 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReframing Image Difference Captioning with BLIP2IDC and Synthetic Augmentation
Paper and Code

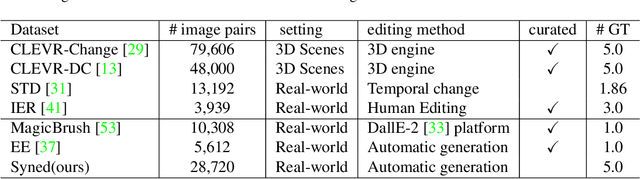

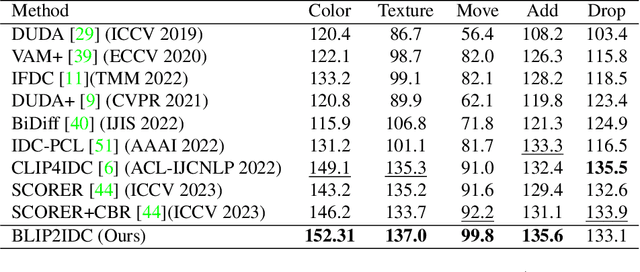
The rise of the generative models quality during the past years enabled the generation of edited variations of images at an important scale. To counter the harmful effects of such technology, the Image Difference Captioning (IDC) task aims to describe the differences between two images. While this task is successfully handled for simple 3D rendered images, it struggles on real-world images. The reason is twofold: the training data-scarcity, and the difficulty to capture fine-grained differences between complex images. To address those issues, we propose in this paper a simple yet effective framework to both adapt existing image captioning models to the IDC task and augment IDC datasets. We introduce BLIP2IDC, an adaptation of BLIP2 to the IDC task at low computational cost, and show it outperforms two-streams approaches by a significant margin on real-world IDC datasets. We also propose to use synthetic augmentation to improve the performance of IDC models in an agnostic fashion. We show that our synthetic augmentation strategy provides high quality data, leading to a challenging new dataset well-suited for IDC named Syned1.