 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
GaussRender: Learning 3D Occupancy with Gaussian Rendering
Feb 07, 2025



Understanding the 3D geometry and semantics of driving scenes is critical for developing of safe autonomous vehicles. While 3D occupancy models are typically trained using voxel-based supervision with standard losses (e.g., cross-entropy, Lovasz, dice), these approaches treat voxel predictions independently, neglecting their spatial relationships. In this paper, we propose GaussRender, a plug-and-play 3D-to-2D reprojection loss that enhances voxel-based supervision. Our method projects 3D voxel representations into arbitrary 2D perspectives and leverages Gaussian splatting as an efficient, differentiable rendering proxy of voxels, introducing spatial dependencies across projected elements. This approach improves semantic and geometric consistency, handles occlusions more efficiently, and requires no architectural modifications. Extensive experiments on multiple benchmarks (SurroundOcc-nuScenes, Occ3D-nuScenes, SSCBench-KITTI360) demonstrate consistent performance gains across various 3D occupancy models (TPVFormer, SurroundOcc, Symphonies), highlighting the robustness and versatility of our framework. The code is available at https://github.com/valeoai/GaussRender.
LOGen: Toward Lidar Object Generation by Point Diffusion
Dec 10, 2024



A common strategy to improve lidar segmentation results on rare semantic classes consists of pasting objects from one lidar scene into another. While this augments the quantity of instances seen at training time and varies their context, the instances fundamentally remain the same. In this work, we explore how to enhance instance diversity using a lidar object generator. We introduce a novel diffusion-based method to produce lidar point clouds of dataset objects, including reflectance, and with an extensive control of the generation via conditioning information. Our experiments on nuScenes show the quality of our object generations measured with new 3D metrics developed to suit lidar objects.
Annealed Multiple Choice Learning: Overcoming limitations of Winner-takes-all with annealing
Jul 22, 2024



We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024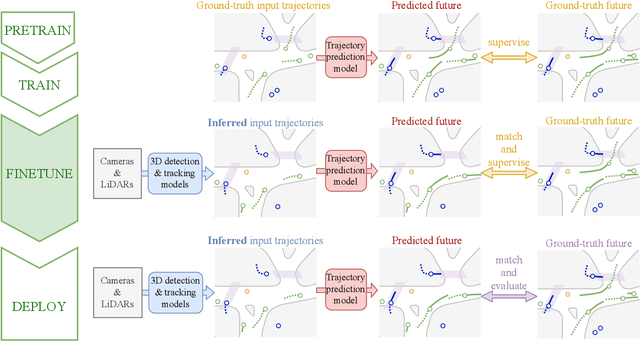
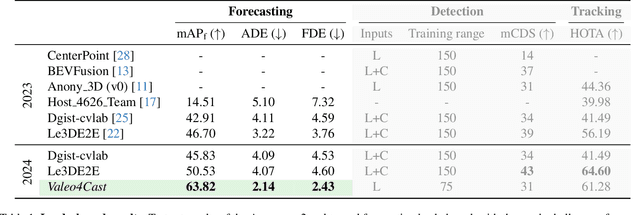
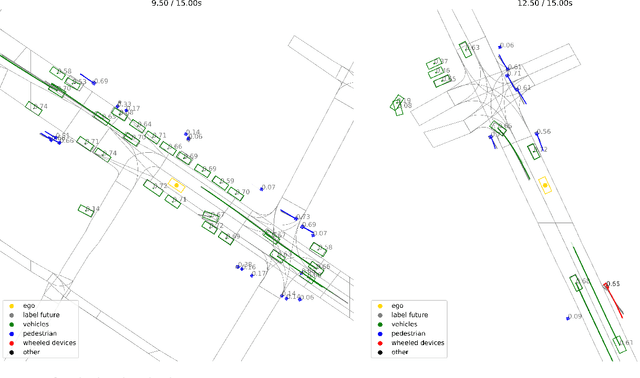
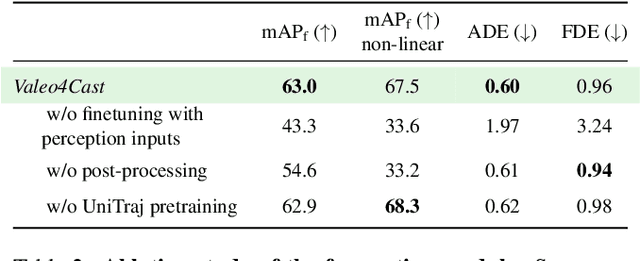
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
Manipulating Trajectory Prediction with Backdoors
Jan 03, 2024



