 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Transfer Learning between Biological Foundation Models
Jun 20, 2024



Biological sequences encode fundamental instructions for the building blocks of life, in the form of DNA, RNA, and proteins. Modeling these sequences is key to understand disease mechanisms and is an active research area in computational biology. Recently, Large Language Models have shown great promise in solving certain biological tasks but current approaches are limited to a single sequence modality (DNA, RNA, or protein). Key problems in genomics intrinsically involve multiple modalities, but it remains unclear how to adapt general-purpose sequence models to those cases. In this work we propose a multi-modal model that connects DNA, RNA, and proteins by leveraging information from different pre-trained modality-specific encoders. We demonstrate its capabilities by applying it to the largely unsolved problem of predicting how multiple RNA transcript isoforms originate from the same gene (i.e. same DNA sequence) and map to different transcription expression levels across various human tissues. We show that our model, dubbed IsoFormer, is able to accurately predict differential transcript expression, outperforming existing methods and leveraging the use of multiple modalities. Our framework also achieves efficient transfer knowledge from the encoders pre-training as well as in between modalities. We open-source our model, paving the way for new multi-modal gene expression approaches.
Transductive Zero-Shot Learning using Cross-Modal CycleGAN
Nov 13, 2020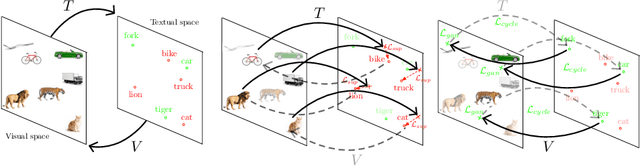
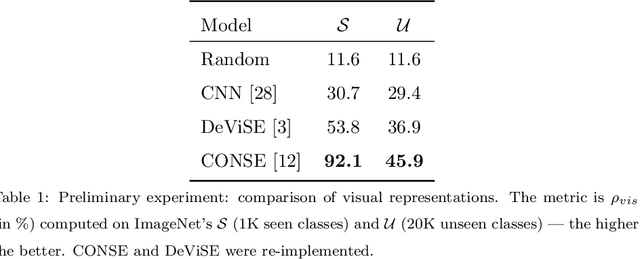
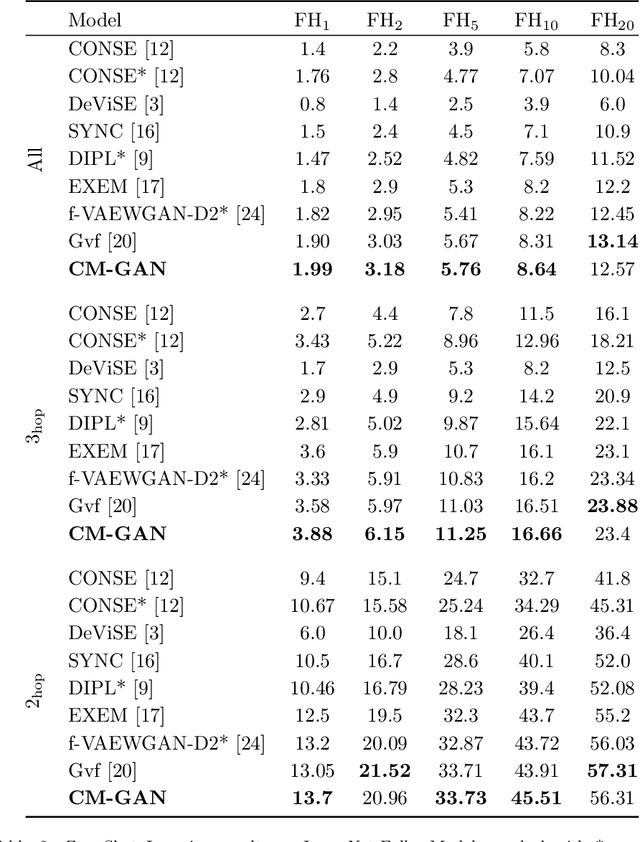
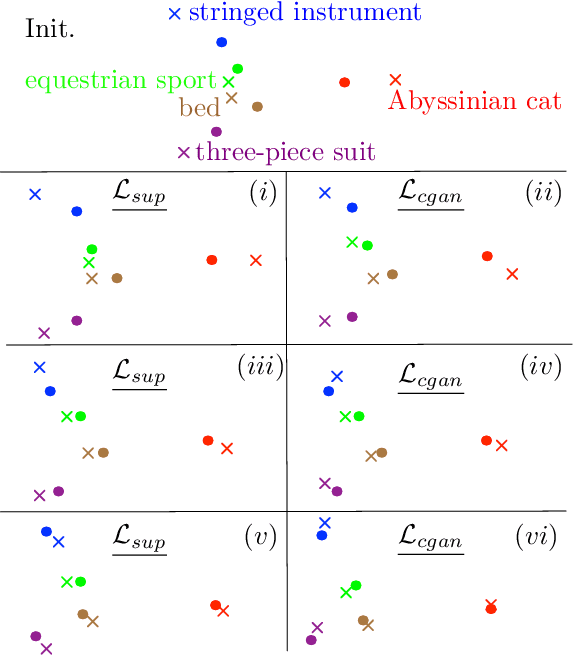
