 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTER: Latent Pseudo-Anomaly Generation for Unsupervised Time-Series Anomaly Detection
Apr 15, 2026Time-series anomaly detection (TSAD) is critical in domains such as industrial monitoring, healthcare, and cybersecurity, but it remains challenging due to rare and heterogeneous anomalies and the scarcity of labelled data. This scarcity makes unsupervised approaches predominant, yet existing methods often rely on reconstruction or forecasting, which struggle with complex data, or on embedding-based approaches that require domain-specific anomaly synthesis and fixed distance metrics. We propose ASTER, a framework that generates pseudo-anomalies directly in the latent space, avoiding handcrafted anomaly injections and the need for domain expertise. A latent-space decoder produces tailored pseudo-anomalies to train a Transformer-based anomaly classifier, while a pre-trained LLM enriches the temporal and contextual representations of this space. Experiments on three benchmark datasets show that ASTER achieves state-of-the-art performance and sets a new standard for LLM-based TSAD.
Annotation Free Spacecraft Detection and Segmentation using Vision Language Models
Feb 04, 2026Vision Language Models (VLMs) have demonstrated remarkable performance in open-world zero-shot visual recognition. However, their potential in space-related applications remains largely unexplored. In the space domain, accurate manual annotation is particularly challenging due to factors such as low visibility, illumination variations, and object blending with planetary backgrounds. Developing methods that can detect and segment spacecraft and orbital targets without requiring extensive manual labeling is therefore of critical importance. In this work, we propose an annotation-free detection and segmentation pipeline for space targets using VLMs. Our approach begins by automatically generating pseudo-labels for a small subset of unlabeled real data with a pre-trained VLM. These pseudo-labels are then leveraged in a teacher-student label distillation framework to train lightweight models. Despite the inherent noise in the pseudo-labels, the distillation process leads to substantial performance gains over direct zero-shot VLM inference. Experimental evaluations on the SPARK-2024, SPEED+, and TANGO datasets on segmentation tasks demonstrate consistent improvements in average precision (AP) by up to 10 points. Code and models are available at https://github.com/giddyyupp/annotation-free-spacecraft-segmentation.
Training Free Zero-Shot Visual Anomaly Localization via Diffusion Inversion
Jan 12, 2026Zero-Shot image Anomaly Detection (ZSAD) aims to detect and localise anomalies without access to any normal training samples of the target data. While recent ZSAD approaches leverage additional modalities such as language to generate fine-grained prompts for localisation, vision-only methods remain limited to image-level classification, lacking spatial precision. In this work, we introduce a simple yet effective training-free vision-only ZSAD framework that circumvents the need for fine-grained prompts by leveraging the inversion of a pretrained Denoising Diffusion Implicit Model (DDIM). Specifically, given an input image and a generic text description (e.g., "an image of an [object class]"), we invert the image to obtain latent representations and initiate the denoising process from a fixed intermediate timestep to reconstruct the image. Since the underlying diffusion model is trained solely on normal data, this process yields a normal-looking reconstruction. The discrepancy between the input image and the reconstructed one highlights potential anomalies. Our method achieves state-of-the-art performance on VISA dataset, demonstrating strong localisation capabilities without auxiliary modalities and facilitating a shift away from prompt dependence for zero-shot anomaly detection research. Code is available at https://github.com/giddyyupp/DIVAD.
VLMDiff: Leveraging Vision-Language Models for Multi-Class Anomaly Detection with Diffusion
Nov 11, 2025



Detecting visual anomalies in diverse, multi-class real-world images is a significant challenge. We introduce \ours, a novel unsupervised multi-class visual anomaly detection framework. It integrates a Latent Diffusion Model (LDM) with a Vision-Language Model (VLM) for enhanced anomaly localization and detection. Specifically, a pre-trained VLM with a simple prompt extracts detailed image descriptions, serving as additional conditioning for LDM training. Current diffusion-based methods rely on synthetic noise generation, limiting their generalization and requiring per-class model training, which hinders scalability. \ours, however, leverages VLMs to obtain normal captions without manual annotations or additional training. These descriptions condition the diffusion model, learning a robust normal image feature representation for multi-class anomaly detection. Our method achieves competitive performance, improving the pixel-level Per-Region-Overlap (PRO) metric by up to 25 points on the Real-IAD dataset and 8 points on the COCO-AD dataset, outperforming state-of-the-art diffusion-based approaches. Code is available at https://github.com/giddyyupp/VLMDiff.
