 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-tuning Loss Functions and Data Augmentation for Few-shot Object Detection
Apr 24, 2023



Few-shot object detection, the problem of modelling novel object detection categories with few training instances, is an emerging topic in the area of few-shot learning and object detection. Contemporary techniques can be divided into two groups: fine-tuning based and meta-learning based approaches. While meta-learning approaches aim to learn dedicated meta-models for mapping samples to novel class models, fine-tuning approaches tackle few-shot detection in a simpler manner, by adapting the detection model to novel classes through gradient based optimization. Despite their simplicity, fine-tuning based approaches typically yield competitive detection results. Based on this observation, we focus on the role of loss functions and augmentations as the force driving the fine-tuning process, and propose to tune their dynamics through meta-learning principles. The proposed training scheme, therefore, allows learning inductive biases that can boost few-shot detection, while keeping the advantages of fine-tuning based approaches. In addition, the proposed approach yields interpretable loss functions, as opposed to highly parametric and complex few-shot meta-models. The experimental results highlight the merits of the proposed scheme, with significant improvements over the strong fine-tuning based few-shot detection baselines on benchmark Pascal VOC and MS-COCO datasets, in terms of both standard and generalized few-shot performance metrics.
Detection and Captioning with Unseen Object Classes
Aug 13, 2021
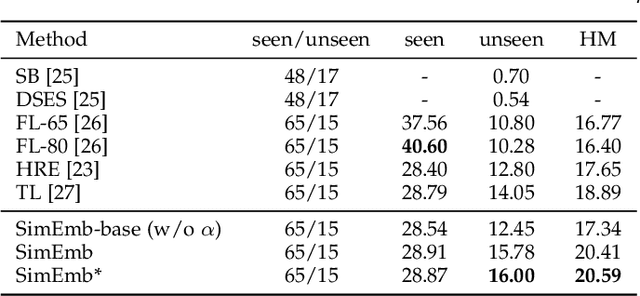
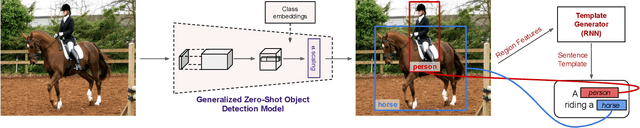
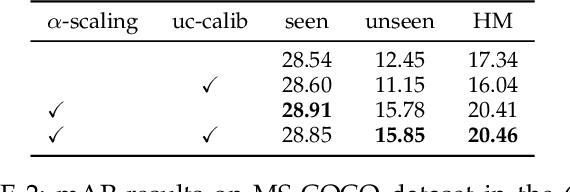
Image caption generation is one of the most challenging problems at the intersection of visual recognition and natural language modeling domains. In this work, we propose and study a practically important variant of this problem where test images may contain visual objects with no corresponding visual or textual training examples. For this problem, we propose a detection-driven approach based on a generalized zero-shot detection model and a template-based sentence generation model. In order to improve the detection component, we jointly define a class-to-class similarity based class representation and a practical score calibration mechanism. We also propose a novel evaluation metric that provides complimentary insights to the captioning outputs, by separately handling the visual and non-visual components of the captions. Our experiments show that the proposed zero-shot detection model obtains state-of-the-art performance on the MS-COCO dataset and the zero-shot captioning approach yields promising results.
Image Captioning with Unseen Objects
Jul 31, 2019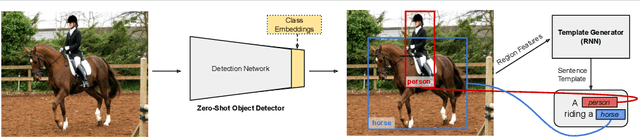

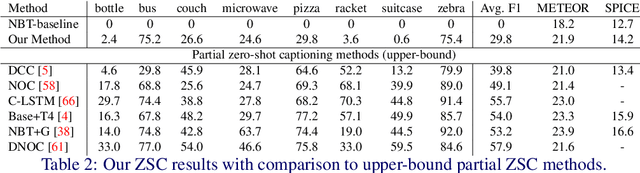

Image caption generation is a long standing and challenging problem at the intersection of computer vision and natural language processing. A number of recently proposed approaches utilize a fully supervised object recognition model within the captioning approach. Such models, however, tend to generate sentences which only consist of objects predicted by the recognition models, excluding instances of the classes without labelled training examples. In this paper, we propose a new challenging scenario that targets the image captioning problem in a fully zero-shot learning setting, where the goal is to be able to generate captions of test images containing objects that are not seen during training. The proposed approach jointly uses a novel zero-shot object detection model and a template-based sentence generator. Our experiments show promising results on the COCO dataset.
Segmentation-Aware Hyperspectral Image Classification
May 22, 2019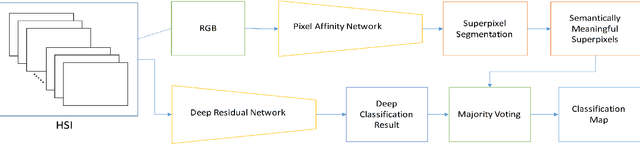


