 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Captioning with Unseen Object Classes
Paper and Code
Aug 13, 2021
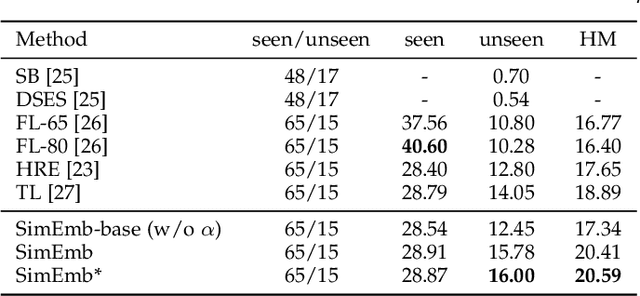
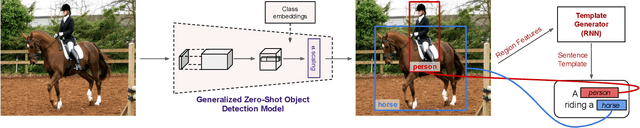
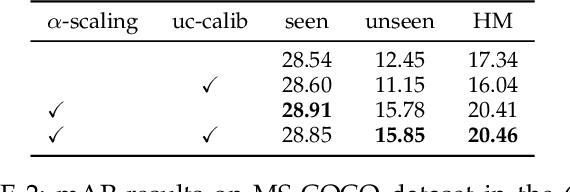
Image caption generation is one of the most challenging problems at the intersection of visual recognition and natural language modeling domains. In this work, we propose and study a practically important variant of this problem where test images may contain visual objects with no corresponding visual or textual training examples. For this problem, we propose a detection-driven approach based on a generalized zero-shot detection model and a template-based sentence generation model. In order to improve the detection component, we jointly define a class-to-class similarity based class representation and a practical score calibration mechanism. We also propose a novel evaluation metric that provides complimentary insights to the captioning outputs, by separately handling the visual and non-visual components of the captions. Our experiments show that the proposed zero-shot detection model obtains state-of-the-art performance on the MS-COCO dataset and the zero-shot captioning approach yields promising results.