WAIT: Feature Warping for Animation to Illustration video Translation using GANs
Oct 07, 2023In this paper, we explore a new domain for video-to-video translation. Motivated by the availability of animation movies that are adopted from illustrated books for children, we aim to stylize these videos with the style of the original illustrations. Current state-of-the-art video-to-video translation models rely on having a video sequence or a single style image to stylize an input video. We introduce a new problem for video stylizing where an unordered set of images are used. This is a challenging task for two reasons: i) we do not have the advantage of temporal consistency as in video sequences; ii) it is more difficult to obtain consistent styles for video frames from a set of unordered images compared to using a single image. Most of the video-to-video translation methods are built on an image-to-image translation model, and integrate additional networks such as optical flow, or temporal predictors to capture temporal relations. These additional networks make the model training and inference complicated and slow down the process. To ensure temporal coherency in video-to-video style transfer, we propose a new generator network with feature warping layers which overcomes the limitations of the previous methods. We show the effectiveness of our method on three datasets both qualitatively and quantitatively. Code and pretrained models are available at https://github.com/giddyyupp/wait.
Improving Sketch Colorization using Adversarial Segmentation Consistency
Jan 20, 2023We propose a new method for producing color images from sketches. Current solutions in sketch colorization either necessitate additional user instruction or are restricted to the "paired" translation strategy. We leverage semantic image segmentation from a general-purpose panoptic segmentation network to generate an additional adversarial loss function. The proposed loss function is compatible with any GAN model. Our method is not restricted to datasets with segmentation labels and can be applied to unpaired translation tasks as well. Using qualitative, and quantitative analysis, and based on a user study, we demonstrate the efficacy of our method on four distinct image datasets. On the FID metric, our model improves the baseline by up to 35 points. Our code, pretrained models, scripts to produce newly introduced datasets and corresponding sketch images are available at https://github.com/giddyyupp/AdvSegLoss.
HoughNet: Integrating near and long-range evidence for visual detection
Apr 14, 2021
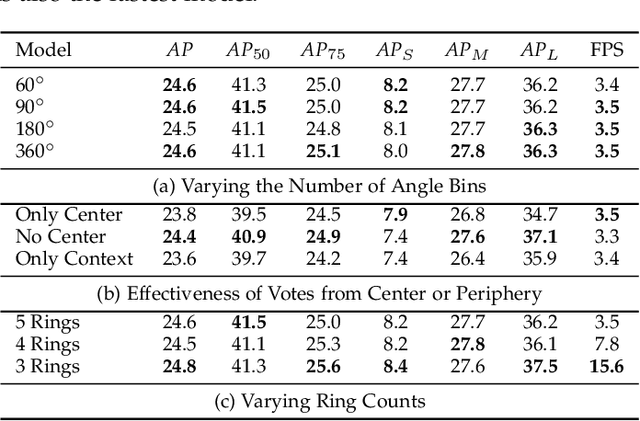
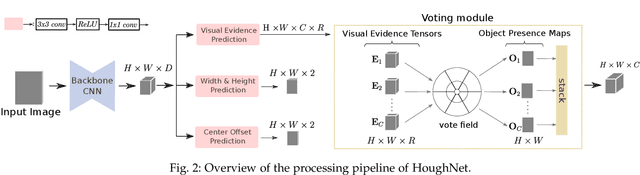

This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet's best model achieves $46.4$ $AP$ (and $65.1$ $AP_{50}$), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in other visual detection tasks, namely, video object detection, instance segmentation, 3D object detection and keypoint detection for human pose estimation, and an additional ``labels to photo`` image generation task, where the integration of our voting module consistently improves performance in all cases. Code is available at \url{https://github.com/nerminsamet/houghnet}.
Adversarial Segmentation Loss for Sketch Colorization
Feb 11, 2021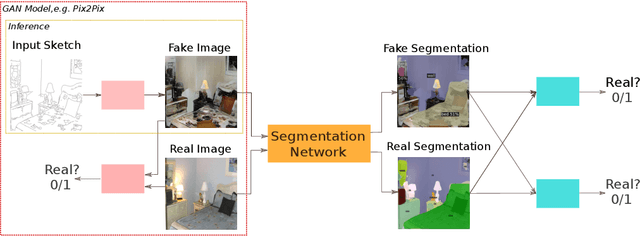


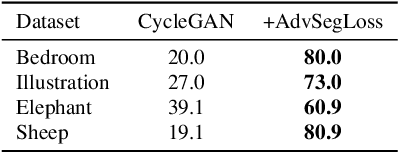
We introduce a new method for generating color images from sketches or edge maps. Current methods either require some form of additional user-guidance or are limited to the "paired" translation approach. We argue that segmentation information could provide valuable guidance for sketch colorization. To this end, we propose to leverage semantic image segmentation, as provided by a general purpose panoptic segmentation network, to create an additional adversarial loss function. Our loss function can be integrated to any baseline GAN model. Our method is not limited to datasets that contain segmentation labels, and it can be trained for "unpaired" translation tasks. We show the effectiveness of our method on four different datasets spanning scene level indoor, outdoor, and children book illustration images using qualitative, quantitative and user study analysis. Our model improves its baseline up to 35 points on the FID metric. Our code and pretrained models can be found at https://github.com/giddyyupp/AdvSegLoss.
