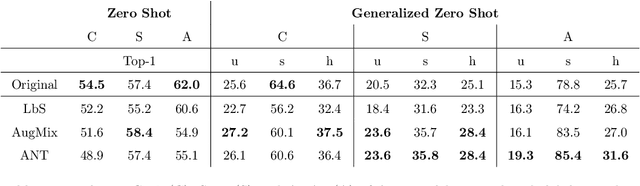
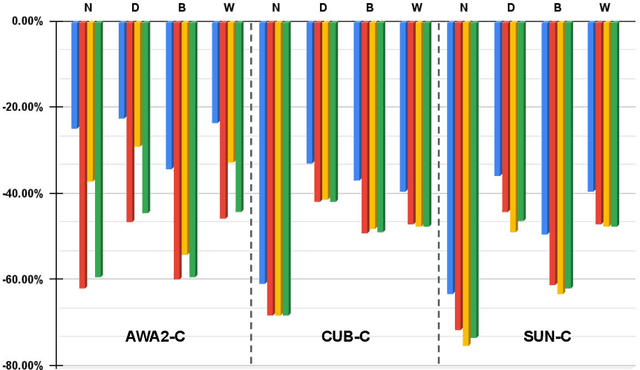
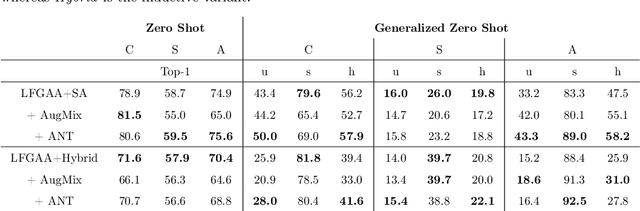
Data shift robustness has been primarily investigated from a fully supervised perspective, and robustness of zero-shot learning (ZSL) models have been largely neglected. In this paper, we present novel analyses on the robustness of discriminative ZSL to image corruptions. We subject several ZSL models to a large set of common corruptions and defenses. In order to realize the corruption analysis, we curate and release the first ZSL corruption robustness datasets SUN-C, CUB-C and AWA2-C. We analyse our results by taking into account the dataset characteristics, class imbalance, class transitions between seen and unseen classes and the discrepancies between ZSL and GZSL performances. Our results show that discriminative ZSL suffers from corruptions and this trend is further exacerbated by the severe class imbalance and model weakness inherent in ZSL methods. We then combine our findings with those based on adversarial attacks in ZSL, and highlight the different effects of corruptions and adversarial examples, such as the pseudo-robustness effect present under adversarial attacks. We also obtain new strong baselines for both models with the defense methods. Finally, our experiments show that although existing methods to improve robustness somewhat work for ZSL models, they do not produce a tangible effect.
Adversarial Segmentation Loss for Sketch Colorization
Feb 11, 2021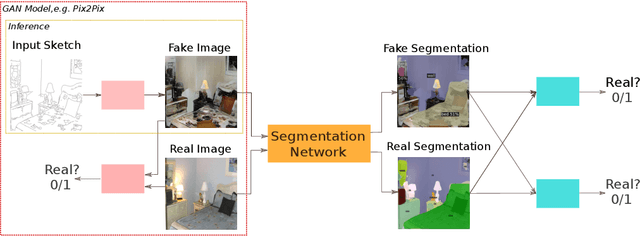


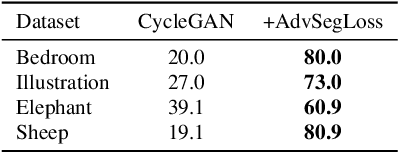
We introduce a new method for generating color images from sketches or edge maps. Current methods either require some form of additional user-guidance or are limited to the "paired" translation approach. We argue that segmentation information could provide valuable guidance for sketch colorization. To this end, we propose to leverage semantic image segmentation, as provided by a general purpose panoptic segmentation network, to create an additional adversarial loss function. Our loss function can be integrated to any baseline GAN model. Our method is not limited to datasets that contain segmentation labels, and it can be trained for "unpaired" translation tasks. We show the effectiveness of our method on four different datasets spanning scene level indoor, outdoor, and children book illustration images using qualitative, quantitative and user study analysis. Our model improves its baseline up to 35 points on the FID metric. Our code and pretrained models can be found at https://github.com/giddyyupp/AdvSegLoss.
