 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Multiscale Deep Equilibrium Models
Apr 28, 2022
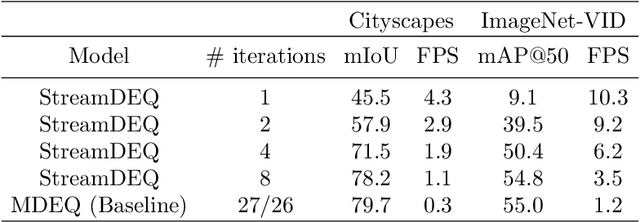
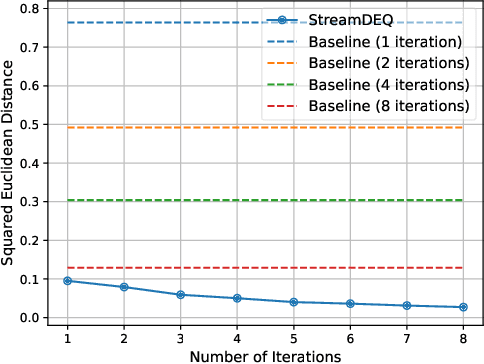
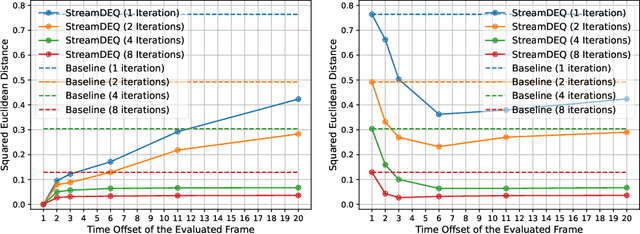
We present StreamDEQ, a method that infers frame-wise representations on videos with minimal per-frame computation. In contrast to conventional methods where compute time grows at least linearly with the network depth, we aim to update the representations in a continuous manner. For this purpose, we leverage the recently emerging implicit layer model which infers the representation of an image by solving a fixed-point problem. Our main insight is to leverage the slowly changing nature of videos and use the previous frame representation as an initial condition on each frame. This scheme effectively recycles the recent inference computations and greatly reduces the needed processing time. Through extensive experimental analysis, we show that StreamDEQ is able to recover near-optimal representations in a few frames time, and maintain an up-to-date representation throughout the video duration. Our experiments on video semantic segmentation and video object detection show that StreamDEQ achieves on par accuracy with the baseline (standard MDEQ) while being more than $3\times$ faster. The project page is available at: https://ufukertenli.github.io/streamdeq/