 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynth4Seg -- Learning Defect Data Synthesis for Defect Segmentation using Bi-level Optimization
Oct 24, 2024Defect segmentation is crucial for quality control in advanced manufacturing, yet data scarcity poses challenges for state-of-the-art supervised deep learning. Synthetic defect data generation is a popular approach for mitigating data challenges. However, many current methods simply generate defects following a fixed set of rules, which may not directly relate to downstream task performance. This can lead to suboptimal performance and may even hinder the downstream task. To solve this problem, we leverage a novel bi-level optimization-based synthetic defect data generation framework. We use an online synthetic defect generation module grounded in the commonly-used Cut\&Paste framework, and adopt an efficient gradient-based optimization algorithm to solve the bi-level optimization problem. We achieve simultaneous training of the defect segmentation network, and learn various parameters of the data synthesis module by maximizing the validation performance of the trained defect segmentation network. Our experimental results on benchmark datasets under limited data settings show that the proposed bi-level optimization method can be used for learning the most effective locations for pasting synthetic defects thereby improving the segmentation performance by up to 18.3\% when compared to pasting defects at random locations. We also demonstrate up to 2.6\% performance gain by learning the importance weights for different augmentation-specific defect data sources when compared to giving equal importance to all the data sources.
VISION Datasets: A Benchmark for Vision-based InduStrial InspectiON
Jun 18, 2023Despite progress in vision-based inspection algorithms, real-world industrial challenges -- specifically in data availability, quality, and complex production requirements -- often remain under-addressed. We introduce the VISION Datasets, a diverse collection of 14 industrial inspection datasets, uniquely poised to meet these challenges. Unlike previous datasets, VISION brings versatility to defect detection, offering annotation masks across all splits and catering to various detection methodologies. Our datasets also feature instance-segmentation annotation, enabling precise defect identification. With a total of 18k images encompassing 44 defect types, VISION strives to mirror a wide range of real-world production scenarios. By supporting two ongoing challenge competitions on the VISION Datasets, we hope to foster further advancements in vision-based industrial inspection.
RGI: robust GAN-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection
Feb 24, 2023



Generative adversarial networks (GANs), trained on a large-scale image dataset, can be a good approximator of the natural image manifold. GAN-inversion, using a pre-trained generator as a deep generative prior, is a promising tool for image restoration under corruptions. However, the performance of GAN-inversion can be limited by a lack of robustness to unknown gross corruptions, i.e., the restored image might easily deviate from the ground truth. In this paper, we propose a Robust GAN-inversion (RGI) method with a provable robustness guarantee to achieve image restoration under unknown \textit{gross} corruptions, where a small fraction of pixels are completely corrupted. Under mild assumptions, we show that the restored image and the identified corrupted region mask converge asymptotically to the ground truth. Moreover, we extend RGI to Relaxed-RGI (R-RGI) for generator fine-tuning to mitigate the gap between the GAN learned manifold and the true image manifold while avoiding trivial overfitting to the corrupted input image, which further improves the image restoration and corrupted region mask identification performance. The proposed RGI/R-RGI method unifies two important applications with state-of-the-art (SOTA) performance: (i) mask-free semantic inpainting, where the corruptions are unknown missing regions, the restored background can be used to restore the missing content; (ii) unsupervised pixel-wise anomaly detection, where the corruptions are unknown anomalous regions, the retrieved mask can be used as the anomalous region's segmentation mask.
