 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Contrast MRI Segmentation Trained on Synthetic Images
Jul 06, 2022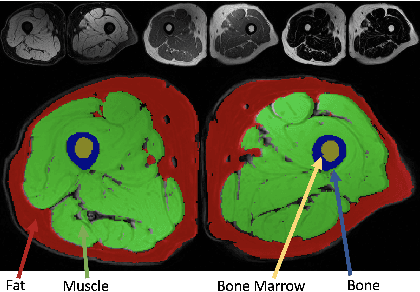
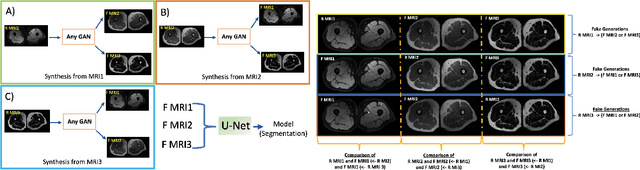
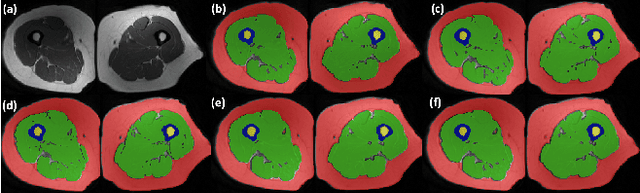
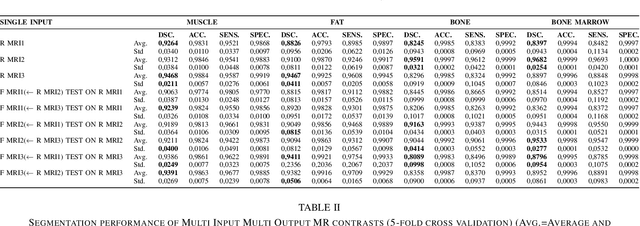
In our comprehensive experiments and evaluations, we show that it is possible to generate multiple contrast (even all synthetically) and use synthetically generated images to train an image segmentation engine. We showed promising segmentation results tested on real multi-contrast MRI scans when delineating muscle, fat, bone and bone marrow, all trained on synthetic images. Based on synthetic image training, our segmentation results were as high as 93.91\%, 94.11\%, 91.63\%, 95.33\%, for muscle, fat, bone, and bone marrow delineation, respectively. Results were not significantly different from the ones obtained when real images were used for segmentation training: 94.68\%, 94.67\%, 95.91\%, and 96.82\%, respectively.
Towards Zero-shot Sign Language Recognition
Jan 15, 2022



This paper tackles the problem of zero-shot sign language recognition (ZSSLR), where the goal is to leverage models learned over the seen sign classes to recognize the instances of unseen sign classes. In this context, readily available textual sign descriptions and attributes collected from sign language dictionaries are utilized as semantic class representations for knowledge transfer. For this novel problem setup, we introduce three benchmark datasets with their accompanying textual and attribute descriptions to analyze the problem in detail. Our proposed approach builds spatiotemporal models of body and hand regions. By leveraging the descriptive text and attribute embeddings along with these visual representations within a zero-shot learning framework, we show that textual and attribute based class definitions can provide effective knowledge for the recognition of previously unseen sign classes. We additionally introduce techniques to analyze the influence of binary attributes in correct and incorrect zero-shot predictions. We anticipate that the introduced approaches and the accompanying datasets will provide a basis for further exploration of zero-shot learning in sign language recognition.
