 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Secure, and High-Capacity Image Watermarking with Autoencoded Text Vectors
Oct 01, 2025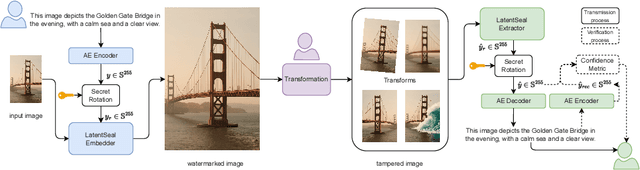
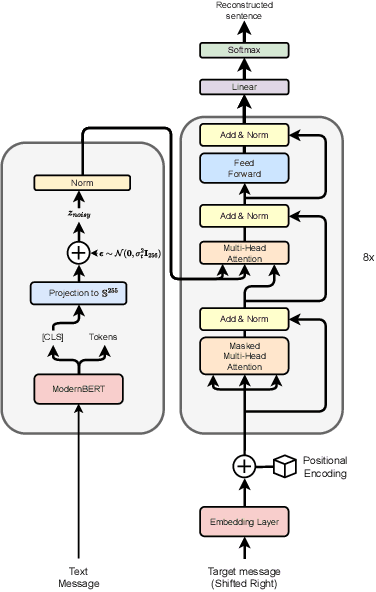
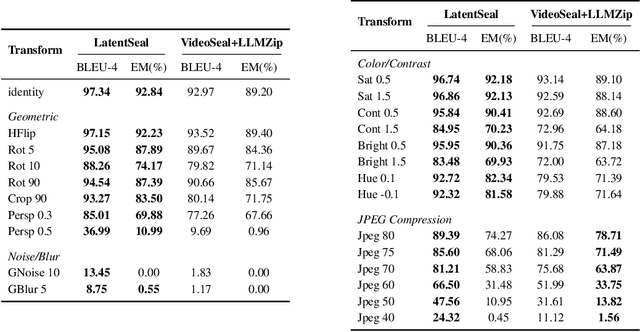
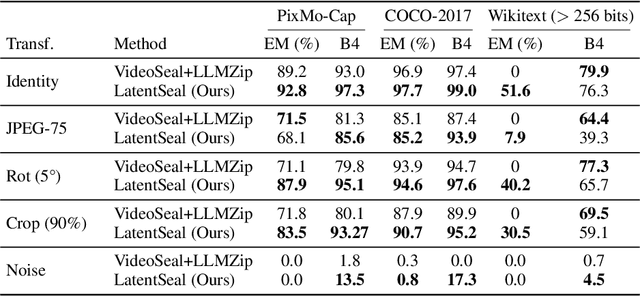
Most image watermarking systems focus on robustness, capacity, and imperceptibility while treating the embedded payload as meaningless bits. This bit-centric view imposes a hard ceiling on capacity and prevents watermarks from carrying useful information. We propose LatentSeal, which reframes watermarking as semantic communication: a lightweight text autoencoder maps full-sentence messages into a compact 256-dimensional unit-norm latent vector, which is robustly embedded by a finetuned watermark model and secured through a secret, invertible rotation. The resulting system hides full-sentence messages, decodes in real time, and survives valuemetric and geometric attacks. It surpasses prior state of the art in BLEU-4 and Exact Match on several benchmarks, while breaking through the long-standing 256-bit payload ceiling. It also introduces a statistically calibrated score that yields a ROC AUC score of 0.97-0.99, and practical operating points for deployment. By shifting from bit payloads to semantic latent vectors, LatentSeal enables watermarking that is not only robust and high-capacity, but also secure and interpretable, providing a concrete path toward provenance, tamper explanation, and trustworthy AI governance. Models, training and inference code, and data splits will be available upon publication.
