 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignMix: Improving representation by interpolating aligned features
Paper and Code

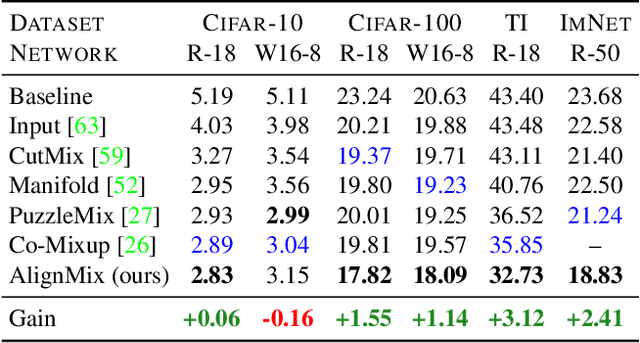
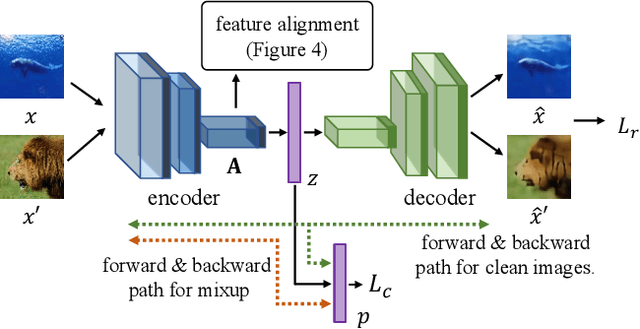
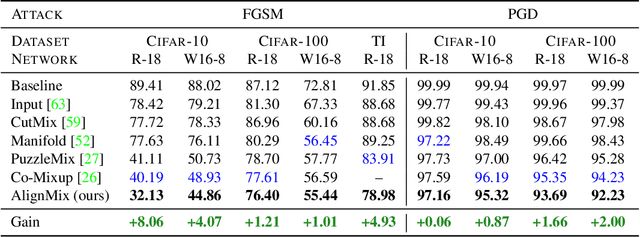
Mixup is a powerful data augmentation method that interpolates between two or more examples in the input or feature space and between the corresponding target labels. Many recent mixup methods focus on cutting and pasting two or more objects into one image, which is more about efficient processing than interpolation. However, how to best interpolate images is not well defined. In this sense, mixup has been connected to autoencoders, because often autoencoders "interpolate well", for instance generating an image that continuously deforms into another. In this work, we revisit mixup from the interpolation perspective and introduce AlignMix, where we geometrically align two images in the feature space. The correspondences allow us to interpolate between two sets of features, while keeping the locations of one set. Interestingly, this gives rise to a situation where mixup retains mostly the geometry or pose of one image and the texture of the other, connecting it to style transfer. More than that, we show that an autoencoder can still improve representation learning under mixup, without the classifier ever seeing decoded images. AlignMix outperforms state-of-the-art mixup methods on five different benchmarks.