MaskSplit: Self-supervised Meta-learning for Few-shot Semantic Segmentation
Nov 03, 2021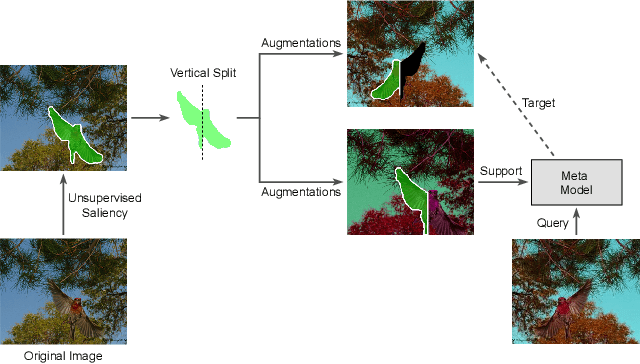


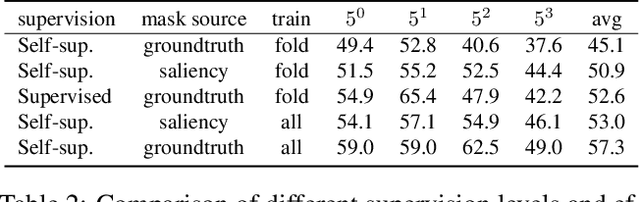
Just like other few-shot learning problems, few-shot segmentation aims to minimize the need for manual annotation, which is particularly costly in segmentation tasks. Even though the few-shot setting reduces this cost for novel test classes, there is still a need to annotate the training data. To alleviate this need, we propose a self-supervised training approach for learning few-shot segmentation models. We first use unsupervised saliency estimation to obtain pseudo-masks on images. We then train a simple prototype based model over different splits of pseudo masks and augmentations of images. Our extensive experiments show that the proposed approach achieves promising results, highlighting the potential of self-supervised training. To the best of our knowledge this is the first work that addresses unsupervised few-shot segmentation problem on natural images.
Red Carpet to Fight Club: Partially-supervised Domain Transfer for Face Recognition in Violent Videos
Sep 16, 2020
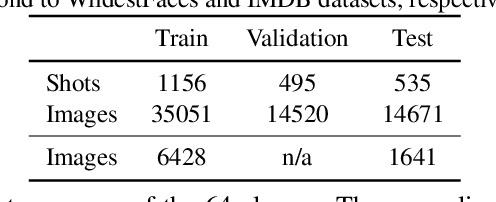
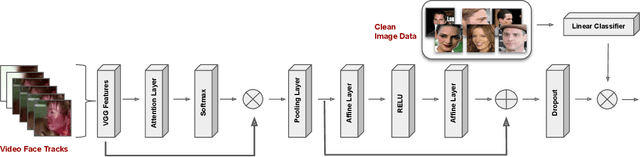
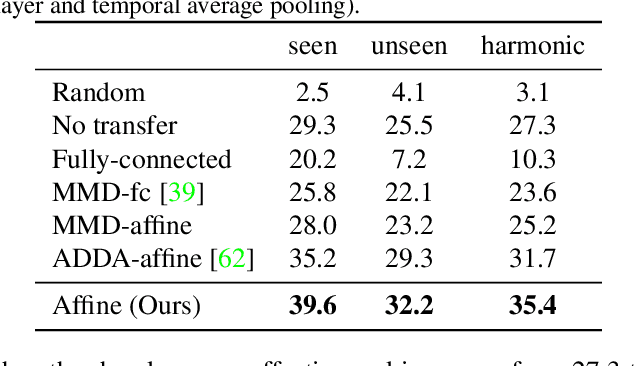
In many real-world problems, there is typically a large discrepancy between the characteristics of data used in training versus deployment. A prime example is the analysis of aggression videos: in a criminal incidence, typically suspects need to be identified based on their clean portrait-like photos, instead of their prior video recordings. This results in three major challenges; large domain discrepancy between violence videos and ID-photos, the lack of video examples for most individuals and limited training data availability. To mimic such scenarios, we formulate a realistic domain-transfer problem, where the goal is to transfer the recognition model trained on clean posed images to the target domain of violent videos, where training videos are available only for a subset of subjects. To this end, we introduce the WildestFaces dataset, tailored to study cross-domain recognition under a variety of adverse conditions. We divide the task of transferring a recognition model from the domain of clean images to the violent videos into two sub-problems and tackle them using (i) stacked affine-transforms for classifier-transfer, (ii) attention-driven pooling for temporal-adaptation. We additionally formulate a self-attention based model for domain-transfer. We establish a rigorous evaluation protocol for this clean-to-violent recognition task, and present a detailed analysis of the proposed dataset and the methods. Our experiments highlight the unique challenges introduced by the WildestFaces dataset and the advantages of the proposed approach.