Flyweight FLIM Networks for Salient Object Detection in Biomedical Images
Apr 15, 2025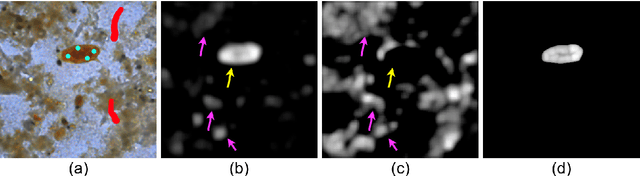

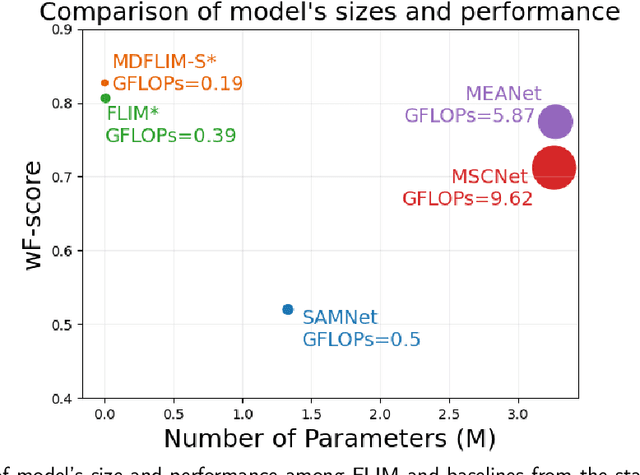
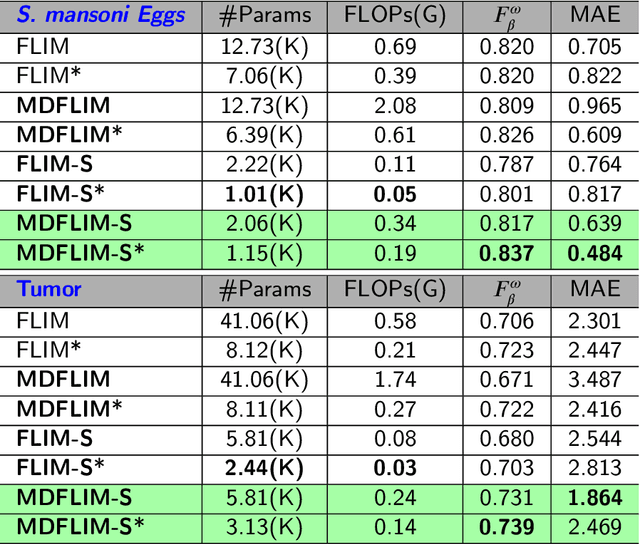
Salient Object Detection (SOD) with deep learning often requires substantial computational resources and large annotated datasets, making it impractical for resource-constrained applications. Lightweight models address computational demands but typically strive in complex and scarce labeled-data scenarios. Feature Learning from Image Markers (FLIM) learns an encoder's convolutional kernels among image patches extracted from discriminative regions marked on a few representative images, dismissing large annotated datasets, pretraining, and backpropagation. Such a methodology exploits information redundancy commonly found in biomedical image applications. This study presents methods to learn dilated-separable convolutional kernels and multi-dilation layers without backpropagation for FLIM networks. It also proposes a novel network simplification method to reduce kernel redundancy and encoder size. By combining a FLIM encoder with an adaptive decoder, a concept recently introduced to estimate a pointwise convolution per image, this study presents very efficient (named flyweight) SOD models for biomedical images. Experimental results in challenging datasets demonstrate superior efficiency and effectiveness to lightweight models. By requiring significantly fewer parameters and floating-point operations, the results show competitive effectiveness to heavyweight models. These advances highlight the potential of FLIM networks for data-limited and resource-constrained applications with information redundancy.
Reframing Image Difference Captioning with BLIP2IDC and Synthetic Augmentation
Dec 20, 2024
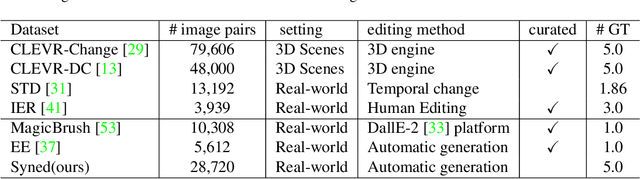

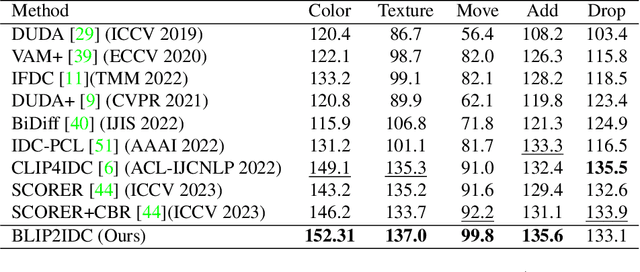
The rise of the generative models quality during the past years enabled the generation of edited variations of images at an important scale. To counter the harmful effects of such technology, the Image Difference Captioning (IDC) task aims to describe the differences between two images. While this task is successfully handled for simple 3D rendered images, it struggles on real-world images. The reason is twofold: the training data-scarcity, and the difficulty to capture fine-grained differences between complex images. To address those issues, we propose in this paper a simple yet effective framework to both adapt existing image captioning models to the IDC task and augment IDC datasets. We introduce BLIP2IDC, an adaptation of BLIP2 to the IDC task at low computational cost, and show it outperforms two-streams approaches by a significant margin on real-world IDC datasets. We also propose to use synthetic augmentation to improve the performance of IDC models in an agnostic fashion. We show that our synthetic augmentation strategy provides high quality data, leading to a challenging new dataset well-suited for IDC named Syned1.