Autonomous vehicles ought to predict the surrounding agents' trajectories to allow safe maneuvers in uncertain and complex traffic situations. As companies increasingly apply trajectory prediction in the real world, security becomes a relevant concern. In this paper, we focus on backdoors - a security threat acknowledged in other fields but so far overlooked for trajectory prediction. To this end, we describe and investigate four triggers that could affect trajectory prediction. We then show that these triggers (for example, a braking vehicle), when correlated with a desired output (for example, a curve) during training, cause the desired output of a state-of-the-art trajectory prediction model. In other words, the model has good benign performance but is vulnerable to backdoors. This is the case even if the trigger maneuver is performed by a non-casual agent behind the target vehicle. As a side-effect, our analysis reveals interesting limitations within trajectory prediction models. Finally, we evaluate a range of defenses against backdoors. While some, like simple offroad checks, do not enable detection for all triggers, clustering is a promising candidate to support manual inspection to find backdoors.
Reliability in Semantic Segmentation: Can We Use Synthetic Data?
Dec 14, 2023
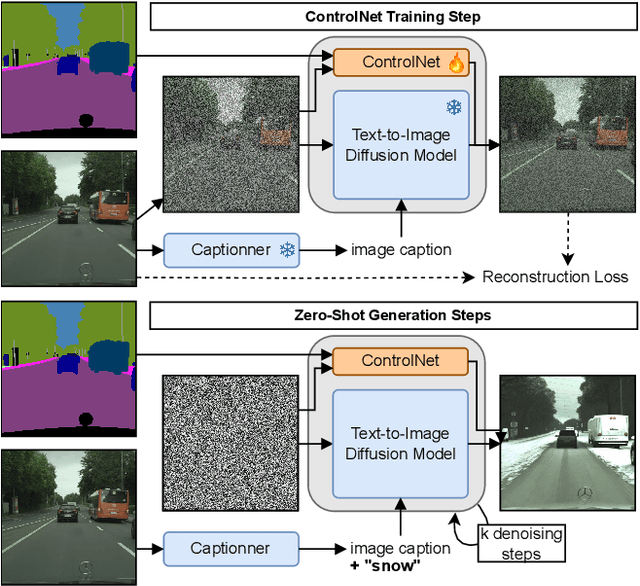
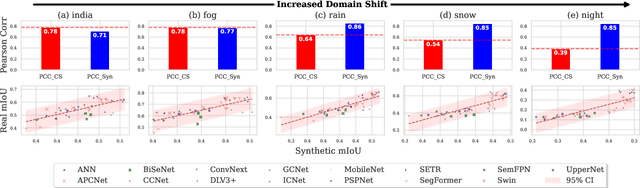
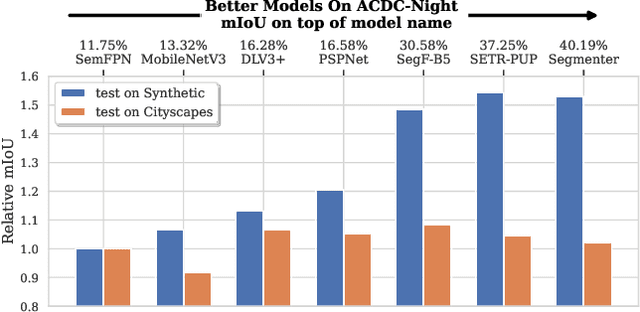
Assessing the reliability of perception models to covariate shifts and out-of-distribution (OOD) detection is crucial for safety-critical applications such as autonomous vehicles. By nature of the task, however, the relevant data is difficult to collect and annotate. In this paper, we challenge cutting-edge generative models to automatically synthesize data for assessing reliability in semantic segmentation. By fine-tuning Stable Diffusion, we perform zero-shot generation of synthetic data in OOD domains or inpainted with OOD objects. Synthetic data is employed to provide an initial assessment of pretrained segmenters, thereby offering insights into their performance when confronted with real edge cases. Through extensive experiments, we demonstrate a high correlation between the performance on synthetic data and the performance on real OOD data, showing the validity approach. Furthermore, we illustrate how synthetic data can be utilized to enhance the calibration and OOD detection capabilities of segmenters.
PointBeV: A Sparse Approach to BeV Predictions
Dec 01, 2023



Bird's-eye View (BeV) representations have emerged as the de-facto shared space in driving applications, offering a unified space for sensor data fusion and supporting various downstream tasks. However, conventional models use grids with fixed resolution and range and face computational inefficiencies due to the uniform allocation of resources across all cells. To address this, we propose PointBeV, a novel sparse BeV segmentation model operating on sparse BeV cells instead of dense grids. This approach offers precise control over memory usage, enabling the use of long temporal contexts and accommodating memory-constrained platforms. PointBeV employs an efficient two-pass strategy for training, enabling focused computation on regions of interest. At inference time, it can be used with various memory/performance trade-offs and flexibly adjusts to new specific use cases. PointBeV achieves state-of-the-art results on the nuScenes dataset for vehicle, pedestrian, and lane segmentation, showcasing superior performance in static and temporal settings despite being trained solely with sparse signals. We will release our code along with two new efficient modules used in the architecture: Sparse Feature Pulling, designed for the effective extraction of features from images to BeV, and Submanifold Attention, which enables efficient temporal modeling. Our code is available at https://github.com/valeoai/PointBeV.
A Pytorch Reproduction of Masked Generative Image Transformer
Oct 22, 2023



In this technical report, we present a reproduction of MaskGIT: Masked Generative Image Transformer, using PyTorch. The approach involves leveraging a masked bidirectional transformer architecture, enabling image generation with only few steps (8~16 steps) for 512 x 512 resolution images, i.e., ~64x faster than an auto-regressive approach. Through rigorous experimentation and optimization, we achieved results that closely align with the findings presented in the original paper. We match the reported FID of 7.32 with our replication and obtain 7.59 with similar hyperparameters on ImageNet at resolution 512 x 512. Moreover, we improve over the official implementation with some minor hyperparameter tweaking, achieving FID of 7.26. At the lower resolution of 256 x 256 pixels, our reimplementation scores 6.80, in comparison to the original paper's 6.18. To promote further research on Masked Generative Models and facilitate their reproducibility, we released our code and pre-trained weights openly at https://github.com/valeoai/MaskGIT-pytorch/