Image Captioning with Unseen Objects
Jul 31, 2019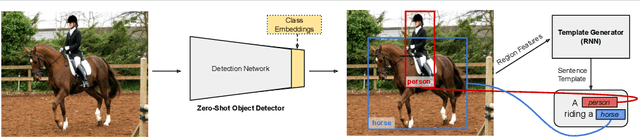

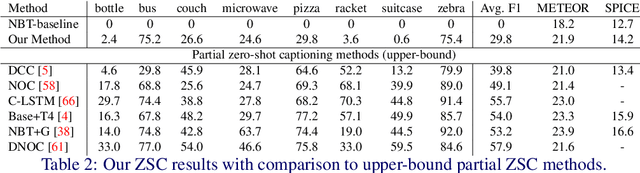

Image caption generation is a long standing and challenging problem at the intersection of computer vision and natural language processing. A number of recently proposed approaches utilize a fully supervised object recognition model within the captioning approach. Such models, however, tend to generate sentences which only consist of objects predicted by the recognition models, excluding instances of the classes without labelled training examples. In this paper, we propose a new challenging scenario that targets the image captioning problem in a fully zero-shot learning setting, where the goal is to be able to generate captions of test images containing objects that are not seen during training. The proposed approach jointly uses a novel zero-shot object detection model and a template-based sentence generator. Our experiments show promising results on the COCO dataset.
Zero-Shot Sign Language Recognition: Can Textual Data Uncover Sign Languages?
Jul 24, 2019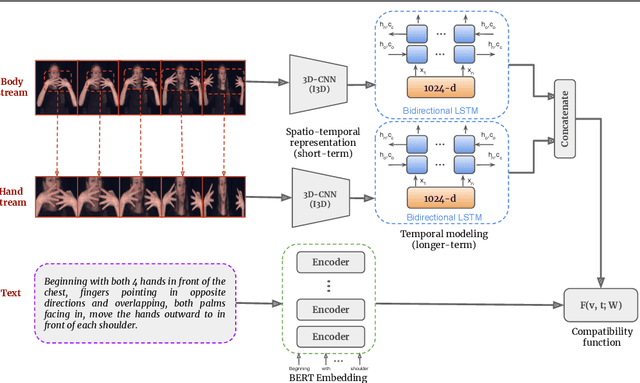
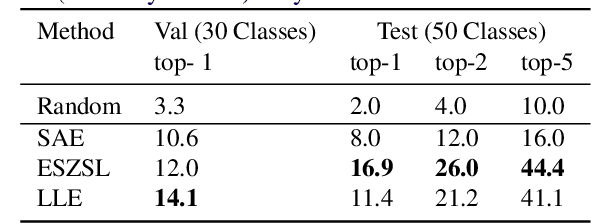


We introduce the problem of zero-shot sign language recognition (ZSSLR), where the goal is to leverage models learned over the seen sign class examples to recognize the instances of unseen signs. To this end, we propose to utilize the readily available descriptions in sign language dictionaries as an intermediate-level semantic representation for knowledge transfer. We introduce a new benchmark dataset called ASL-Text that consists of 250 sign language classes and their accompanying textual descriptions. Compared to the ZSL datasets in other domains (such as object recognition), our dataset consists of limited number of training examples for a large number of classes, which imposes a significant challenge. We propose a framework that operates over the body and hand regions by means of 3D-CNNs, and models longer temporal relationships via bidirectional LSTMs. By leveraging the descriptive text embeddings along with these spatio-temporal representations within a zero-shot learning framework, we show that textual data can indeed be useful in uncovering sign languages. We anticipate that the introduced approach and the accompanying dataset will provide a basis for further exploration of this new zero-shot learning problem.