SWIFT: Semantic Watermarking for Image Forgery Thwarting
Jul 26, 2024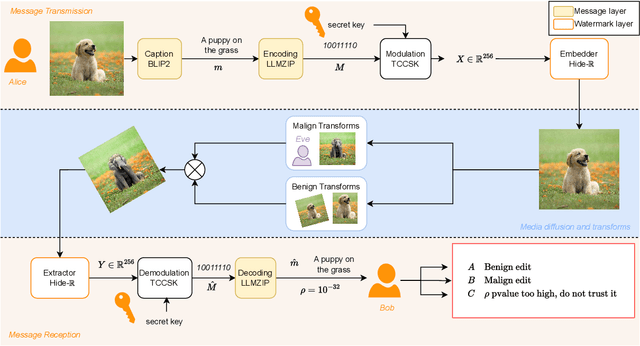
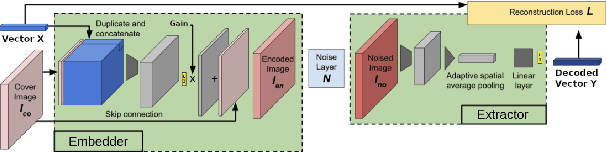
This paper proposes a novel approach towards image authentication and tampering detection by using watermarking as a communication channel for semantic information. We modify the HiDDeN deep-learning watermarking architecture to embed and extract high-dimensional real vectors representing image captions. Our method improves significantly robustness on both malign and benign edits. We also introduce a local confidence metric correlated with Message Recovery Rate, enhancing the method's practical applicability. This approach bridges the gap between traditional watermarking and passive forensic methods, offering a robust solution for image integrity verification.
Distinctive Image Captioning: Leveraging Ground Truth Captions in CLIP Guided Reinforcement Learning
Feb 21, 2024
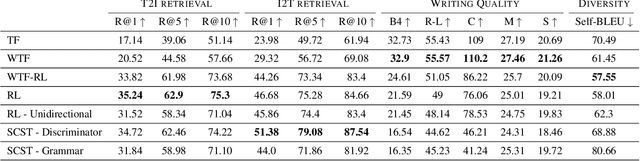
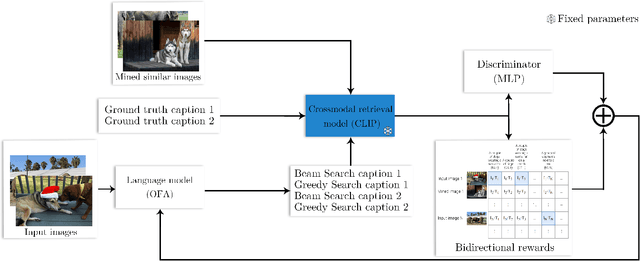
Training image captioning models using teacher forcing results in very generic samples, whereas more distinctive captions can be very useful in retrieval applications or to produce alternative texts describing images for accessibility. Reinforcement Learning (RL) allows to use cross-modal retrieval similarity score between the generated caption and the input image as reward to guide the training, leading to more distinctive captions. Recent studies show that pre-trained cross-modal retrieval models can be used to provide this reward, completely eliminating the need for reference captions. However, we argue in this paper that Ground Truth (GT) captions can still be useful in this RL framework. We propose a new image captioning model training strategy that makes use of GT captions in different ways. Firstly, they can be used to train a simple MLP discriminator that serves as a regularization to prevent reward hacking and ensures the fluency of generated captions, resulting in a textual GAN setup extended for multimodal inputs. Secondly, they can serve as additional trajectories in the RL strategy, resulting in a teacher forcing loss weighted by the similarity of the GT to the image. This objective acts as an additional learning signal grounded to the distribution of the GT captions. Thirdly, they can serve as strong baselines when added to the pool of captions used to compute the proposed contrastive reward to reduce the variance of gradient estimate. Experiments on MS-COCO demonstrate the interest of the proposed training strategy to produce highly distinctive captions while maintaining high writing quality.