In Computer Vision, Zero-Shot Learning (ZSL) aims at classifying unseen classes -- classes for which no matching training image exists. Most of ZSL works learn a cross-modal mapping between images and class labels for seen classes. However, the data distribution of seen and unseen classes might differ, causing a domain shift problem. Following this observation, transductive ZSL (T-ZSL) assumes that unseen classes and their associated images are known during training, but not their correspondence. As current T-ZSL approaches do not scale efficiently when the number of seen classes is high, we tackle this problem with a new model for T-ZSL based upon CycleGAN. Our model jointly (i) projects images on their seen class labels with a supervised objective and (ii) aligns unseen class labels and visual exemplars with adversarial and cycle-consistency objectives. We show the efficiency of our Cross-Modal CycleGAN model (CM-GAN) on the ImageNet T-ZSL task where we obtain state-of-the-art results. We further validate CM-GAN on a language grounding task, and on a new task that we propose: zero-shot sentence-to-image matching on MS COCO.
BERT Can See Out of the Box: On the Cross-modal Transferability of Text Representations
Feb 25, 2020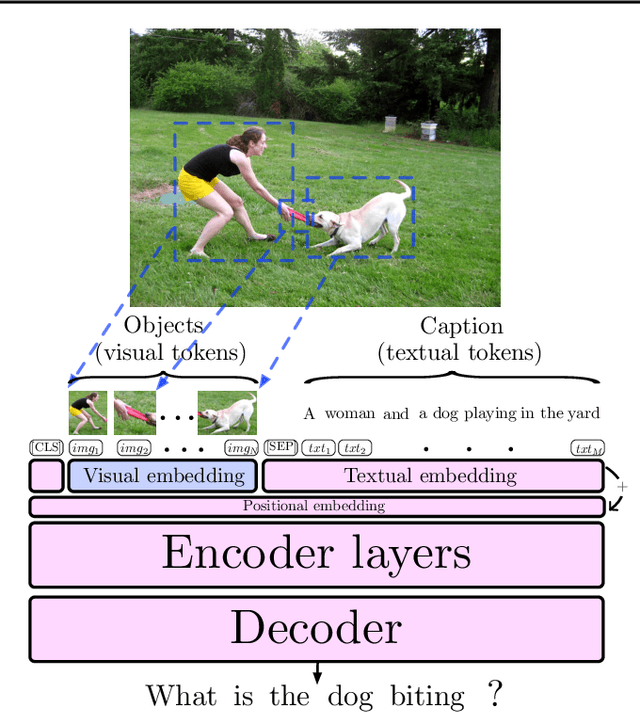
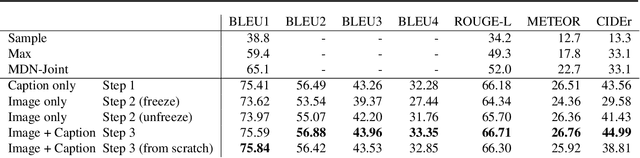
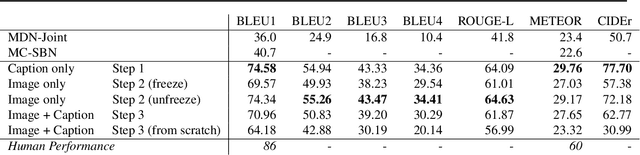

Pre-trained language models such as BERT have recently contributed to significant advances in Natural Language Processing tasks. Interestingly, while multilingual BERT models have demonstrated impressive results, recent works have shown how monolingual BERT can also be competitive in zero-shot cross-lingual settings. This suggests that the abstractions learned by these models can transfer across languages, even when trained on monolingual data. In this paper, we investigate whether such generalization potential applies to other modalities, such as vision: does BERT contain abstractions that generalize beyond text? We introduce BERT-gen, an architecture for text generation based on BERT, able to leverage on either mono- or multi- modal representations. The results reported under different configurations indicate a positive answer to our research question, and the proposed model obtains substantial improvements over the state-of-the-art on two established Visual Question Generation datasets.
