 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning with Unseen Objects
Paper and Code
Jul 31, 2019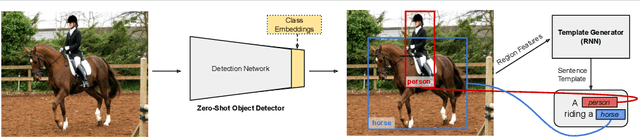


Image caption generation is a long standing and challenging problem at the intersection of computer vision and natural language processing. A number of recently proposed approaches utilize a fully supervised object recognition model within the captioning approach. Such models, however, tend to generate sentences which only consist of objects predicted by the recognition models, excluding instances of the classes without labelled training examples. In this paper, we propose a new challenging scenario that targets the image captioning problem in a fully zero-shot learning setting, where the goal is to be able to generate captions of test images containing objects that are not seen during training. The proposed approach jointly uses a novel zero-shot object detection model and a template-based sentence generator. Our experiments show promising results on the COCO dataset.