 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-LoRA: Meta-Learning LoRA Components for Domain-Aware ID Personalization
Mar 28, 2025Recent advancements in text-to-image generative models, particularly latent diffusion models (LDMs), have demonstrated remarkable capabilities in synthesizing high-quality images from textual prompts. However, achieving identity personalization-ensuring that a model consistently generates subject-specific outputs from limited reference images-remains a fundamental challenge. To address this, we introduce Meta-Low-Rank Adaptation (Meta-LoRA), a novel framework that leverages meta-learning to encode domain-specific priors into LoRA-based identity personalization. Our method introduces a structured three-layer LoRA architecture that separates identity-agnostic knowledge from identity-specific adaptation. In the first stage, the LoRA Meta-Down layers are meta-trained across multiple subjects, learning a shared manifold that captures general identity-related features. In the second stage, only the LoRA-Mid and LoRA-Up layers are optimized to specialize on a given subject, significantly reducing adaptation time while improving identity fidelity. To evaluate our approach, we introduce Meta-PHD, a new benchmark dataset for identity personalization, and compare Meta-LoRA against state-of-the-art methods. Our results demonstrate that Meta-LoRA achieves superior identity retention, computational efficiency, and adaptability across diverse identity conditions. The code, model weights, and dataset will be released publicly upon acceptance.
Interchangeable Token Embeddings for Extendable Vocabulary and Alpha-Equivalence
Oct 22, 2024



We propose a novel approach for learning interchangeable tokens in language models to obtain an extendable vocabulary that can generalize to new tokens. Our method is designed to address alpha-equivalence, the principle that renaming bound variables in a syntactic expression preserves semantics. This property arises in many formal languages such as temporal logics, in which all proposition symbols represent the same concept but are distinguishable from each other. To handle such tokens, we develop a dual-part embedding approach. The first part is shared across all interchangeable tokens, thereby enforcing that they represent the same core concept. The second part is randomly generated for each token, which enables distinguishability. We evaluate our method in a Transformer encoder-decoder model on two tasks: solving linear temporal logic formulae and copying with extendable vocabulary. Our method demonstrates promising generalization capabilities in addition to introducing a favorable inductive bias for alpha-equivalence.
Learning to Estimate System Specifications in Linear Temporal Logic using Transformers and Mamba
May 31, 2024



Temporal logic is a framework for representing and reasoning about propositions that evolve over time. It is commonly used for specifying requirements in various domains, including hardware and software systems, as well as robotics. Specification mining or formula generation involves extracting temporal logic formulae from system traces and has numerous applications, such as detecting bugs and improving interpretability. Although there has been a surge of deep learning-based methods for temporal logic satisfiability checking in recent years, the specification mining literature has been lagging behind in adopting deep learning methods despite their many advantages, such as scalability. In this paper, we introduce autoregressive models that can generate linear temporal logic formulae from traces, towards addressing the specification mining problem. We propose multiple architectures for this task: transformer encoder-decoder, decoder-only transformer, and Mamba, which is an emerging alternative to transformer models. Additionally, we devise a metric for quantifying the distinctiveness of the generated formulae and a straightforward algorithm to enforce the syntax constraints. Our experiments show that the proposed architectures yield promising results, generating correct and distinct formulae at a fraction of the compute cost needed for the combinatorial baseline.
HybridAugment++: Unified Frequency Spectra Perturbations for Model Robustness
Jul 21, 2023



Convolutional Neural Networks (CNN) are known to exhibit poor generalization performance under distribution shifts. Their generalization have been studied extensively, and one line of work approaches the problem from a frequency-centric perspective. These studies highlight the fact that humans and CNNs might focus on different frequency components of an image. First, inspired by these observations, we propose a simple yet effective data augmentation method HybridAugment that reduces the reliance of CNNs on high-frequency components, and thus improves their robustness while keeping their clean accuracy high. Second, we propose HybridAugment++, which is a hierarchical augmentation method that attempts to unify various frequency-spectrum augmentations. HybridAugment++ builds on HybridAugment, and also reduces the reliance of CNNs on the amplitude component of images, and promotes phase information instead. This unification results in competitive to or better than state-of-the-art results on clean accuracy (CIFAR-10/100 and ImageNet), corruption benchmarks (ImageNet-C, CIFAR-10-C and CIFAR-100-C), adversarial robustness on CIFAR-10 and out-of-distribution detection on various datasets. HybridAugment and HybridAugment++ are implemented in a few lines of code, does not require extra data, ensemble models or additional networks.
VISION Datasets: A Benchmark for Vision-based InduStrial InspectiON
Jun 18, 2023Despite progress in vision-based inspection algorithms, real-world industrial challenges -- specifically in data availability, quality, and complex production requirements -- often remain under-addressed. We introduce the VISION Datasets, a diverse collection of 14 industrial inspection datasets, uniquely poised to meet these challenges. Unlike previous datasets, VISION brings versatility to defect detection, offering annotation masks across all splits and catering to various detection methodologies. Our datasets also feature instance-segmentation annotation, enabling precise defect identification. With a total of 18k images encompassing 44 defect types, VISION strives to mirror a wide range of real-world production scenarios. By supporting two ongoing challenge competitions on the VISION Datasets, we hope to foster further advancements in vision-based industrial inspection.
Meta-tuning Loss Functions and Data Augmentation for Few-shot Object Detection
Apr 24, 2023



