 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Secure, and High-Capacity Image Watermarking with Autoencoded Text Vectors
Oct 01, 2025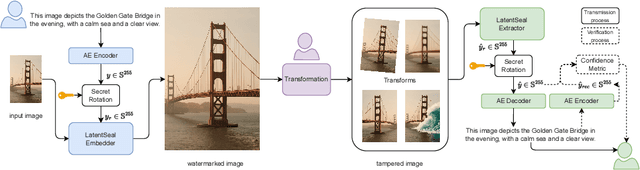
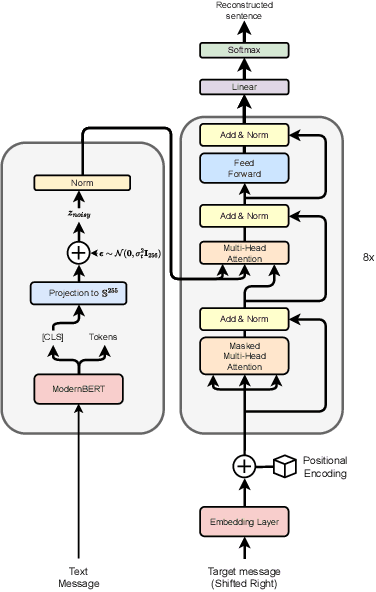
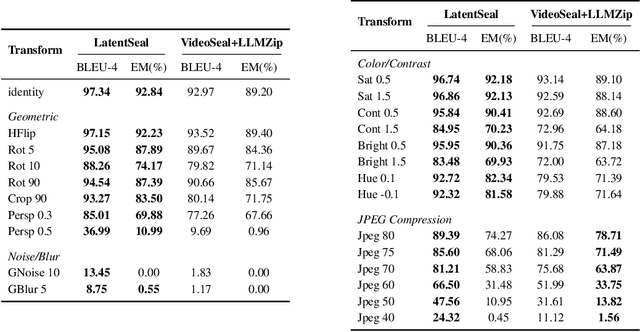
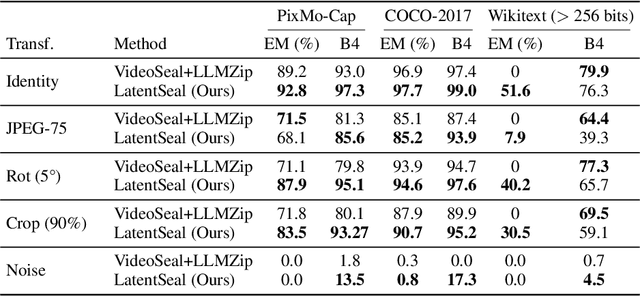
Most image watermarking systems focus on robustness, capacity, and imperceptibility while treating the embedded payload as meaningless bits. This bit-centric view imposes a hard ceiling on capacity and prevents watermarks from carrying useful information. We propose LatentSeal, which reframes watermarking as semantic communication: a lightweight text autoencoder maps full-sentence messages into a compact 256-dimensional unit-norm latent vector, which is robustly embedded by a finetuned watermark model and secured through a secret, invertible rotation. The resulting system hides full-sentence messages, decodes in real time, and survives valuemetric and geometric attacks. It surpasses prior state of the art in BLEU-4 and Exact Match on several benchmarks, while breaking through the long-standing 256-bit payload ceiling. It also introduces a statistically calibrated score that yields a ROC AUC score of 0.97-0.99, and practical operating points for deployment. By shifting from bit payloads to semantic latent vectors, LatentSeal enables watermarking that is not only robust and high-capacity, but also secure and interpretable, providing a concrete path toward provenance, tamper explanation, and trustworthy AI governance. Models, training and inference code, and data splits will be available upon publication.
Guidance Watermarking for Diffusion Models
Sep 26, 2025



This paper introduces a novel watermarking method for diffusion models. It is based on guiding the diffusion process using the gradient computed from any off-the-shelf watermark decoder. The gradient computation encompasses different image augmentations, increasing robustness to attacks against which the decoder was not originally robust, without retraining or fine-tuning. Our method effectively convert any \textit{post-hoc} watermarking scheme into an in-generation embedding along the diffusion process. We show that this approach is complementary to watermarking techniques modifying the variational autoencoder at the end of the diffusion process. We validate the methods on different diffusion models and detectors. The watermarking guidance does not significantly alter the generated image for a given seed and prompt, preserving both the diversity and quality of generation.
