 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANILLA: Generative Adversarial Networks for Image to Illustration Translation
Paper and Code

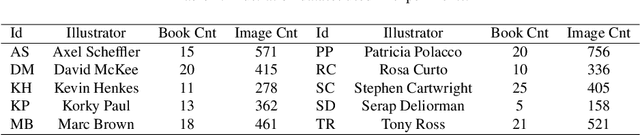


In this paper, we explore illustrations in children's books as a new domain in unpaired image-to-image translation. We show that although the current state-of-the-art image-to-image translation models successfully transfer either the style or the content, they fail to transfer both at the same time. We propose a new generator network to address this issue and show that the resulting network strikes a better balance between style and content. There are no well-defined or agreed-upon evaluation metrics for unpaired image-to-image translation. So far, the success of image translation models has been based on subjective, qualitative visual comparison on a limited number of images. To address this problem, we propose a new framework for the quantitative evaluation of image-to-illustration models, where both content and style are taken into account using separate classifiers. In this new evaluation framework, our proposed model performs better than the current state-of-the-art models on the illustrations dataset. Our code and pretrained models can be found at https://github.com/giddyyupp/ganilla.