Embedding Space Interpolation Beyond Mini-Batch, Beyond Pairs and Beyond Examples
Nov 09, 2023Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Its extensions mostly focus on the definition of interpolation and the space (input or feature) where it takes place, while the augmentation process itself is less studied. In most methods, the number of generated examples is limited to the mini-batch size and the number of examples being interpolated is limited to two (pairs), in the input space. We make progress in this direction by introducing MultiMix, which generates an arbitrarily large number of interpolated examples beyond the mini-batch size and interpolates the entire mini-batch in the embedding space. Effectively, we sample on the entire convex hull of the mini-batch rather than along linear segments between pairs of examples. On sequence data, we further extend to Dense MultiMix. We densely interpolate features and target labels at each spatial location and also apply the loss densely. To mitigate the lack of dense labels, we inherit labels from examples and weight interpolation factors by attention as a measure of confidence. Overall, we increase the number of loss terms per mini-batch by orders of magnitude at little additional cost. This is only possible because of interpolating in the embedding space. We empirically show that our solutions yield significant improvement over state-of-the-art mixup methods on four different benchmarks, despite interpolation being only linear. By analyzing the embedding space, we show that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
MAAIP: Multi-Agent Adversarial Interaction Priors for imitation from fighting demonstrations for physics-based characters
Nov 04, 2023



Simulating realistic interaction and motions for physics-based characters is of great interest for interactive applications, and automatic secondary character animation in the movie and video game industries. Recent works in reinforcement learning have proposed impressive results for single character simulation, especially the ones that use imitation learning based techniques. However, imitating multiple characters interactions and motions requires to also model their interactions. In this paper, we propose a novel Multi-Agent Generative Adversarial Imitation Learning based approach that generalizes the idea of motion imitation for one character to deal with both the interaction and the motions of the multiple physics-based characters. Two unstructured datasets are given as inputs: 1) a single-actor dataset containing motions of a single actor performing a set of motions linked to a specific application, and 2) an interaction dataset containing a few examples of interactions between multiple actors. Based on these datasets, our system trains control policies allowing each character to imitate the interactive skills associated with each actor, while preserving the intrinsic style. This approach has been tested on two different fighting styles, boxing and full-body martial art, to demonstrate the ability of the method to imitate different styles.
* SCA'23, Supplementary video: https://youtu.be/wQfIiw_rQ3w
A Flyweight CNN with Adaptive Decoder for Schistosoma mansoni Egg Detection
Jun 26, 2023



Schistosomiasis mansoni is an endemic parasitic disease in more than seventy countries, whose diagnosis is commonly performed by visually counting the parasite eggs in microscopy images of fecal samples. State-of-the-art (SOTA) object detection algorithms are based on heavyweight neural networks, unsuitable for automating the diagnosis in the laboratory routine. We circumvent the problem by presenting a flyweight Convolutional Neural Network (CNN) that weighs thousands of times less than SOTA object detectors. The kernels in our approach are learned layer-by-layer from attention regions indicated by user-drawn scribbles on very few training images. Representative kernels are visually identified and selected to improve performance with reduced computational cost. Another innovation is a single-layer adaptive decoder whose convolutional weights are automatically defined for each image on-the-fly. The experiments show that our CNN can outperform three SOTA baselines according to five measures, being also suitable for CPU execution in the laboratory routine, processing approximately four images a second for each available thread.
