 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Dive into Adversarial Robustness in Zero-Shot Learning
Paper and Code
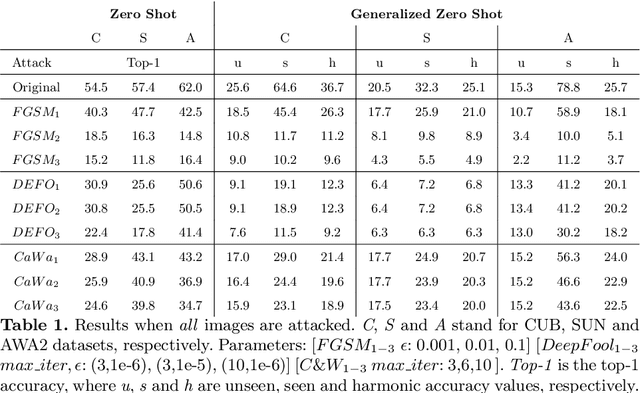


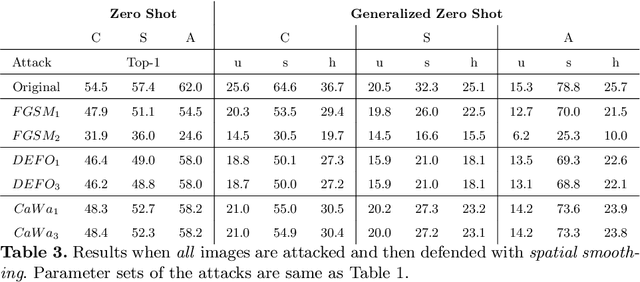
Machine learning (ML) systems have introduced significant advances in various fields, due to the introduction of highly complex models. Despite their success, it has been shown multiple times that machine learning models are prone to imperceptible perturbations that can severely degrade their accuracy. So far, existing studies have primarily focused on models where supervision across all classes were available. In constrast, Zero-shot Learning (ZSL) and Generalized Zero-shot Learning (GZSL) tasks inherently lack supervision across all classes. In this paper, we present a study aimed on evaluating the adversarial robustness of ZSL and GZSL models. We leverage the well-established label embedding model and subject it to a set of established adversarial attacks and defenses across multiple datasets. In addition to creating possibly the first benchmark on adversarial robustness of ZSL models, we also present analyses on important points that require attention for better interpretation of ZSL robustness results. We hope these points, along with the benchmark, will help researchers establish a better understanding what challenges lie ahead and help guide their work.