 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Compositional Generalization in Multimodal Models
Apr 18, 2024
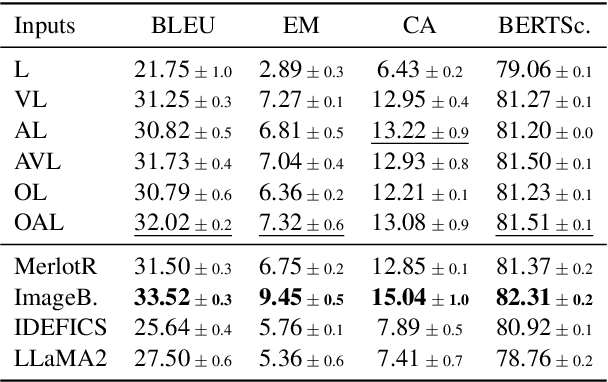
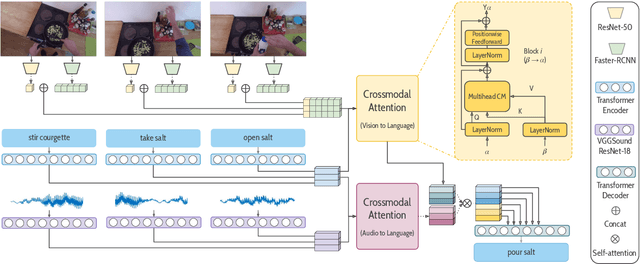
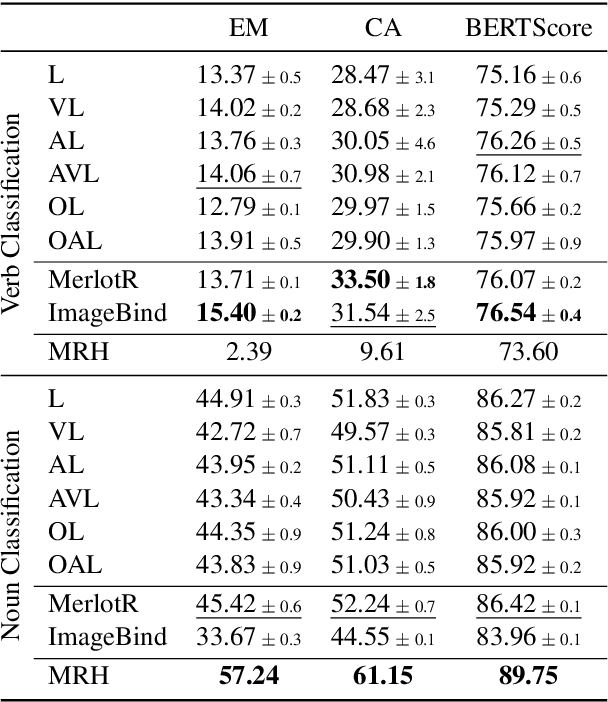
The rise of large-scale multimodal models has paved the pathway for groundbreaking advances in generative modeling and reasoning, unlocking transformative applications in a variety of complex tasks. However, a pressing question that remains is their genuine capability for stronger forms of generalization, which has been largely underexplored in the multimodal setting. Our study aims to address this by examining sequential compositional generalization using \textsc{CompAct} (\underline{Comp}ositional \underline{Act}ivities)\footnote{Project Page: \url{http://cyberiada.github.io/CompAct}}, a carefully constructed, perceptually grounded dataset set within a rich backdrop of egocentric kitchen activity videos. Each instance in our dataset is represented with a combination of raw video footage, naturally occurring sound, and crowd-sourced step-by-step descriptions. More importantly, our setup ensures that the individual concepts are consistently distributed across training and evaluation sets, while their compositions are novel in the evaluation set. We conduct a comprehensive assessment of several unimodal and multimodal models. Our findings reveal that bi-modal and tri-modal models exhibit a clear edge over their text-only counterparts. This highlights the importance of multimodality while charting a trajectory for future research in this domain.