Teach me how to Interpolate a Myriad of Embeddings
Jun 29, 2022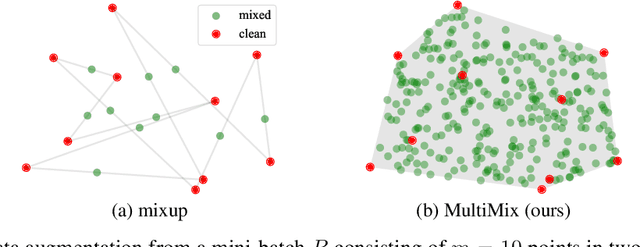
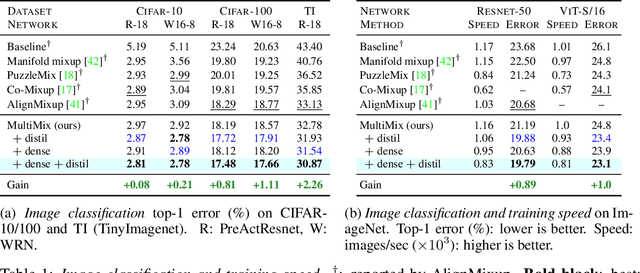
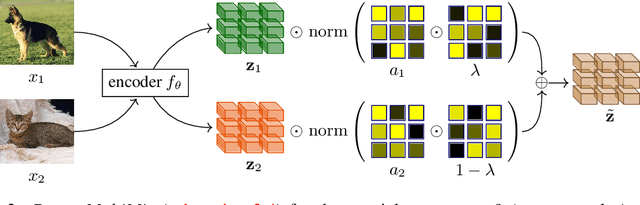
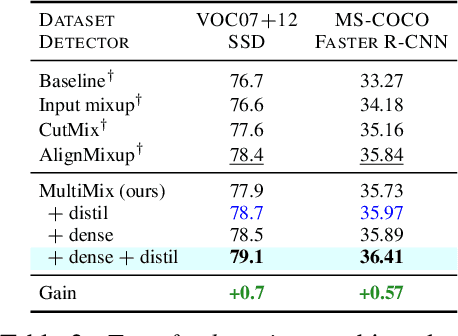
Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Yet, its extensions focus on the definition of interpolation and the space where it takes place, while the augmentation itself is less studied: For a mini-batch of size $m$, most methods interpolate between $m$ pairs with a single scalar interpolation factor $\lambda$. In this work, we make progress in this direction by introducing MultiMix, which interpolates an arbitrary number $n$ of tuples, each of length $m$, with one vector $\lambda$ per tuple. On sequence data, we further extend to dense interpolation and loss computation over all spatial positions. Overall, we increase the number of tuples per mini-batch by orders of magnitude at little additional cost. This is possible by interpolating at the very last layer before the classifier. Finally, to address inconsistencies due to linear target interpolation, we introduce a self-distillation approach to generate and interpolate synthetic targets. We empirically show that our contributions result in significant improvement over state-of-the-art mixup methods on four benchmarks. By analyzing the embedding space, we observe that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
Which Discriminator for Cooperative Text Generation?
Apr 25, 2022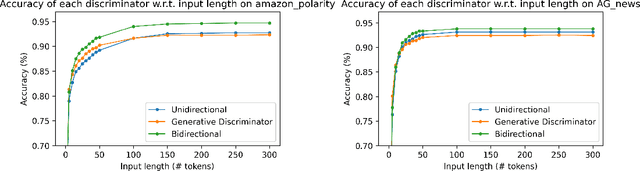

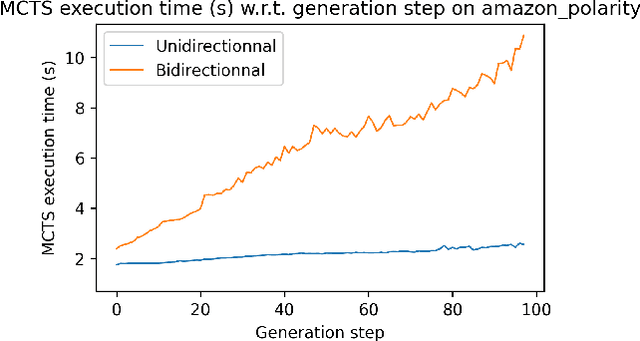
Language models generate texts by successively predicting probability distributions for next tokens given past ones. A growing field of interest tries to leverage external information in the decoding process so that the generated texts have desired properties, such as being more natural, non toxic, faithful, or having a specific writing style. A solution is to use a classifier at each generation step, resulting in a cooperative environment where the classifier guides the decoding of the language model distribution towards relevant texts for the task at hand. In this paper, we examine three families of (transformer-based) discriminators for this specific task of cooperative decoding: bidirectional, left-to-right and generative ones. We evaluate the pros and cons of these different types of discriminators for cooperative generation, exploring respective accuracy on classification tasks along with their impact on the resulting sample quality and computational performances. We also provide the code of a batched implementation of the powerful cooperative decoding strategy used for our experiments, the Monte Carlo Tree Search, working with each discriminator for Natural Language Generation.