 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIV-EX: Counterfactual Explanations for Driving LLMs
Feb 28, 2026Large language models (LLMs) are increasingly used as reasoning engines in autonomous driving, yet their decision-making remains opaque. We propose to study their decision process through counterfactual explanations, which identify the minimal semantic changes to a scene description required to alter a driving plan. We introduce DRIV-EX, a method that leverages gradient-based optimization on continuous embeddings to identify the input shifts required to flip the model's decision. Crucially, to avoid the incoherent text typical of unconstrained continuous optimization, DRIV-EX uses these optimized embeddings solely as a semantic guide: they are used to bias a controlled decoding process that re-generates the original scene description. This approach effectively steers the generation toward the counterfactual target while guaranteeing the linguistic fluency, domain validity, and proximity to the original input, essential for interpretability. Evaluated using the LC-LLM planner on a textual transcription of the highD dataset, DRIV-EX generates valid, fluent counterfactuals more reliably than existing baselines. It successfully exposes latent biases and provides concrete insights to improve the robustness of LLM-based driving agents.
MAD: Motion Appearance Decoupling for efficient Driving World Models
Jan 14, 2026Recent video diffusion models generate photorealistic, temporally coherent videos, yet they fall short as reliable world models for autonomous driving, where structured motion and physically consistent interactions are essential. Adapting these generalist video models to driving domains has shown promise but typically requires massive domain-specific data and costly fine-tuning. We propose an efficient adaptation framework that converts generalist video diffusion models into controllable driving world models with minimal supervision. The key idea is to decouple motion learning from appearance synthesis. First, the model is adapted to predict structured motion in a simplified form: videos of skeletonized agents and scene elements, focusing learning on physical and social plausibility. Then, the same backbone is reused to synthesize realistic RGB videos conditioned on these motion sequences, effectively "dressing" the motion with texture and lighting. This two-stage process mirrors a reasoning-rendering paradigm: first infer dynamics, then render appearance. Our experiments show this decoupled approach is exceptionally efficient: adapting SVD, we match prior SOTA models with less than 6% of their compute. Scaling to LTX, our MAD-LTX model outperforms all open-source competitors, and supports a comprehensive suite of text, ego, and object controls. Project page: https://vita-epfl.github.io/MAD-World-Model/
RAP: 3D Rasterization Augmented End-to-End Planning
Oct 05, 2025Imitation learning for end-to-end driving trains policies only on expert demonstrations. Once deployed in a closed loop, such policies lack recovery data: small mistakes cannot be corrected and quickly compound into failures. A promising direction is to generate alternative viewpoints and trajectories beyond the logged path. Prior work explores photorealistic digital twins via neural rendering or game engines, but these methods are prohibitively slow and costly, and thus mainly used for evaluation. In this work, we argue that photorealism is unnecessary for training end-to-end planners. What matters is semantic fidelity and scalability: driving depends on geometry and dynamics, not textures or lighting. Motivated by this, we propose 3D Rasterization, which replaces costly rendering with lightweight rasterization of annotated primitives, enabling augmentations such as counterfactual recovery maneuvers and cross-agent view synthesis. To transfer these synthetic views effectively to real-world deployment, we introduce a Raster-to-Real feature-space alignment that bridges the sim-to-real gap. Together, these components form Rasterization Augmented Planning (RAP), a scalable data augmentation pipeline for planning. RAP achieves state-of-the-art closed-loop robustness and long-tail generalization, ranking first on four major benchmarks: NAVSIM v1/v2, Waymo Open Dataset Vision-based E2E Driving, and Bench2Drive. Our results show that lightweight rasterization with feature alignment suffices to scale E2E training, offering a practical alternative to photorealistic rendering. Project page: https://alan-lanfeng.github.io/RAP/.