PAEDID: Patch Autoencoder Based Deep Image Decomposition For Pixel-level Defective Region Segmentation
Apr 11, 2022
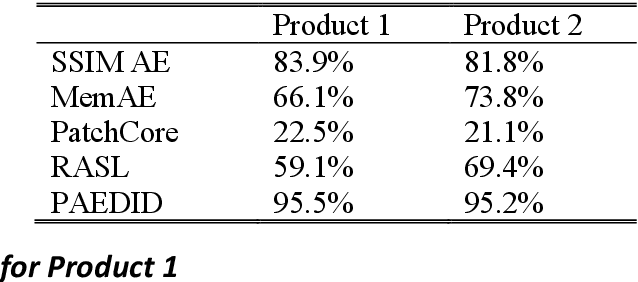

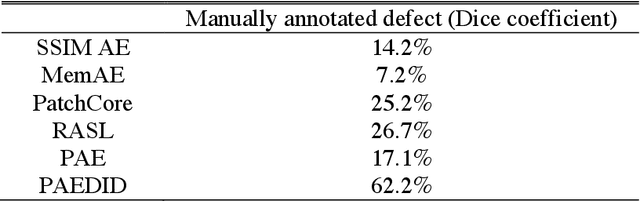
Unsupervised pixel-level defective region segmentation is an important task in image-based anomaly detection for various industrial applications. The state-of-the-art methods have their own advantages and limitations: matrix-decomposition-based methods are robust to noise but lack complex background image modeling capability; representation-based methods are good at defective region localization but lack accuracy in defective region shape contour extraction; reconstruction-based methods detected defective region match well with the ground truth defective region shape contour but are noisy. To combine the best of both worlds, we present an unsupervised patch autoencoder based deep image decomposition (PAEDID) method for defective region segmentation. In the training stage, we learn the common background as a deep image prior by a patch autoencoder (PAE) network. In the inference stage, we formulate anomaly detection as an image decomposition problem with the deep image prior and domain-specific regularizations. By adopting the proposed approach, the defective regions in the image can be accurately extracted in an unsupervised fashion. We demonstrate the effectiveness of the PAEDID method in simulation studies and an industrial dataset in the case study.
Synthetic Defect Generation for Display Front-of-Screen Quality Inspection: A Survey
Mar 03, 2022
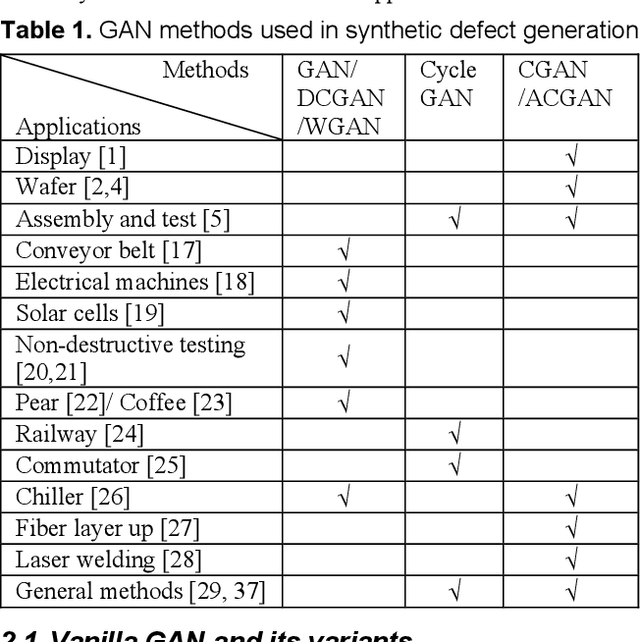

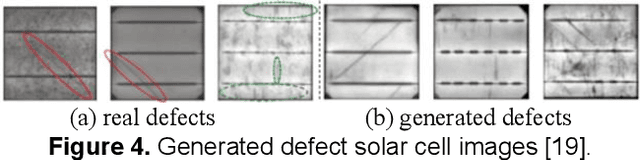
Display front-of-screen (FOS) quality inspection is essential for the mass production of displays in the manufacturing process. However, the severe imbalanced data, especially the limited number of defect samples, has been a long-standing problem that hinders the successful application of deep learning algorithms. Synthetic defect data generation can help address this issue. This paper reviews the state-of-the-art synthetic data generation methods and the evaluation metrics that can potentially be applied to display FOS quality inspection tasks.