Incorporating Visual Semantics into Sentence Representations within a Grounded Space
Feb 07, 2020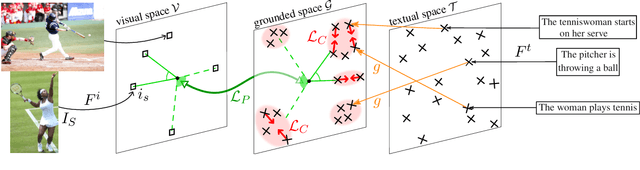
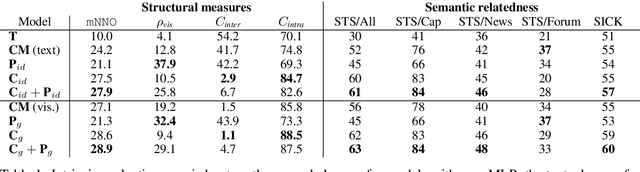


Language grounding is an active field aiming at enriching textual representations with visual information. Generally, textual and visual elements are embedded in the same representation space, which implicitly assumes a one-to-one correspondence between modalities. This hypothesis does not hold when representing words, and becomes problematic when used to learn sentence representations --- the focus of this paper --- as a visual scene can be described by a wide variety of sentences. To overcome this limitation, we propose to transfer visual information to textual representations by learning an intermediate representation space: the grounded space. We further propose two new complementary objectives ensuring that (1) sentences associated with the same visual content are close in the grounded space and (2) similarities between related elements are preserved across modalities. We show that this model outperforms the previous state-of-the-art on classification and semantic relatedness tasks.
Context-Aware Zero-Shot Learning for Object Recognition
Apr 30, 2019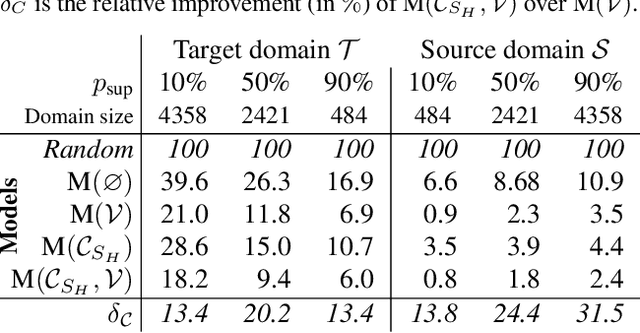
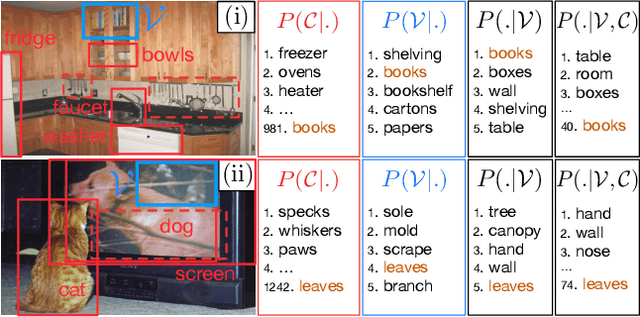
Zero-Shot Learning (ZSL) aims at classifying unlabeled objects by leveraging auxiliary knowledge, such as semantic representations. A limitation of previous approaches is that only intrinsic properties of objects, e.g. their visual appearance, are taken into account while their context, e.g. the surrounding objects in the image, is ignored. Following the intuitive principle that objects tend to be found in certain contexts but not others, we propose a new and challenging approach, context-aware ZSL, that leverages semantic representations in a new way to model the conditional likelihood of an object to appear in a given context. Finally, through extensive experiments conducted on Visual Genome, we show that contextual information can substantially improve the standard ZSL approach and is robust to unbalanced classes.