 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPA: An Information-Preserving Input Projection Framework for Efficient Foundation Model Adaptation
Sep 04, 2025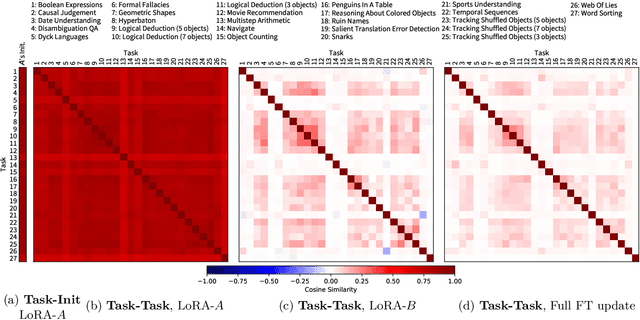
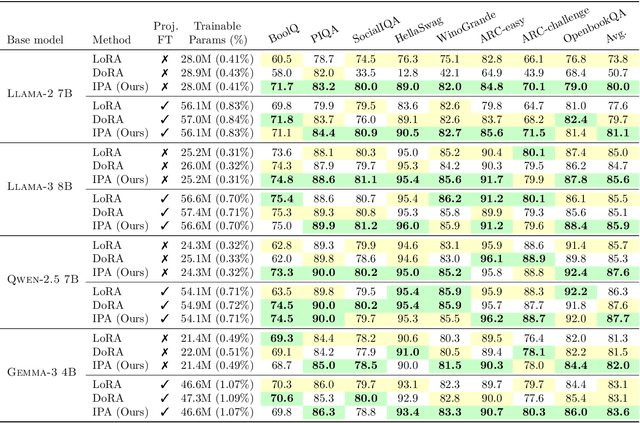
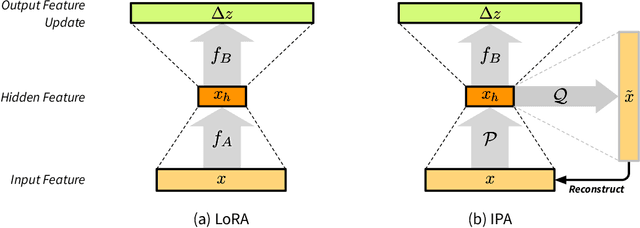
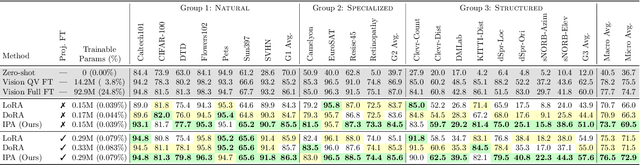
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA's down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly preserves information in the reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen.
Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
Jul 18, 2025



We present Franca (pronounced Fran-ka): free one; the first fully open-source (data, code, weights) vision foundation model that matches and in many cases surpasses the performance of state-of-the-art proprietary models, e.g., DINOv2, CLIP, SigLIPv2, etc. Our approach is grounded in a transparent training pipeline inspired by Web-SSL and uses publicly available data: ImageNet-21K and a subset of ReLAION-2B. Beyond model release, we tackle critical limitations in SSL clustering methods. While modern models rely on assigning image features to large codebooks via clustering algorithms like Sinkhorn-Knopp, they fail to account for the inherent ambiguity in clustering semantics. To address this, we introduce a parameter-efficient, multi-head clustering projector based on nested Matryoshka representations. This design progressively refines features into increasingly fine-grained clusters without increasing the model size, enabling both performance and memory efficiency. Additionally, we propose a novel positional disentanglement strategy that explicitly removes positional biases from dense representations, thereby improving the encoding of semantic content. This leads to consistent gains on several downstream benchmarks, demonstrating the utility of cleaner feature spaces. Our contributions establish a new standard for transparent, high-performance vision models and open a path toward more reproducible and generalizable foundation models for the broader AI community. The code and model checkpoints are available at https://github.com/valeoai/Franca.