ANTLER: Bayesian Nonlinear Tensor Learning and Modeler for Unstructured, Varying-Size Point Cloud Data
Feb 25, 2022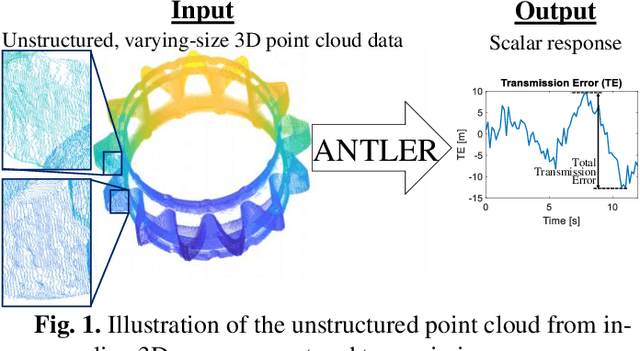
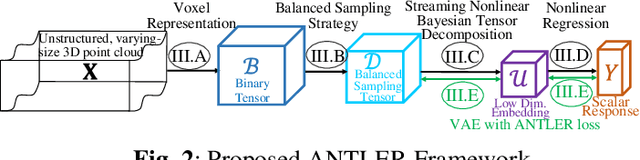
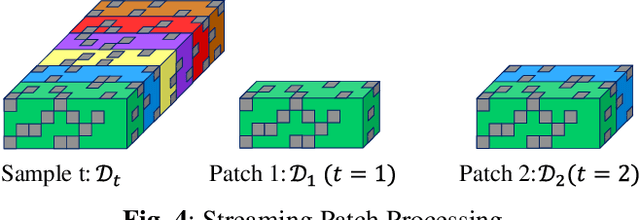

Unstructured point clouds with varying sizes are increasingly acquired in a variety of environments through laser triangulation or Light Detection and Ranging (LiDAR). Predicting a scalar response based on unstructured point clouds is a common problem that arises in a wide variety of applications. The current literature relies on several pre-processing steps such as structured subsampling and feature extraction to analyze the point cloud data. Those techniques lead to quantization artifacts and do not consider the relationship between the regression response and the point cloud during pre-processing. Therefore, we propose a general and holistic "Bayesian Nonlinear Tensor Learning and Modeler" (ANTLER) to model the relationship of unstructured, varying-size point cloud data with a scalar or multivariate response. The proposed ANTLER simultaneously optimizes a nonlinear tensor dimensionality reduction and a nonlinear regression model with a 3D point cloud input and a scalar or multivariate response. ANTLER has the ability to consider the complex data representation, high-dimensionality,and inconsistent size of the 3D point cloud data.
Compressed Smooth Sparse Decomposition
Jan 19, 2022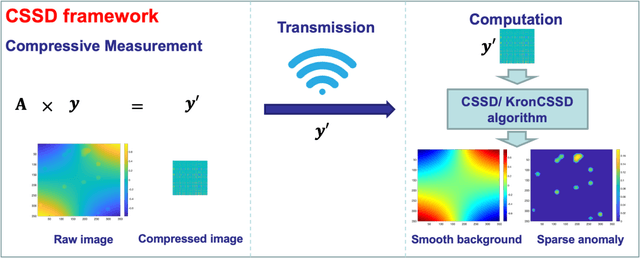
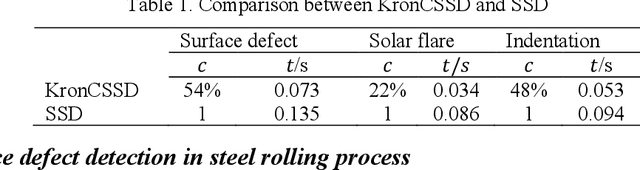
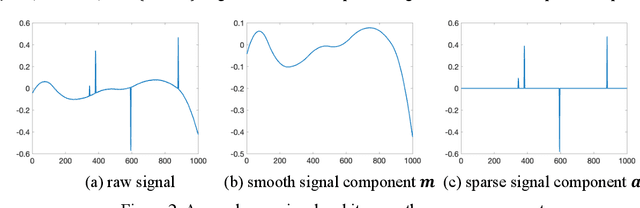
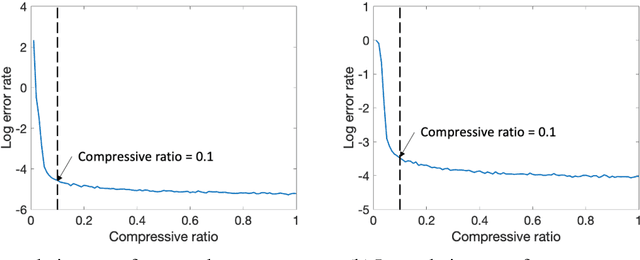
Image-based anomaly detection systems are of vital importance in various manufacturing applications. The resolution and acquisition rate of such systems is increasing significantly in recent years under the fast development of image sensing technology. This enables the detection of tiny defects in real-time. However, such a high resolution and acquisition rate of image data not only slows down the speed of image processing algorithms but also increases data storage and transmission cost. To tackle this problem, we