 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
Paper and Code

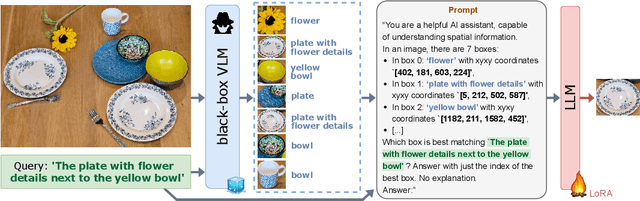
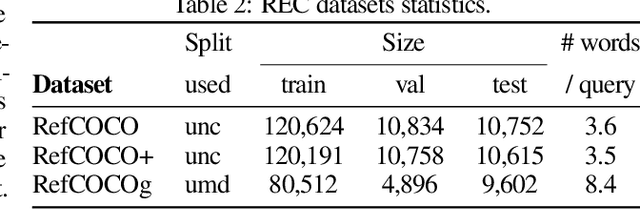
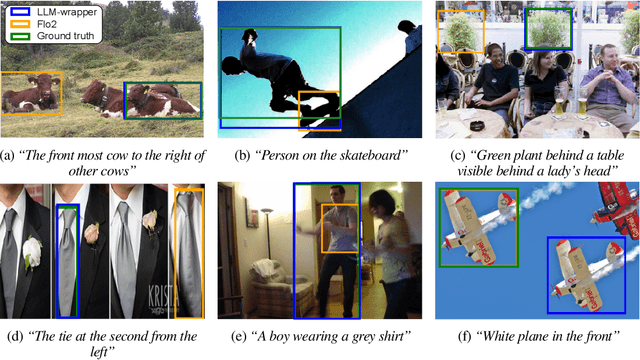
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with limitations as it requires `white-box' access to the model's architecture and weights as well as expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a `black-box' manner by leveraging large language models (LLMs) so as to reason on their outputs. We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, resulting in competitive results when compared with classic fine-tuning.