GaussRender: Learning 3D Occupancy with Gaussian Rendering
Feb 07, 2025



Understanding the 3D geometry and semantics of driving scenes is critical for developing of safe autonomous vehicles. While 3D occupancy models are typically trained using voxel-based supervision with standard losses (e.g., cross-entropy, Lovasz, dice), these approaches treat voxel predictions independently, neglecting their spatial relationships. In this paper, we propose GaussRender, a plug-and-play 3D-to-2D reprojection loss that enhances voxel-based supervision. Our method projects 3D voxel representations into arbitrary 2D perspectives and leverages Gaussian splatting as an efficient, differentiable rendering proxy of voxels, introducing spatial dependencies across projected elements. This approach improves semantic and geometric consistency, handles occlusions more efficiently, and requires no architectural modifications. Extensive experiments on multiple benchmarks (SurroundOcc-nuScenes, Occ3D-nuScenes, SSCBench-KITTI360) demonstrate consistent performance gains across various 3D occupancy models (TPVFormer, SurroundOcc, Symphonies), highlighting the robustness and versatility of our framework. The code is available at https://github.com/valeoai/GaussRender.
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
Sep 18, 2024
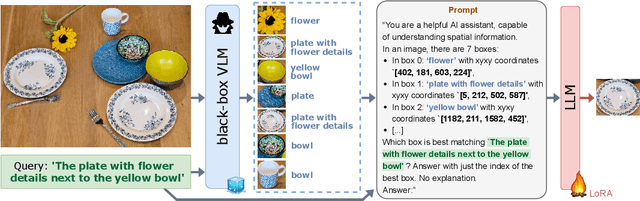
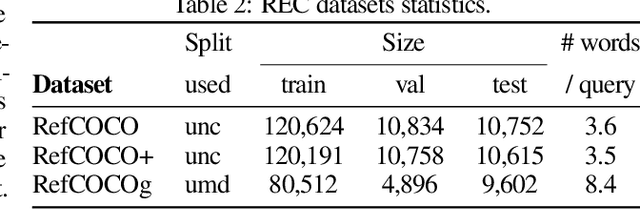
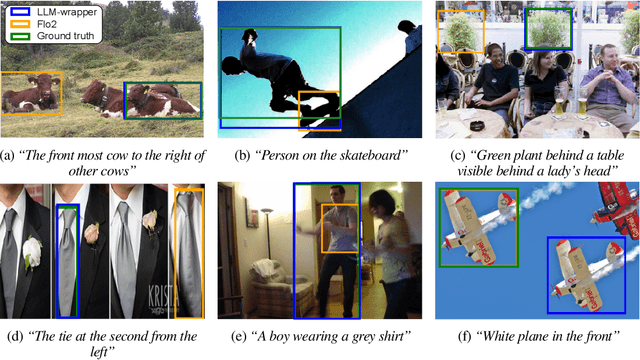
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with limitations as it requires `white-box' access to the model's architecture and weights as well as expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a `black-box' manner by leveraging large language models (LLMs) so as to reason on their outputs. We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, resulting in competitive results when compared with classic fine-tuning.
PointBeV: A Sparse Approach to BeV Predictions
Dec 01, 2023



Bird's-eye View (BeV) representations have emerged as the de-facto shared space in driving applications, offering a unified space for sensor data fusion and supporting various downstream tasks. However, conventional models use grids with fixed resolution and range and face computational inefficiencies due to the uniform allocation of resources across all cells. To address this, we propose PointBeV, a novel sparse BeV segmentation model operating on sparse BeV cells instead of dense grids. This approach offers precise control over memory usage, enabling the use of long temporal contexts and accommodating memory-constrained platforms. PointBeV employs an efficient two-pass strategy for training, enabling focused computation on regions of interest. At inference time, it can be used with various memory/performance trade-offs and flexibly adjusts to new specific use cases. PointBeV achieves state-of-the-art results on the nuScenes dataset for vehicle, pedestrian, and lane segmentation, showcasing superior performance in static and temporal settings despite being trained solely with sparse signals. We will release our code along with two new efficient modules used in the architecture: Sparse Feature Pulling, designed for the effective extraction of features from images to BeV, and Submanifold Attention, which enables efficient temporal modeling. Our code is available at https://github.com/valeoai/PointBeV.