Learning Visually Consistent Label Embeddings for Zero-Shot Learning
May 16, 2019


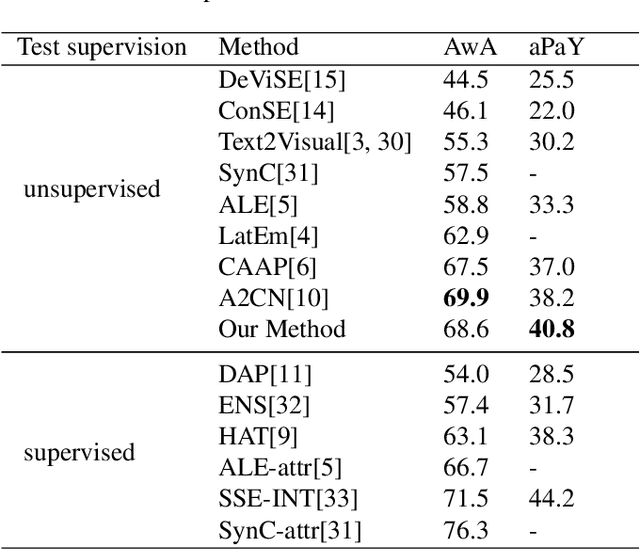
In this work, we propose a zero-shot learning method to effectively model knowledge transfer between classes via jointly learning visually consistent word vectors and label embedding model in an end-to-end manner. The main idea is to project the vector space word vectors of attributes and classes into the visual space such that word representations of semantically related classes become more closer, and use the projected vectors in the proposed embedding model to identify unseen classes. We evaluate the proposed approach on two benchmark datasets and the experimental results show that our method yields significant improvements in recognition accuracy.
RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking Recipes
Sep 04, 2018
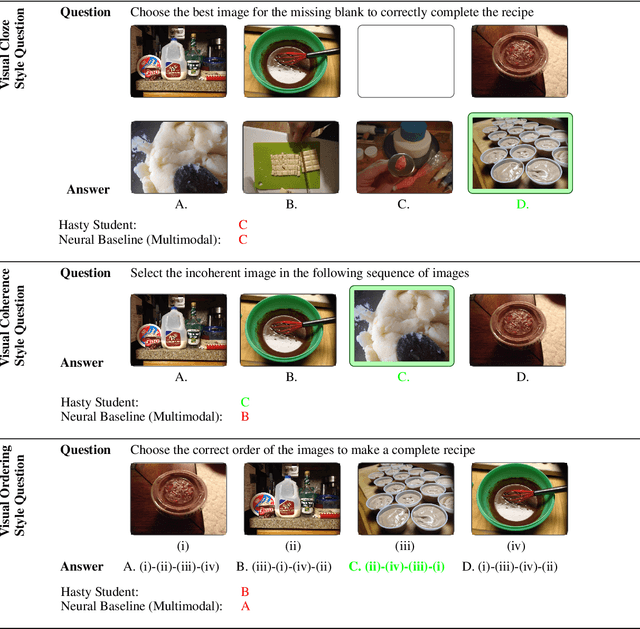
Understanding and reasoning about cooking recipes is a fruitful research direction towards enabling machines to interpret procedural text. In this work, we introduce RecipeQA, a dataset for multimodal comprehension of cooking recipes. It comprises of approximately 20K instructional recipes with multiple modalities such as titles, descriptions and aligned set of images. With over 36K automatically generated question-answer pairs, we design a set of comprehension and reasoning tasks that require joint understanding of images and text, capturing the temporal flow of events and making sense of procedural knowledge. Our preliminary results indicate that RecipeQA will serve as a challenging test bed and an ideal benchmark for evaluating machine comprehension systems. The data and leaderboard are available at http://hucvl.github.io/recipeqa.