Red Carpet to Fight Club: Partially-supervised Domain Transfer for Face Recognition in Violent Videos
Sep 16, 2020
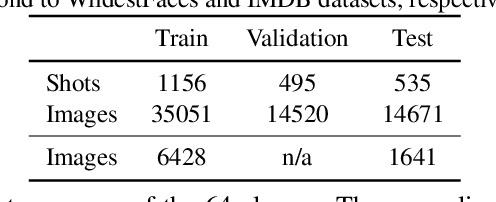
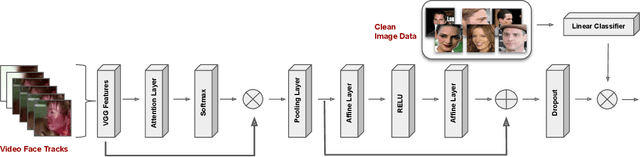
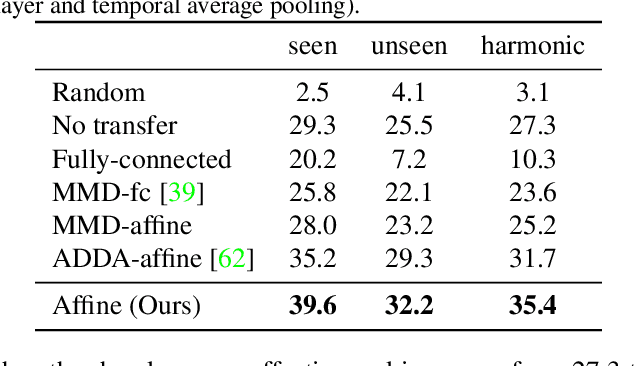
In many real-world problems, there is typically a large discrepancy between the characteristics of data used in training versus deployment. A prime example is the analysis of aggression videos: in a criminal incidence, typically suspects need to be identified based on their clean portrait-like photos, instead of their prior video recordings. This results in three major challenges; large domain discrepancy between violence videos and ID-photos, the lack of video examples for most individuals and limited training data availability. To mimic such scenarios, we formulate a realistic domain-transfer problem, where the goal is to transfer the recognition model trained on clean posed images to the target domain of violent videos, where training videos are available only for a subset of subjects. To this end, we introduce the WildestFaces dataset, tailored to study cross-domain recognition under a variety of adverse conditions. We divide the task of transferring a recognition model from the domain of clean images to the violent videos into two sub-problems and tackle them using (i) stacked affine-transforms for classifier-transfer, (ii) attention-driven pooling for temporal-adaptation. We additionally formulate a self-attention based model for domain-transfer. We establish a rigorous evaluation protocol for this clean-to-violent recognition task, and present a detailed analysis of the proposed dataset and the methods. Our experiments highlight the unique challenges introduced by the WildestFaces dataset and the advantages of the proposed approach.
A Deep Dive into Adversarial Robustness in Zero-Shot Learning
Aug 17, 2020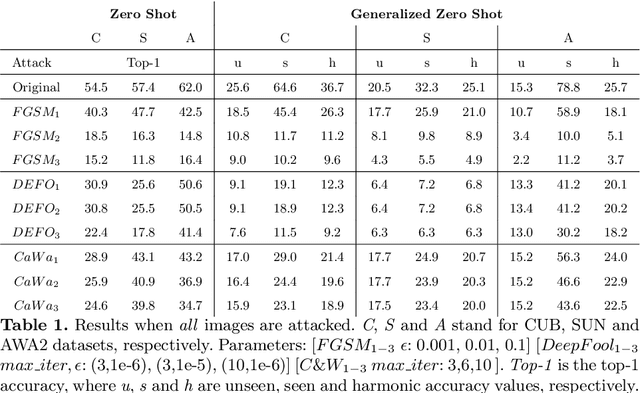


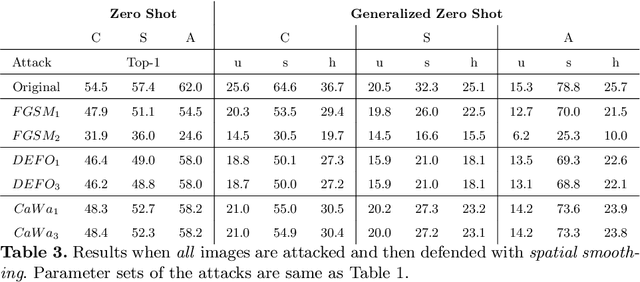
Machine learning (ML) systems have introduced significant advances in various fields, due to the introduction of highly complex models. Despite their success, it has been shown multiple times that machine learning models are prone to imperceptible perturbations that can severely degrade their accuracy. So far, existing studies have primarily focused on models where supervision across all classes were available. In constrast, Zero-shot Learning (ZSL) and Generalized Zero-shot Learning (GZSL) tasks inherently lack supervision across all classes. In this paper, we present a study aimed on evaluating the adversarial robustness of ZSL and GZSL models. We leverage the well-established label embedding model and subject it to a set of established adversarial attacks and defenses across multiple datasets. In addition to creating possibly the first benchmark on adversarial robustness of ZSL models, we also present analyses on important points that require attention for better interpretation of ZSL robustness results. We hope these points, along with the benchmark, will help researchers establish a better understanding what challenges lie ahead and help guide their work.