Few-shot object detection, the problem of modelling novel object detection categories with few training instances, is an emerging topic in the area of few-shot learning and object detection. Contemporary techniques can be divided into two groups: fine-tuning based and meta-learning based approaches. While meta-learning approaches aim to learn dedicated meta-models for mapping samples to novel class models, fine-tuning approaches tackle few-shot detection in a simpler manner, by adapting the detection model to novel classes through gradient based optimization. Despite their simplicity, fine-tuning based approaches typically yield competitive detection results. Based on this observation, we focus on the role of loss functions and augmentations as the force driving the fine-tuning process, and propose to tune their dynamics through meta-learning principles. The proposed training scheme, therefore, allows learning inductive biases that can boost few-shot detection, while keeping the advantages of fine-tuning based approaches. In addition, the proposed approach yields interpretable loss functions, as opposed to highly parametric and complex few-shot meta-models. The experimental results highlight the merits of the proposed scheme, with significant improvements over the strong fine-tuning based few-shot detection baselines on benchmark Pascal VOC and MS-COCO datasets, in terms of both standard and generalized few-shot performance metrics.
Streaming Multiscale Deep Equilibrium Models
Apr 28, 2022
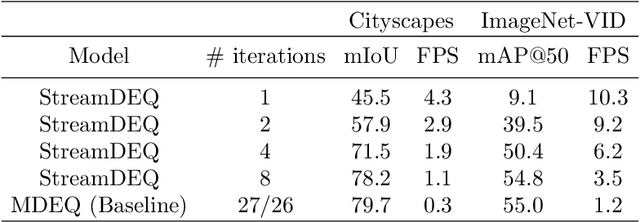
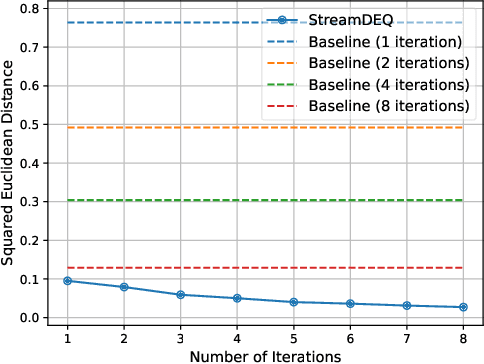
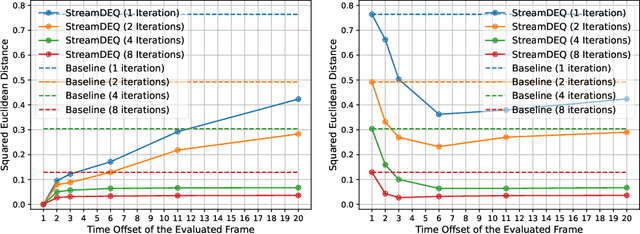
We present StreamDEQ, a method that infers frame-wise representations on videos with minimal per-frame computation. In contrast to conventional methods where compute time grows at least linearly with the network depth, we aim to update the representations in a continuous manner. For this purpose, we leverage the recently emerging implicit layer model which infers the representation of an image by solving a fixed-point problem. Our main insight is to leverage the slowly changing nature of videos and use the previous frame representation as an initial condition on each frame. This scheme effectively recycles the recent inference computations and greatly reduces the needed processing time. Through extensive experimental analysis, we show that StreamDEQ is able to recover near-optimal representations in a few frames time, and maintain an up-to-date representation throughout the video duration. Our experiments on video semantic segmentation and video object detection show that StreamDEQ achieves on par accuracy with the baseline (standard MDEQ) while being more than $3\times$ faster. The project page is available at: https://ufukertenli.github.io/streamdeq/
How Robust are Discriminatively Trained Zero-Shot Learning Models?
Jan 27, 2022
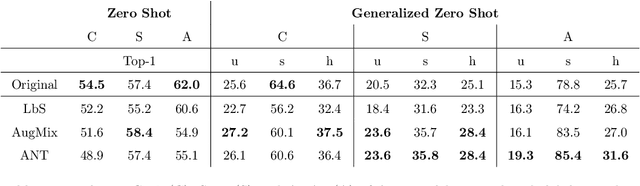
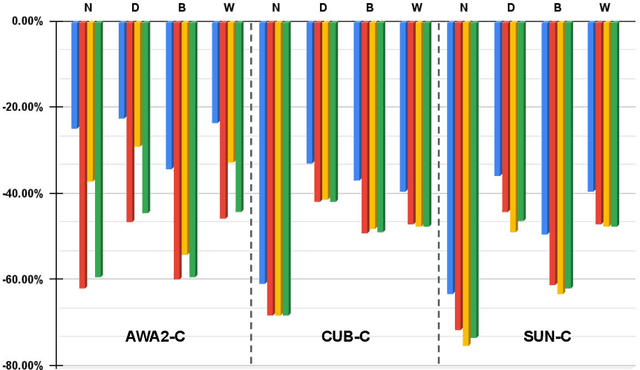
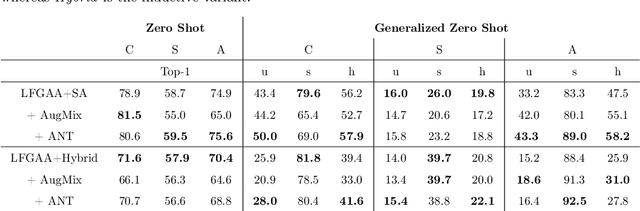
Data shift robustness has been primarily investigated from a fully supervised perspective, and robustness of zero-shot learning (ZSL) models have been largely neglected. In this paper, we present novel analyses on the robustness of discriminative ZSL to image corruptions. We subject several ZSL models to a large set of common corruptions and defenses. In order to realize the corruption analysis, we curate and release the first ZSL corruption robustness datasets SUN-C, CUB-C and AWA2-C. We analyse our results by taking into account the dataset characteristics, class imbalance, class transitions between seen and unseen classes and the discrepancies between ZSL and GZSL performances. Our results show that discriminative ZSL suffers from corruptions and this trend is further exacerbated by the severe class imbalance and model weakness inherent in ZSL methods. We then combine our findings with those based on adversarial attacks in ZSL, and highlight the different effects of corruptions and adversarial examples, such as the pseudo-robustness effect present under adversarial attacks. We also obtain new strong baselines for both models with the defense methods. Finally, our experiments show that although existing methods to improve robustness somewhat work for ZSL models, they do not produce a tangible effect.
Towards Zero-shot Sign Language Recognition
Jan 15, 2022