propose a fast and data-efficient method with theoretical performance guarantee that is suitable for sparse anomaly detection in images with a smooth background (smooth plus sparse signal). The proposed method, named Compressed Smooth Sparse Decomposition (CSSD), is a one-step method that unifies the compressive image acquisition and decomposition-based image processing techniques. To further enhance its performance in a high-dimensional scenario, a Kronecker Compressed Smooth Sparse Decomposition (KronCSSD) method is proposed. Compared to traditional smooth and sparse decomposition algorithms, significant transmission cost reduction and computational speed boost can be achieved with negligible performance loss. Simulation examples and several case studies in various applications illustrate the effectiveness of the proposed framework.
Additive Tensor Decomposition Considering Structural Data Information
Jul 27, 2020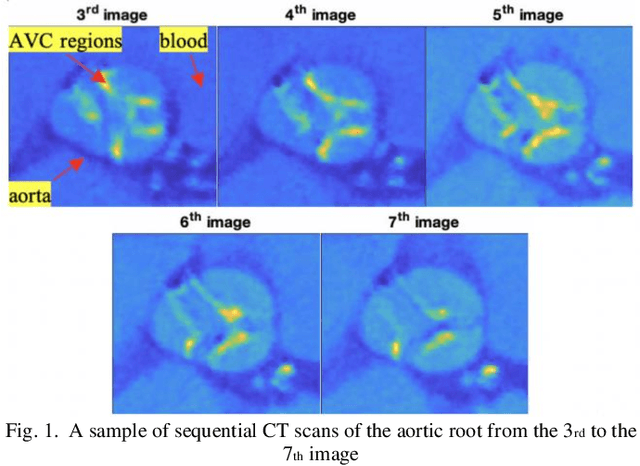
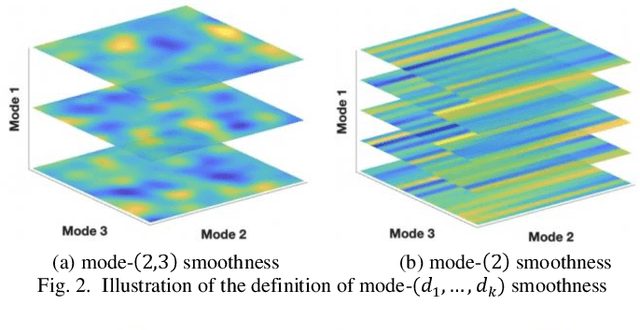

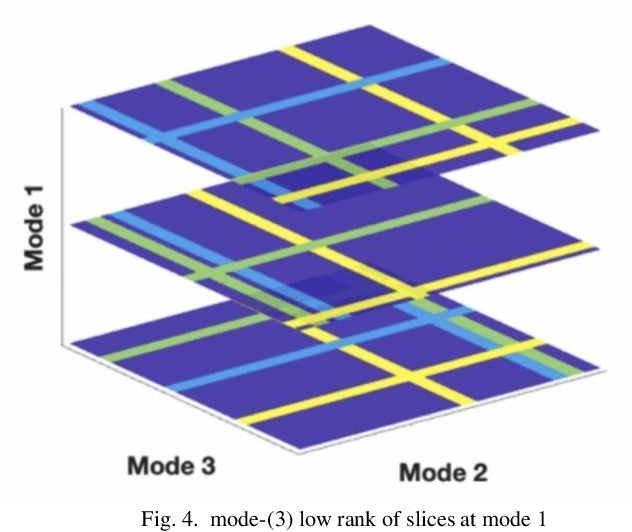
Tensor data with rich structural information becomes increasingly important in process modeling, monitoring, and diagnosis. Here structural information is referred to structural properties such as sparsity, smoothness, low-rank, and piecewise constancy. To reveal useful information from tensor data, we propose to decompose the tensor into the summation of multiple components based on different structural information of them. In this paper, we provide a new definition of structural information in tensor data. Based on it, we propose an additive tensor decomposition (ATD) framework to extract useful information from tensor data. This framework specifies a high dimensional optimization problem to obtain the components with distinct structural information. An alternating direction method of multipliers (ADMM) algorithm is proposed to solve it, which is highly parallelable and thus suitable for the proposed optimization problem. Two simulation examples and a real case study in medical image analysis illustrate the versatility and effectiveness of the ATD framework.