GANILLA: Generative Adversarial Networks for Image to Illustration Translation
Feb 14, 2020


In this paper, we explore illustrations in children's books as a new domain in unpaired image-to-image translation. We show that although the current state-of-the-art image-to-image translation models successfully transfer either the style or the content, they fail to transfer both at the same time. We propose a new generator network to address this issue and show that the resulting network strikes a better balance between style and content. There are no well-defined or agreed-upon evaluation metrics for unpaired image-to-image translation. So far, the success of image translation models has been based on subjective, qualitative visual comparison on a limited number of images. To address this problem, we propose a new framework for the quantitative evaluation of image-to-illustration models, where both content and style are taken into account using separate classifiers. In this new evaluation framework, our proposed model performs better than the current state-of-the-art models on the illustrations dataset. Our code and pretrained models can be found at https://github.com/giddyyupp/ganilla.
Wildest Faces: Face Detection and Recognition in Violent Settings
May 19, 2018
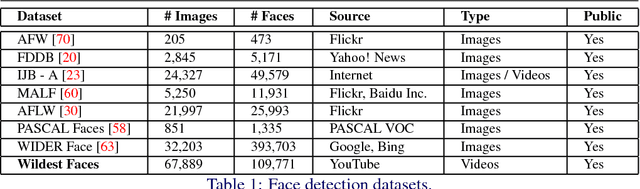
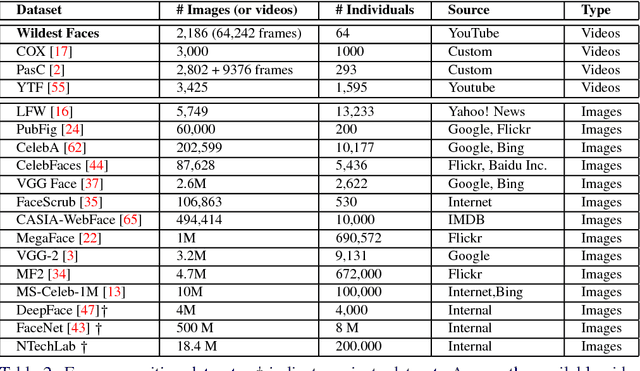

With the introduction of large-scale datasets and deep learning models capable of learning complex representations, impressive advances have emerged in face detection and recognition tasks. Despite such advances, existing datasets do not capture the difficulty of face recognition in the wildest scenarios, such as hostile disputes or fights. Furthermore, existing datasets do not represent completely unconstrained cases of low resolution, high blur and large pose/occlusion variances. To this end, we introduce the Wildest Faces dataset, which focuses on such adverse effects through violent scenes. The dataset consists of an extensive set of violent scenes of celebrities from movies. Our experimental results demonstrate that state-of-the-art techniques are not well-suited for violent scenes, and therefore, Wildest Faces is likely to stir further interest in face detection and recognition research.