Harnessing Dataset Cartography for Improved Compositional Generalization in Transformers
Oct 18, 2023



Neural networks have revolutionized language modeling and excelled in various downstream tasks. However, the extent to which these models achieve compositional generalization comparable to human cognitive abilities remains a topic of debate. While existing approaches in the field have mainly focused on novel architectures and alternative learning paradigms, we introduce a pioneering method harnessing the power of dataset cartography (Swayamdipta et al., 2020). By strategically identifying a subset of compositional generalization data using this approach, we achieve a remarkable improvement in model accuracy, yielding enhancements of up to 10% on CFQ and COGS datasets. Notably, our technique incorporates dataset cartography as a curriculum learning criterion, eliminating the need for hyperparameter tuning while consistently achieving superior performance. Our findings highlight the untapped potential of dataset cartography in unleashing the full capabilities of compositional generalization within Transformer models. Our code is available at https://github.com/cyberiada/cartography-for-compositionality.
Procedural Reasoning Networks for Understanding Multimodal Procedures
Sep 19, 2019
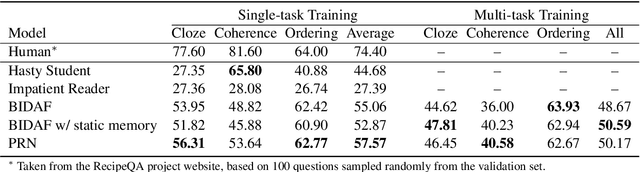
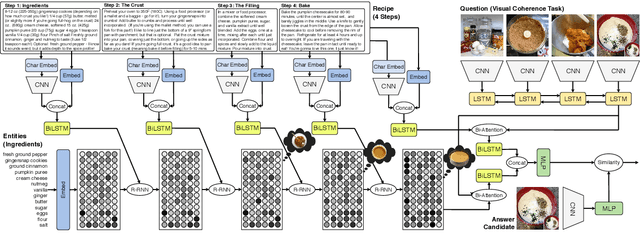
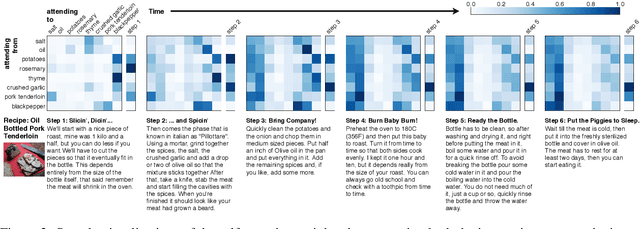
This paper addresses the problem of comprehending procedural commonsense knowledge. This is a challenging task as it requires identifying key entities, keeping track of their state changes, and understanding temporal and causal relations. Contrary to most of the previous work, in this study, we do not rely on strong inductive bias and explore the question of how multimodality can be exploited to provide a complementary semantic signal. Towards this end, we introduce a new entity-aware neural comprehension model augmented with external relational memory units. Our model learns to dynamically update entity states in relation to each other while reading the text instructions. Our experimental analysis on the visual reasoning tasks in the recently proposed RecipeQA dataset reveals that our approach improves the accuracy of the previously reported models by a large margin. Moreover, we find that our model learns effective dynamic representations of entities even though we do not use any supervision at the level of entity states.