MoSiC: Optimal-Transport Motion Trajectory for Dense Self-Supervised Learning
Jun 10, 2025



Dense self-supervised learning has shown great promise for learning pixel- and patch-level representations, but extending it to videos remains challenging due to the complexity of motion dynamics. Existing approaches struggle as they rely on static augmentations that fail under object deformations, occlusions, and camera movement, leading to inconsistent feature learning over time. We propose a motion-guided self-supervised learning framework that clusters dense point tracks to learn spatiotemporally consistent representations. By leveraging an off-the-shelf point tracker, we extract long-range motion trajectories and optimize feature clustering through a momentum-encoder-based optimal transport mechanism. To ensure temporal coherence, we propagate cluster assignments along tracked points, enforcing feature consistency across views despite viewpoint changes. Integrating motion as an implicit supervisory signal, our method learns representations that generalize across frames, improving robustness in dynamic scenes and challenging occlusion scenarios. By initializing from strong image-pretrained models and leveraging video data for training, we improve state-of-the-art by 1% to 6% on six image and video datasets and four evaluation benchmarks. The implementation is publicly available at our GitHub repository: https://github.com/SMSD75/MoSiC/tree/main
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
Embedding Space Interpolation Beyond Mini-Batch, Beyond Pairs and Beyond Examples
Nov 09, 2023Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Its extensions mostly focus on the definition of interpolation and the space (input or feature) where it takes place, while the augmentation process itself is less studied. In most methods, the number of generated examples is limited to the mini-batch size and the number of examples being interpolated is limited to two (pairs), in the input space. We make progress in this direction by introducing MultiMix, which generates an arbitrarily large number of interpolated examples beyond the mini-batch size and interpolates the entire mini-batch in the embedding space. Effectively, we sample on the entire convex hull of the mini-batch rather than along linear segments between pairs of examples. On sequence data, we further extend to Dense MultiMix. We densely interpolate features and target labels at each spatial location and also apply the loss densely. To mitigate the lack of dense labels, we inherit labels from examples and weight interpolation factors by attention as a measure of confidence. Overall, we increase the number of loss terms per mini-batch by orders of magnitude at little additional cost. This is only possible because of interpolating in the embedding space. We empirically show that our solutions yield significant improvement over state-of-the-art mixup methods on four different benchmarks, despite interpolation being only linear. By analyzing the embedding space, we show that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video
Oct 12, 2023Self-supervised learning has unlocked the potential of scaling up pretraining to billions of images, since annotation is unnecessary. But are we making the best use of data? How more economical can we be? In this work, we attempt to answer this question by making two contributions. First, we investigate first-person videos and introduce a "Walking Tours" dataset. These videos are high-resolution, hours-long, captured in a single uninterrupted take, depicting a large number of objects and actions with natural scene transitions. They are unlabeled and uncurated, thus realistic for self-supervision and comparable with human learning. Second, we introduce a novel self-supervised image pretraining method tailored for learning from continuous videos. Existing methods typically adapt image-based pretraining approaches to incorporate more frames. Instead, we advocate a "tracking to learn to recognize" approach. Our method called DoRA, leads to attention maps that Discover and tRAck objects over time in an end-to-end manner, using transformer cross-attention. We derive multiple views from the tracks and use them in a classical self-supervised distillation loss. Using our novel approach, a single Walking Tours video remarkably becomes a strong competitor to ImageNet for several image and video downstream tasks.
Skip-Attention: Improving Vision Transformers by Paying Less Attention
Jan 17, 2023



This work aims to improve the efficiency of vision transformers (ViT). While ViTs use computationally expensive self-attention operations in every layer, we identify that these operations are highly correlated across layers -- a key redundancy that causes unnecessary computations. Based on this observation, we propose SkipAt, a method to reuse self-attention computation from preceding layers to approximate attention at one or more subsequent layers. To ensure that reusing self-attention blocks across layers does not degrade the performance, we introduce a simple parametric function, which outperforms the baseline transformer's performance while running computationally faster. We show the effectiveness of our method in image classification and self-supervised learning on ImageNet-1K, semantic segmentation on ADE20K, image denoising on SIDD, and video denoising on DAVIS. We achieve improved throughput at the same-or-higher accuracy levels in all these tasks.