Transductive Zero-Shot Learning using Cross-Modal CycleGAN
Nov 13, 2020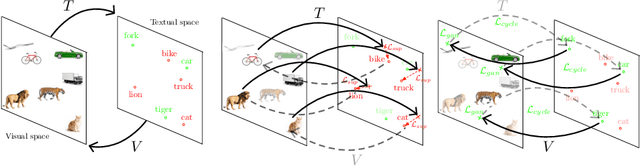
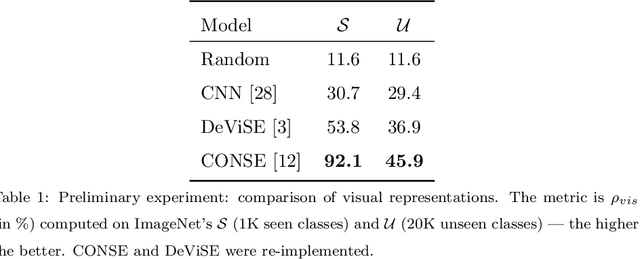
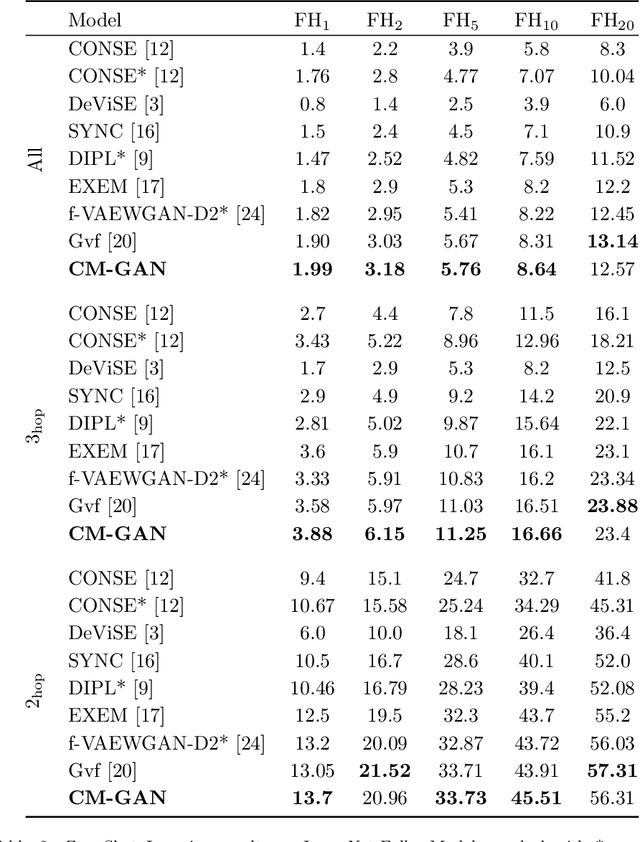
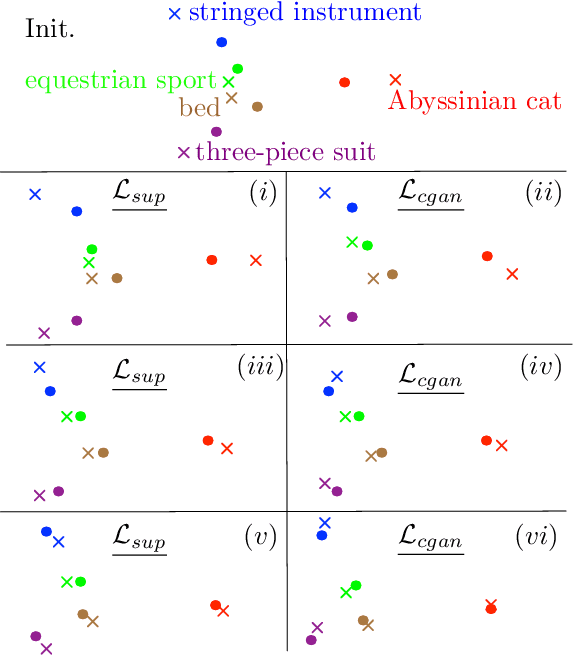
In Computer Vision, Zero-Shot Learning (ZSL) aims at classifying unseen classes -- classes for which no matching training image exists. Most of ZSL works learn a cross-modal mapping between images and class labels for seen classes. However, the data distribution of seen and unseen classes might differ, causing a domain shift problem. Following this observation, transductive ZSL (T-ZSL) assumes that unseen classes and their associated images are known during training, but not their correspondence. As current T-ZSL approaches do not scale efficiently when the number of seen classes is high, we tackle this problem with a new model for T-ZSL based upon CycleGAN. Our model jointly (i) projects images on their seen class labels with a supervised objective and (ii) aligns unseen class labels and visual exemplars with adversarial and cycle-consistency objectives. We show the efficiency of our Cross-Modal CycleGAN model (CM-GAN) on the ImageNet T-ZSL task where we obtain state-of-the-art results. We further validate CM-GAN on a language grounding task, and on a new task that we propose: zero-shot sentence-to-image matching on MS COCO.