Detecting Cybersecurity Events from Noisy Short Text
Apr 10, 2019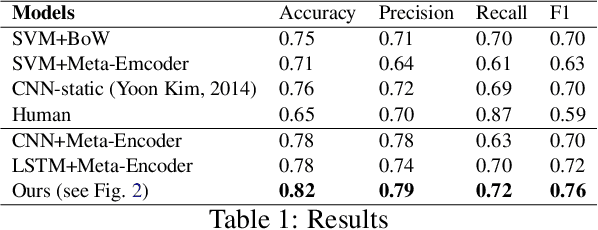
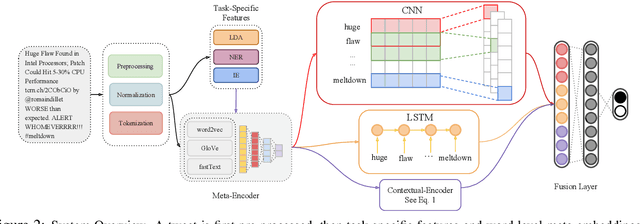

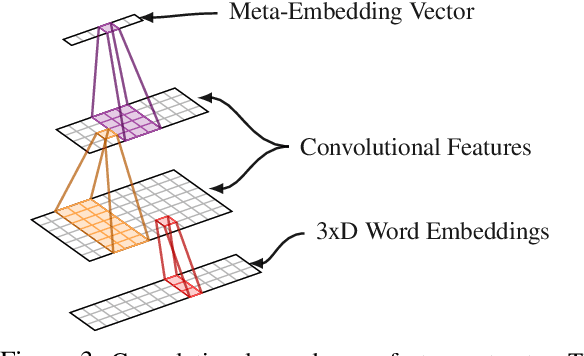
It is very critical to analyze messages shared over social networks for cyber threat intelligence and cyber-crime prevention. In this study, we propose a method that leverages both domain-specific word embeddings and task-specific features to detect cyber security events from tweets. Our model employs a convolutional neural network (CNN) and a long short-term memory (LSTM) recurrent neural network which takes word level meta-embeddings as inputs and incorporates contextual embeddings to classify noisy short text. We collected a new dataset of cyber security related tweets from Twitter and manually annotated a subset of 2K of them. We experimented with this dataset and concluded that the proposed model outperforms both traditional and neural baselines. The results suggest that our method works well for detecting cyber security events from noisy short text.
RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking Recipes
Sep 04, 2018
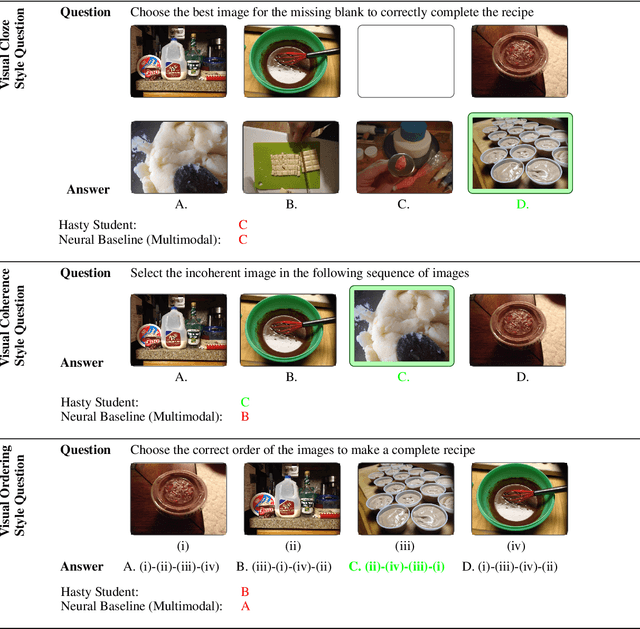
Understanding and reasoning about cooking recipes is a fruitful research direction towards enabling machines to interpret procedural text. In this work, we introduce RecipeQA, a dataset for multimodal comprehension of cooking recipes. It comprises of approximately 20K instructional recipes with multiple modalities such as titles, descriptions and aligned set of images. With over 36K automatically generated question-answer pairs, we design a set of comprehension and reasoning tasks that require joint understanding of images and text, capturing the temporal flow of events and making sense of procedural knowledge. Our preliminary results indicate that RecipeQA will serve as a challenging test bed and an ideal benchmark for evaluating machine comprehension systems. The data and leaderboard are available at http://hucvl.github.io/recipeqa.