Teach me how to Interpolate a Myriad of Embeddings
Jun 29, 2022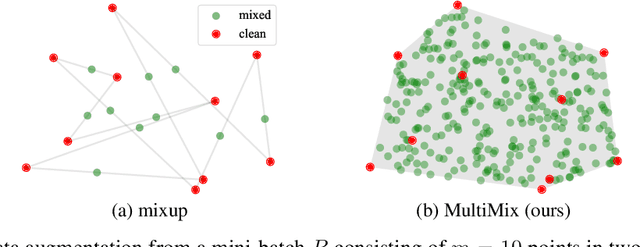
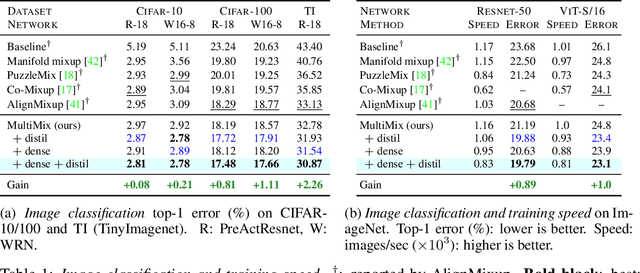
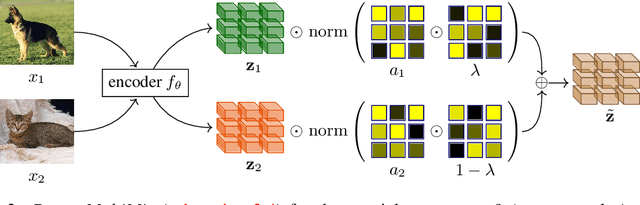
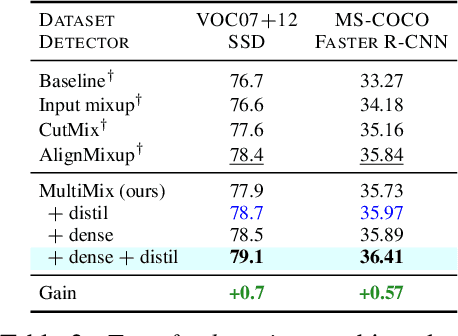
Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Yet, its extensions focus on the definition of interpolation and the space where it takes place, while the augmentation itself is less studied: For a mini-batch of size $m$, most methods interpolate between $m$ pairs with a single scalar interpolation factor $\lambda$. In this work, we make progress in this direction by introducing MultiMix, which interpolates an arbitrary number $n$ of tuples, each of length $m$, with one vector $\lambda$ per tuple. On sequence data, we further extend to dense interpolation and loss computation over all spatial positions. Overall, we increase the number of tuples per mini-batch by orders of magnitude at little additional cost. This is possible by interpolating at the very last layer before the classifier. Finally, to address inconsistencies due to linear target interpolation, we introduce a self-distillation approach to generate and interpolate synthetic targets. We empirically show that our contributions result in significant improvement over state-of-the-art mixup methods on four benchmarks. By analyzing the embedding space, we observe that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
It Takes Two to Tango: Mixup for Deep Metric Learning
Jun 09, 2021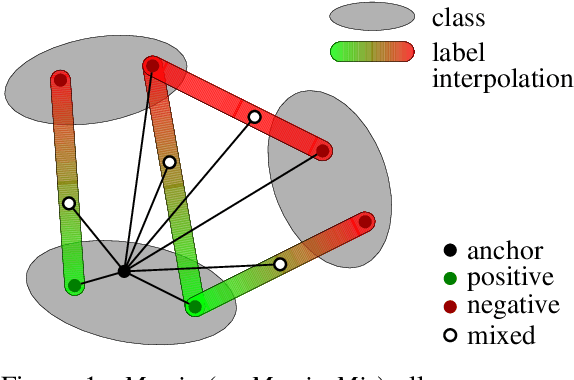

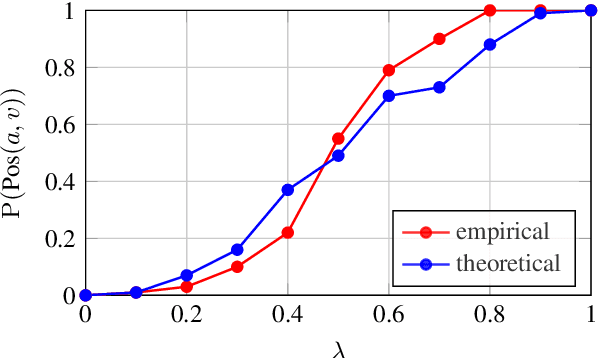
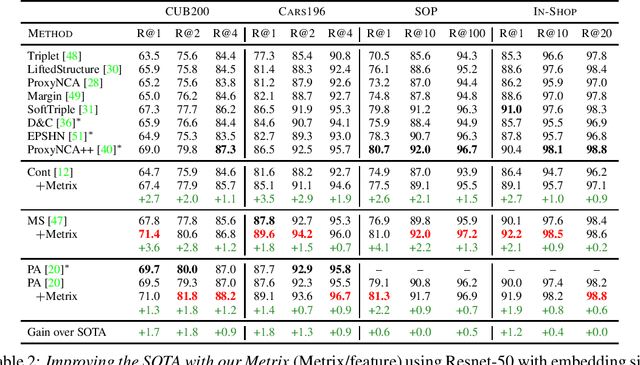
Metric learning involves learning a discriminative representation such that embeddings of similar classes are encouraged to be close, while embeddings of dissimilar classes are pushed far apart. State-of-the-art methods focus mostly on sophisticated loss functions or mining strategies. On the one hand, metric learning losses consider two or more examples at a time. On the other hand, modern data augmentation methods for classification consider two or more examples at a time. The combination of the two ideas is under-studied. In this work, we aim to bridge this gap and improve representations using mixup, which is a powerful