Active Learning for Gaussian Process Considering Uncertainties with Application to Shape Control of Composite Fuselage
Apr 23, 2020
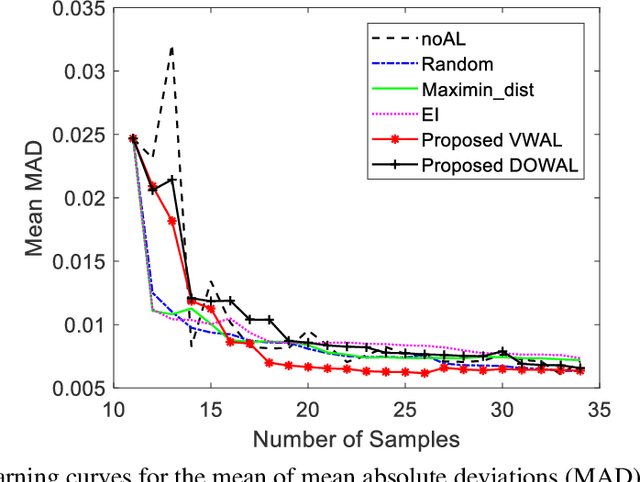
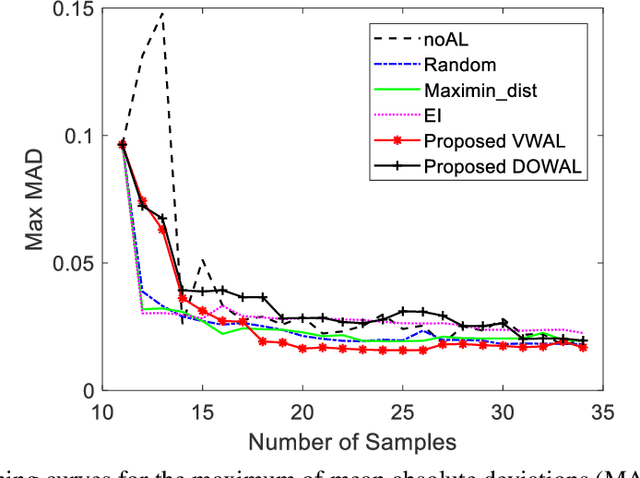
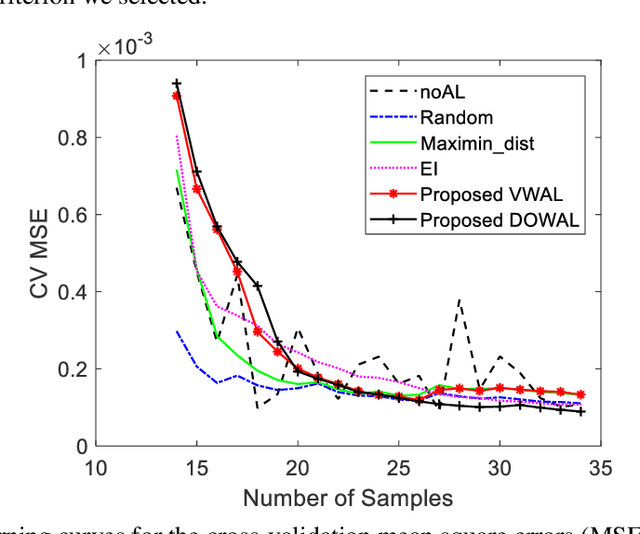
In the machine learning domain, active learning is an iterative data selection algorithm for maximizing information acquisition and improving model performance with limited training samples. It is very useful, especially for the industrial applications where training samples are expensive, time-consuming, or difficult to obtain. Existing methods mainly focus on active learning for classification, and a few methods are designed for regression such as linear regression or Gaussian process. Uncertainties from measurement errors and intrinsic input noise inevitably exist in the experimental data, which further affects the modeling performance. The existing active learning methods do not incorporate these uncertainties for Gaussian process. In this paper, we propose two new active learning algorithms for the Gaussian process with uncertainties, which are variance-based weighted active learning algorithm and D-optimal weighted active learning algorithm. Through numerical study, we show that the proposed approach can incorporate the impact from uncertainties, and realize better prediction performance. This approach has been applied to improving the predictive modeling for automatic shape control of composite fuselage.