Incorporating Visual Semantics into Sentence Representations within a Grounded Space
Feb 07, 2020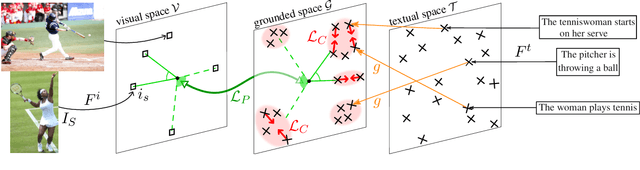
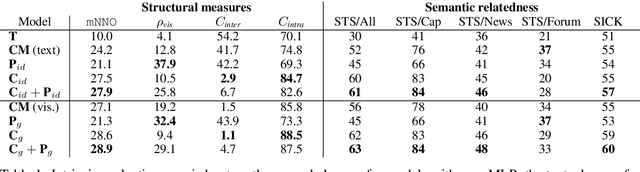


Language grounding is an active field aiming at enriching textual representations with visual information. Generally, textual and visual elements are embedded in the same representation space, which implicitly assumes a one-to-one correspondence between modalities. This hypothesis does not hold when representing words, and becomes problematic when used to learn sentence representations --- the focus of this paper --- as a visual scene can be described by a wide variety of sentences. To overcome this limitation, we propose to transfer visual information to textual representations by learning an intermediate representation space: the grounded space. We further propose two new complementary objectives ensuring that (1) sentences associated with the same visual content are close in the grounded space and (2) similarities between related elements are preserved across modalities. We show that this model outperforms the previous state-of-the-art on classification and semantic relatedness tasks.
Context-Aware Zero-Shot Learning for Object Recognition
Apr 30, 2019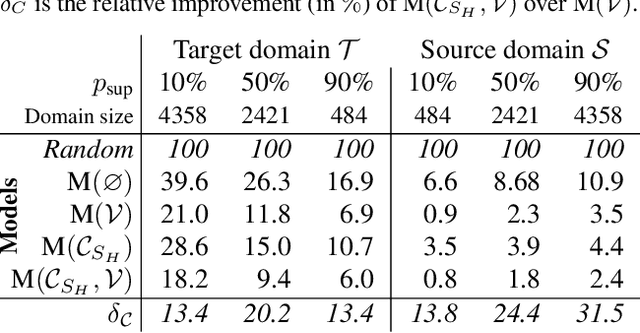
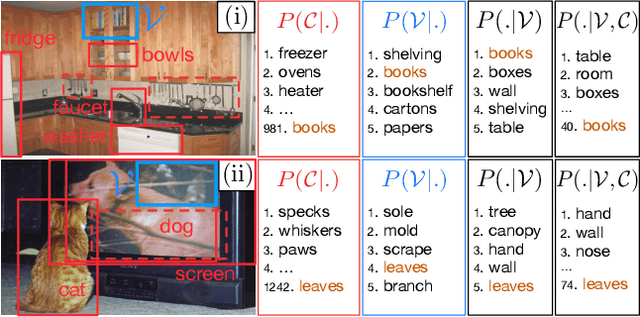
Zero-Shot Learning (ZSL) aims at classifying unlabeled objects by leveraging auxiliary knowledge, such as semantic representations. A limitation of previous approaches is that only intrinsic properties of objects, e.g. their visual appearance, are taken into account while their context, e.g. the surrounding objects in the image, is ignored. Following the intuitive principle that objects tend to be found in certain contexts but not others, we propose a new and challenging approach, context-aware ZSL, that leverages semantic representations in a new way to model the conditional likelihood of an object to appear in a given context. Finally, through extensive experiments conducted on Visual Genome, we show that contextual information can substantially improve the standard ZSL approach and is robust to unbalanced classes.