Reframing Image Difference Captioning with BLIP2IDC and Synthetic Augmentation
Dec 20, 2024
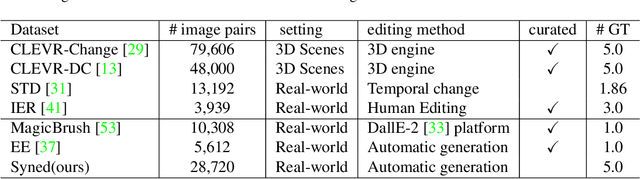

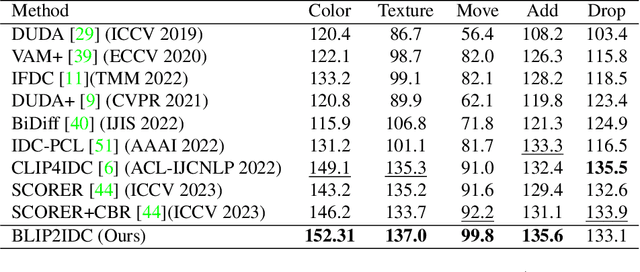
The rise of the generative models quality during the past years enabled the generation of edited variations of images at an important scale. To counter the harmful effects of such technology, the Image Difference Captioning (IDC) task aims to describe the differences between two images. While this task is successfully handled for simple 3D rendered images, it struggles on real-world images. The reason is twofold: the training data-scarcity, and the difficulty to capture fine-grained differences between complex images. To address those issues, we propose in this paper a simple yet effective framework to both adapt existing image captioning models to the IDC task and augment IDC datasets. We introduce BLIP2IDC, an adaptation of BLIP2 to the IDC task at low computational cost, and show it outperforms two-streams approaches by a significant margin on real-world IDC datasets. We also propose to use synthetic augmentation to improve the performance of IDC models in an agnostic fashion. We show that our synthetic augmentation strategy provides high quality data, leading to a challenging new dataset well-suited for IDC named Syned1.
SWIFT: Semantic Watermarking for Image Forgery Thwarting
Jul 26, 2024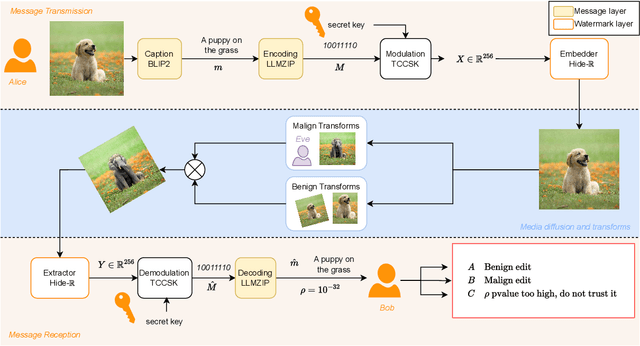
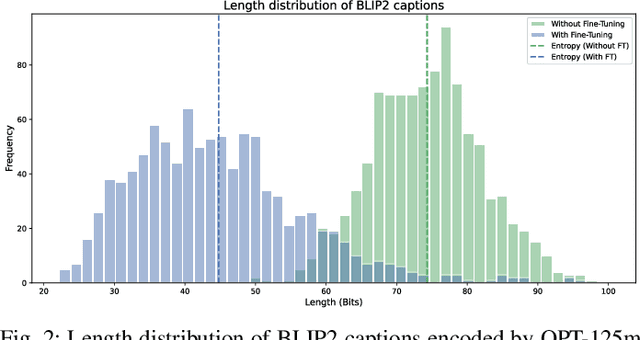
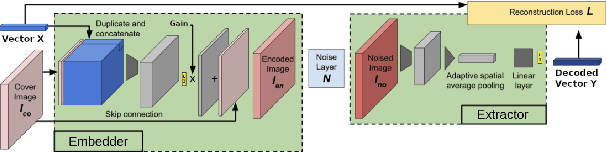
This paper proposes a novel approach towards image authentication and tampering detection by using watermarking as a communication channel for semantic information. We modify the HiDDeN deep-learning watermarking architecture to embed and extract high-dimensional real vectors representing image captions. Our method improves significantly robustness on both malign and benign edits. We also introduce a local confidence metric correlated with Message Recovery Rate, enhancing the method's practical applicability. This approach bridges the gap between traditional watermarking and passive forensic methods, offering a robust solution for image integrity verification.
Three Bricks to Consolidate Watermarks for Large Language Models
Jul 26, 2023The task of discerning between generated and natural texts is increasingly challenging. In this context, watermarking emerges as a promising technique for ascribing generated text to a specific model. It alters the sampling generation process so as to leave an invisible trace in the generated output, facilitating later detection. This research consolidates watermarks for large language models based on three theoretical and empirical considerations. First, we introduce new statistical tests that offer robust theoretical guarantees which remain valid even at low false-positive rates (less than 10$^{\text{-6}}$). Second, we compare the effectiveness of watermarks using classical benchmarks in the field of natural language processing, gaining insights into their real-world applicability. Third, we develop advanced detection schemes for scenarios where access to the LLM is available, as well as multi-bit watermarking.