Wildest Faces: Face Detection and Recognition in Violent Settings
May 19, 2018
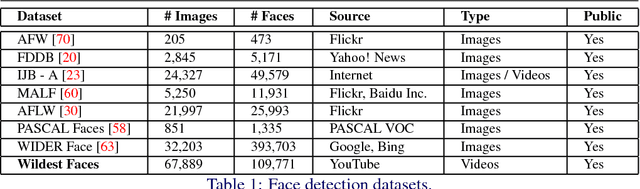
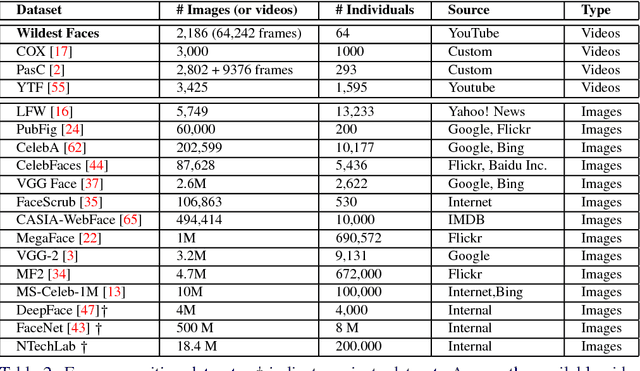

With the introduction of large-scale datasets and deep learning models capable of learning complex representations, impressive advances have emerged in face detection and recognition tasks. Despite such advances, existing datasets do not capture the difficulty of face recognition in the wildest scenarios, such as hostile disputes or fights. Furthermore, existing datasets do not represent completely unconstrained cases of low resolution, high blur and large pose/occlusion variances. To this end, we introduce the Wildest Faces dataset, which focuses on such adverse effects through violent scenes. The dataset consists of an extensive set of violent scenes of celebrities from movies. Our experimental results demonstrate that state-of-the-art techniques are not well-suited for violent scenes, and therefore, Wildest Faces is likely to stir further interest in face detection and recognition research.
Zero-Shot Object Detection by Hybrid Region Embedding
May 17, 2018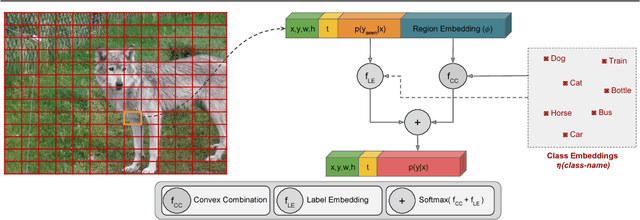

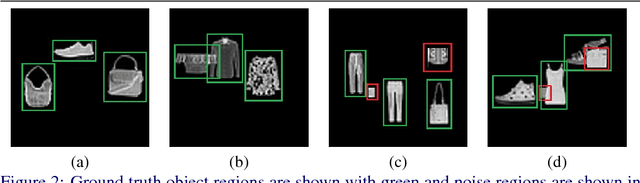
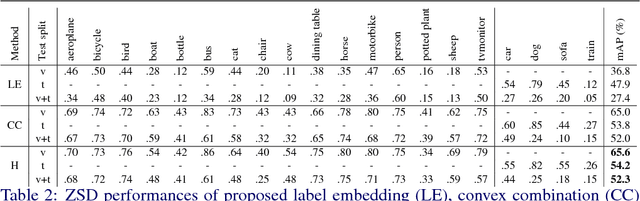
Object detection is considered as one of the most challenging problems in computer vision, since it requires correct prediction of both classes and locations of objects in images. In this study, we define a more difficult scenario, namely zero-shot object detection (ZSD) where no visual training data is available for some of the target object classes. We present a novel approach to tackle this ZSD problem, where a convex combination of embeddings are used in conjunction with a detection framework. For evaluation of ZSD methods, we propose a simple dataset constructed from Fashion-MNIST images and also a custom zero-shot split for the Pascal VOC detection challenge. The experimental results suggest that our method yields promising results for ZSD.