This paper tackles the problem of zero-shot sign language recognition (ZSSLR), where the goal is to leverage models learned over the seen sign classes to recognize the instances of unseen sign classes. In this context, readily available textual sign descriptions and attributes collected from sign language dictionaries are utilized as semantic class representations for knowledge transfer. For this novel problem setup, we introduce three benchmark datasets with their accompanying textual and attribute descriptions to analyze the problem in detail. Our proposed approach builds spatiotemporal models of body and hand regions. By leveraging the descriptive text and attribute embeddings along with these visual representations within a zero-shot learning framework, we show that textual and attribute based class definitions can provide effective knowledge for the recognition of previously unseen sign classes. We additionally introduce techniques to analyze the influence of binary attributes in correct and incorrect zero-shot predictions. We anticipate that the introduced approaches and the accompanying datasets will provide a basis for further exploration of zero-shot learning in sign language recognition.
MaskSplit: Self-supervised Meta-learning for Few-shot Semantic Segmentation
Nov 03, 2021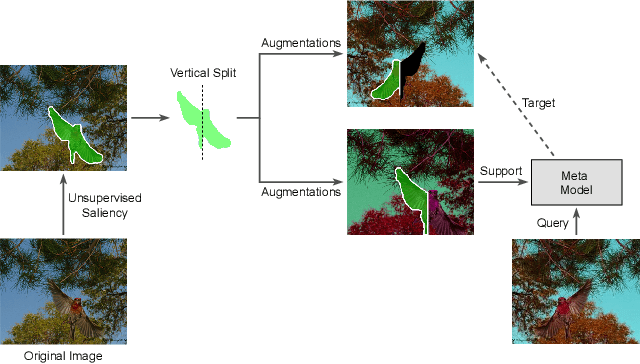


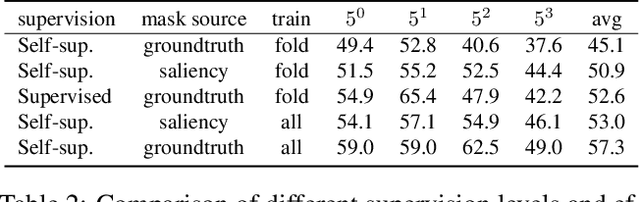
Just like other few-shot learning problems, few-shot segmentation aims to minimize the need for manual annotation, which is particularly costly in segmentation tasks. Even though the few-shot setting reduces this cost for novel test classes, there is still a need to annotate the training data. To alleviate this need, we propose a self-supervised training approach for learning few-shot segmentation models. We first use unsupervised saliency estimation to obtain pseudo-masks on images. We then train a simple prototype based model over different splits of pseudo masks and augmentations of images. Our extensive experiments show that the proposed approach achieves promising results, highlighting the potential of self-supervised training. To the best of our knowledge this is the first work that addresses unsupervised few-shot segmentation problem on natural images.