Reducing Label Noise in Anchor-Free Object Detection
Aug 13, 2020
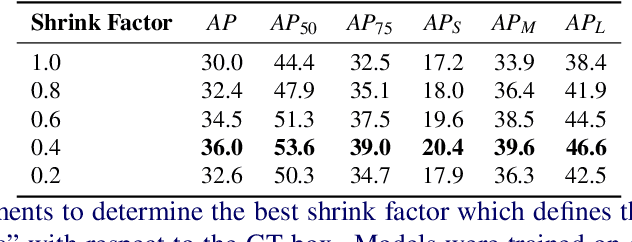
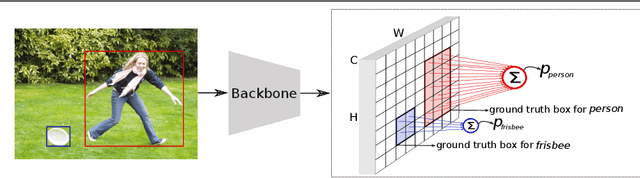
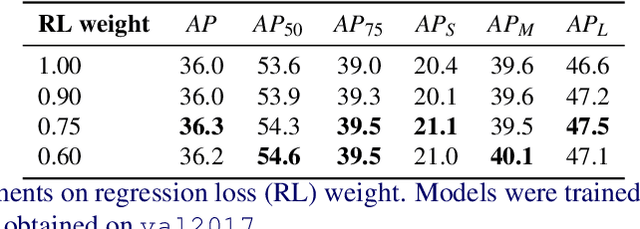
Current anchor-free object detectors label all the features that spatially fall inside a predefined central region of a ground-truth box as positive. This approach causes label noise during training, since some of these positively labeled features may be on the background or an occluder object, or they are simply not discriminative features. In this paper, we propose a new labeling strategy aimed to reduce the label noise in anchor-free detectors. We sum-pool predictions stemming from individual features into a single prediction. This allows the model to reduce the contributions of non-discriminatory features during training. We develop a new one-stage, anchor-free object detector, PPDet, to employ this labeling strategy during training and a similar prediction pooling method during inference. On the COCO dataset, PPDet achieves the best performance among anchor-free top-down detectors and performs on-par with the other state-of-the-art methods. It also outperforms all major one-stage and two-stage methods in small object detection (${AP}_{S}$ $31.4$). Code is available at https://github.com/nerminsamet/ppdet
HoughNet: Integrating near and long-range evidence for bottom-up object detection
Jul 05, 2020
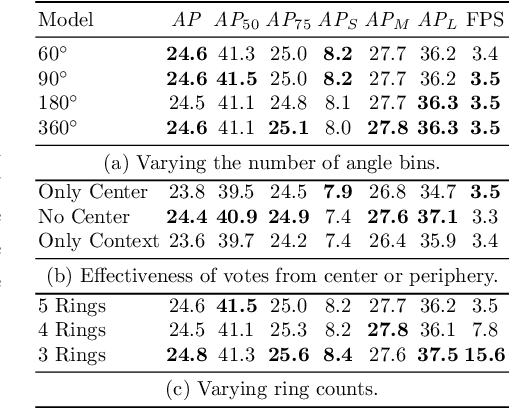
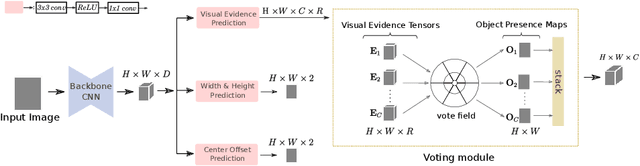
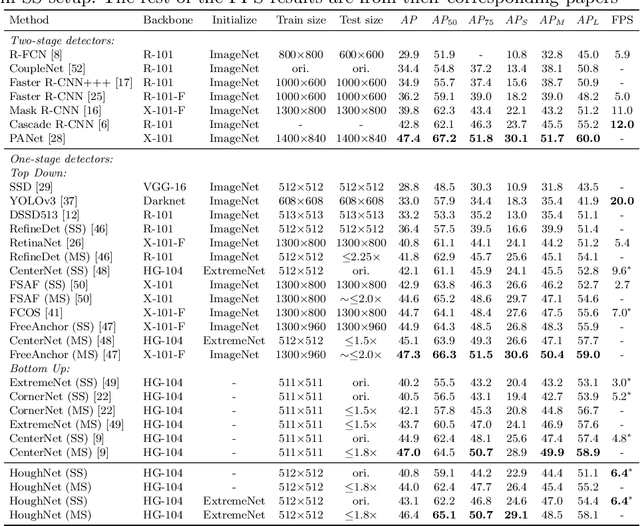
This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet achieves 46.4 AP (and 65.1 AP_50), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in another task, namely, "labels to photo" image generation by integrating the voting module of HoughNet to two different GAN models and showing that the accuracy is significantly improved in both cases. Code is available at: https://github.com/nerminsamet/houghnet