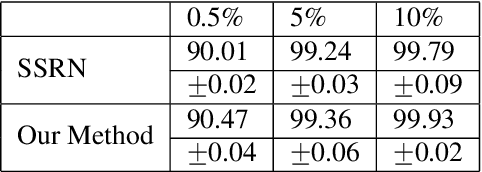
In this paper, we propose an unified hyperspectral image classification method which takes three-dimensional hyperspectral data cube as an input and produces a classification map. In the proposed method, a deep neural network which uses spectral and spatial information together with residual connections, and pixel affinity network based segmentation-aware superpixels are used together. In the architecture, segmentation-aware superpixels run on the initial classification map of deep residual network, and apply majority voting on obtained results. Experimental results show that our propoped method yields state-of-the-art results in two benchmark datasets. Moreover, we also show that the segmentation-aware superpixels have great contribution to the success of hyperspectral image classification methods in cases where training data is insufficient.
Learning Visually Consistent Label Embeddings for Zero-Shot Learning
May 16, 2019


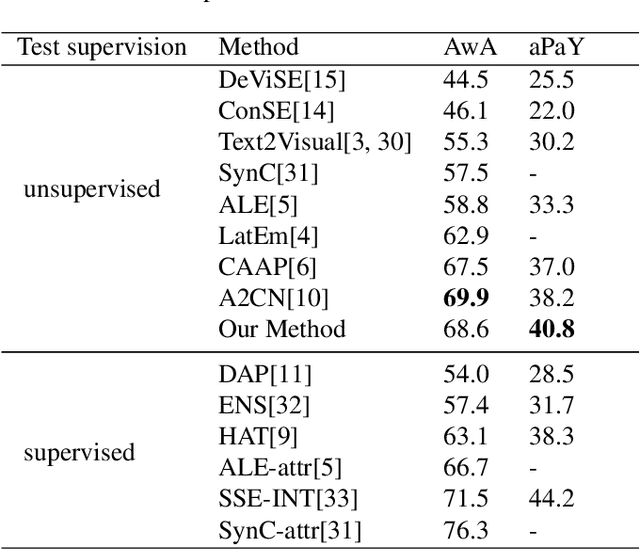
In this work, we propose a zero-shot learning method to effectively model knowledge transfer between classes via jointly learning visually consistent word vectors and label embedding model in an end-to-end manner. The main idea is to project the vector space word vectors of attributes and classes into the visual space such that word representations of semantically related classes become more closer, and use the projected vectors in the proposed embedding model to identify unseen classes. We evaluate the proposed approach on two benchmark datasets and the experimental results show that our method yields significant improvements in recognition accuracy.
Zero-Shot Object Detection by Hybrid Region Embedding
May 17, 2018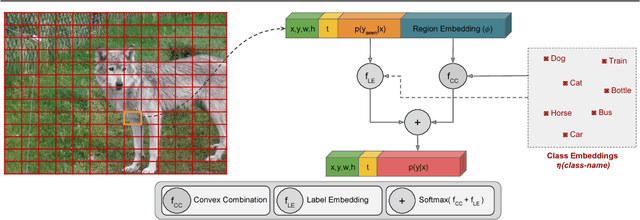