data augmentation approach interpolating two or more examples and corresponding target labels at a time. This task is challenging because, unlike classification, the loss functions used in metric learning are not additive over examples, so the idea of interpolating target labels is not straightforward. To the best of our knowledge, we are the first to investigate mixing examples and target labels for deep metric learning. We develop a generalized formulation that encompasses existing metric learning loss functions and modify it to accommodate for mixup, introducing Metric Mix, or Metrix. We show that mixing inputs, intermediate representations or embeddings along with target labels significantly improves representations and outperforms state-of-the-art metric learning methods on four benchmark datasets.
AlignMix: Improving representation by interpolating aligned features
Mar 29, 2021
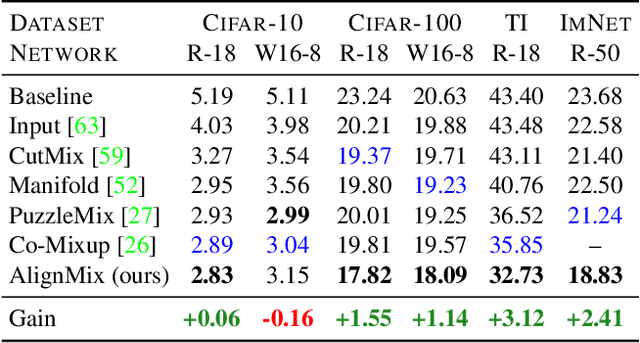
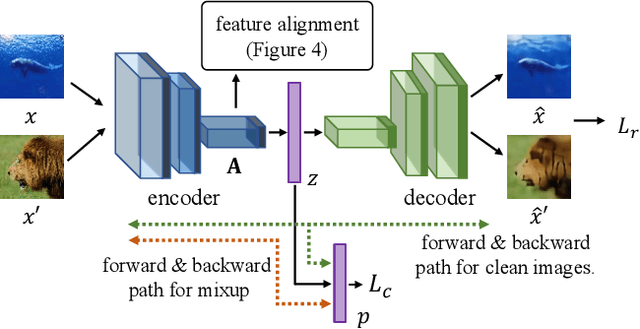
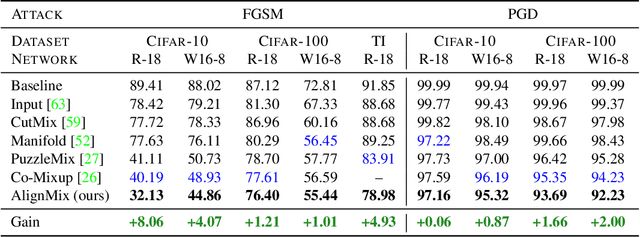
Mixup is a powerful data augmentation method that interpolates between two or more examples in the input or feature space and between the corresponding target labels. Many recent mixup methods focus on cutting and pasting two or more objects into one image, which is more about efficient processing than interpolation. However, how to best interpolate images is not well defined. In this sense, mixup has been connected to autoencoders, because often autoencoders "interpolate well", for instance generating an image that continuously deforms into another. In this work, we revisit mixup from the interpolation perspective and introduce AlignMix, where we geometrically align two images in the feature space. The correspondences allow us to interpolate between two sets of features, while keeping the locations of one set. Interestingly, this gives rise to a situation where mixup retains mostly the geometry or pose of one image and the texture of the other, connecting it to style transfer. More than that, we show that an autoencoder can still improve representation learning under mixup, without the classifier ever seeing decoded images. AlignMix outperforms state-of-the-art mixup methods on five different benchmarks.