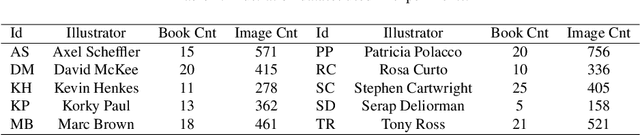
DRAW: Deep networks for Recognizing styles of Artists Who illustrate children's books
Apr 10, 2017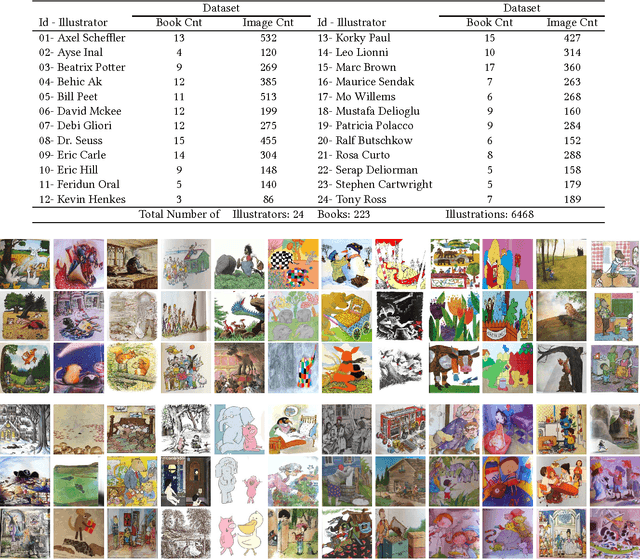
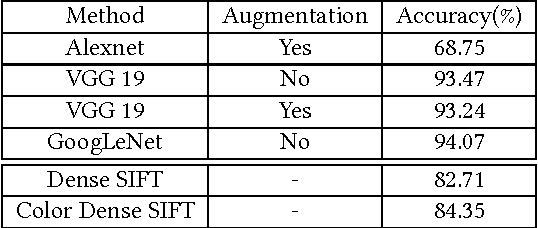
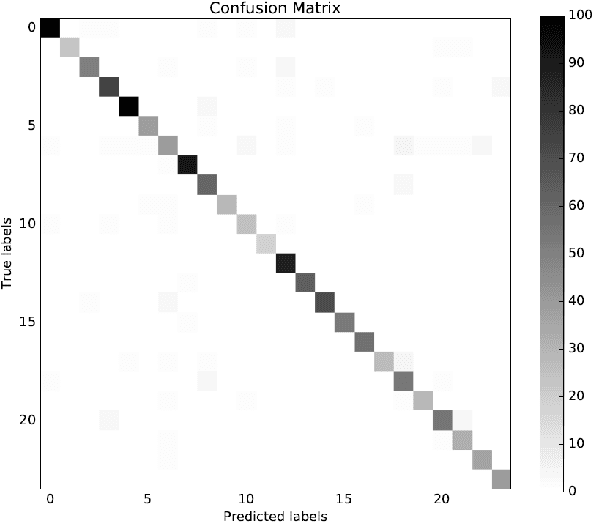
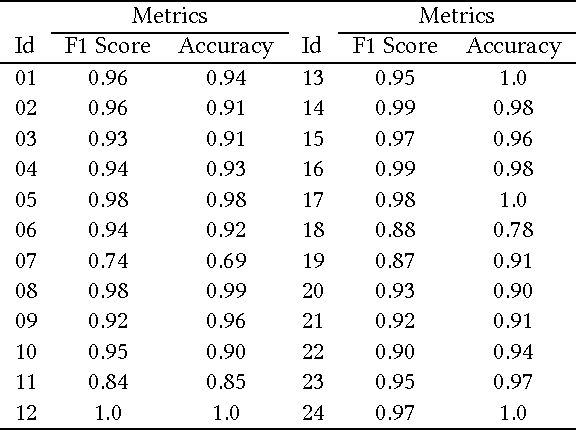
This paper is motivated from a young boy's capability to recognize an illustrator's style in a totally different context. In the book "We are All Born Free" [1], composed of selected rights from the Universal Declaration of Human Rights interpreted by different illustrators, the boy was surprised to see a picture similar to the ones in the "Winnie the Witch" series drawn by Korky Paul (Figure 1). The style was noticeable in other characters of the same illustrator in different books as well. The capability of a child to easily spot the style was shown to be valid for other illustrators such as Axel Scheffler and Debi Gliori. The boy's enthusiasm let us to start the journey to explore the capabilities of machines to recognize the style of illustrators. We collected pages from children's books to construct a new illustrations dataset consisting of about 6500 pages from 24 artists. We exploited deep networks for categorizing illustrators and with around 94% classification performance our method over-performed the traditional methods by more than 10%. Going beyond categorization we explored transferring style. The classification performance on the transferred images has shown the ability of our system to capture the style. Furthermore, we discovered representative illustrations and discriminative stylistic elements.