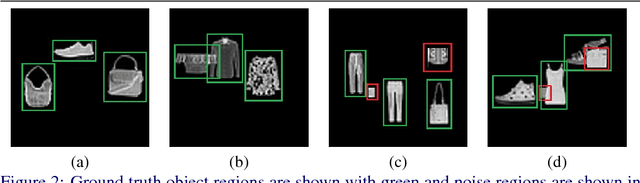
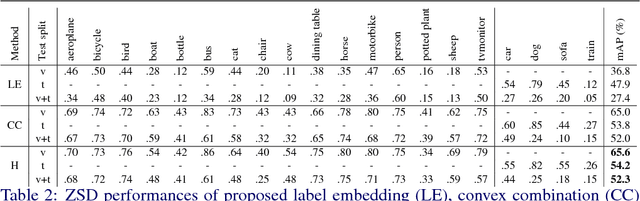
Object detection is considered as one of the most challenging problems in computer vision, since it requires correct prediction of both classes and locations of objects in images. In this study, we define a more difficult scenario, namely zero-shot object detection (ZSD) where no visual training data is available for some of the target object classes. We present a novel approach to tackle this ZSD problem, where a convex combination of embeddings are used in conjunction with a detection framework. For evaluation of ZSD methods, we propose a simple dataset constructed from Fashion-MNIST images and also a custom zero-shot split for the Pascal VOC detection challenge. The experimental results suggest that our method yields promising results for ZSD.
Attributes2Classname: A discriminative model for attribute-based unsupervised zero-shot learning
Aug 05, 2017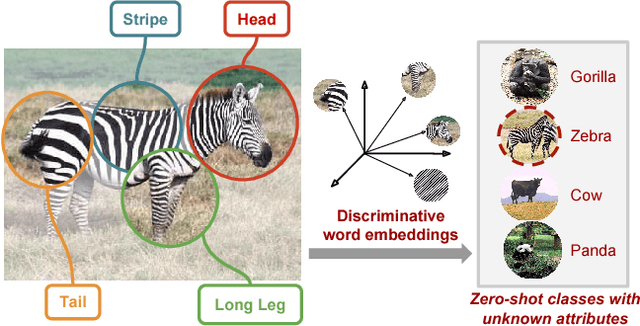
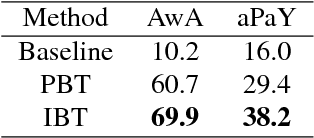
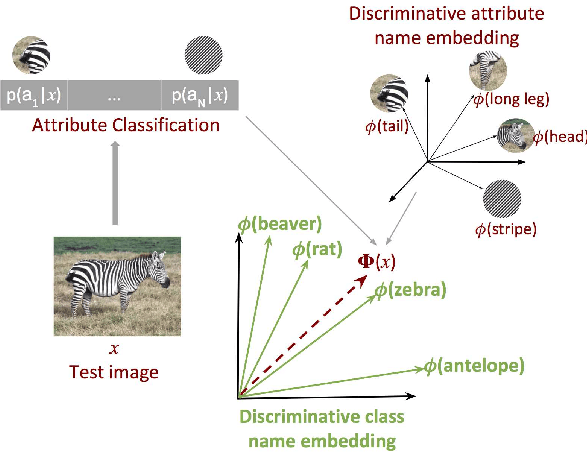
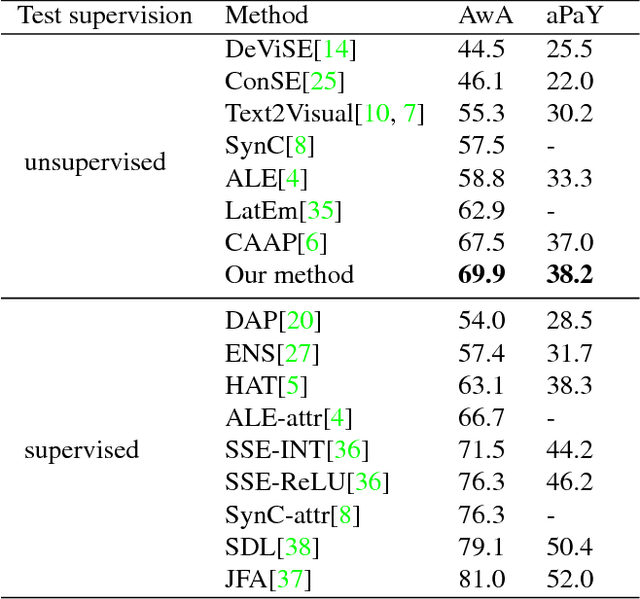
We propose a novel approach for unsupervised zero-shot learning (ZSL) of classes based on their names. Most existing unsupervised ZSL methods aim to learn a model for directly comparing image features and class names. However, this proves to be a difficult task due to dominance of non-visual semantics in underlying vector-space embeddings of class names. To address this issue, we discriminatively learn a word representation such that the similarities between class and combination of attribute names fall in line with the visual similarity. Contrary to the traditional zero-shot learning approaches that are built upon attribute presence, our approach bypasses the laborious attribute-class relation annotations for unseen classes. In addition, our proposed approach renders text-only training possible, hence, the training can be augmented without the need to collect additional image data. The experimental results show that our method yields state-of-the-art results for unsupervised ZSL in three benchmark datasets.