AKM$^2$D : An Adaptive Framework for Online Sensing and Anomaly Quantification
Oct 04, 2019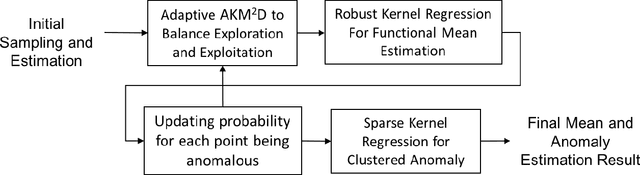
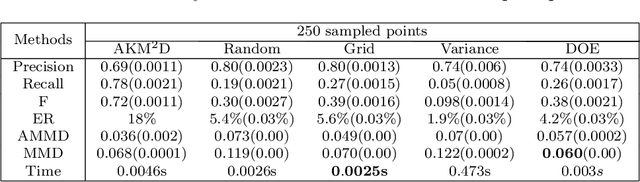
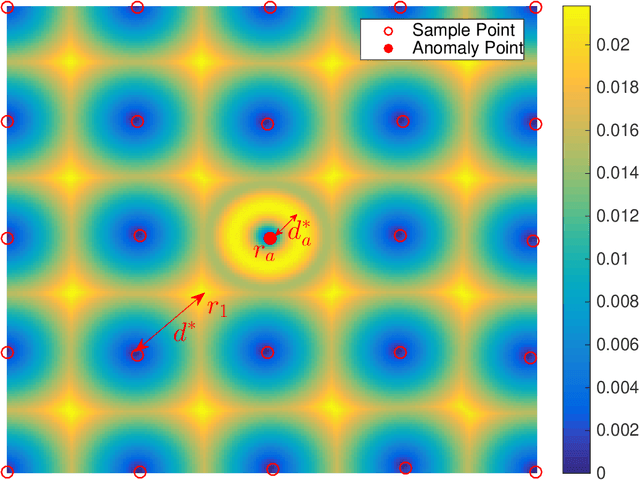
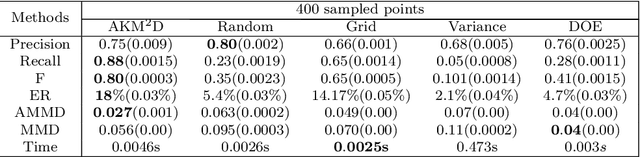
In point-based sensing systems such as coordinate measuring machines (CMM) and laser ultrasonics where complete sensing is impractical due to the high sensing time and cost, adaptive sensing through a systematic exploration is vital for online inspection and anomaly quantification. Most of the existing sequential sampling methodologies focus on reducing the overall fitting error for the entire sampling space. However, in many anomaly quantification applications, the main goal is to estimate sparse anomalous regions in the pixel-level accurately. In this paper, we develop a novel framework named Adaptive Kernelized Maximum-Minimum Distance AKM$^2$D to speed up the inspection and anomaly detection process through an intelligent sequential sampling scheme integrated with fast estimation and detection. The proposed method balances the sampling efforts between the space-filling sampling (exploration) and focused sampling near the anomalous region (exploitation). The proposed methodology is validated by conducting simulations and a case study of anomaly detection in composite sheets using a guided wave test.