 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flyweight CNN with Adaptive Decoder for Schistosoma mansoni Egg Detection
Jun 26, 2023



Schistosomiasis mansoni is an endemic parasitic disease in more than seventy countries, whose diagnosis is commonly performed by visually counting the parasite eggs in microscopy images of fecal samples. State-of-the-art (SOTA) object detection algorithms are based on heavyweight neural networks, unsuitable for automating the diagnosis in the laboratory routine. We circumvent the problem by presenting a flyweight Convolutional Neural Network (CNN) that weighs thousands of times less than SOTA object detectors. The kernels in our approach are learned layer-by-layer from attention regions indicated by user-drawn scribbles on very few training images. Representative kernels are visually identified and selected to improve performance with reduced computational cost. Another innovation is a single-layer adaptive decoder whose convolutional weights are automatically defined for each image on-the-fly. The experiments show that our CNN can outperform three SOTA baselines according to five measures, being also suitable for CPU execution in the laboratory routine, processing approximately four images a second for each available thread.
Saliency Enhancement using Superpixel Similarity
Dec 01, 2021
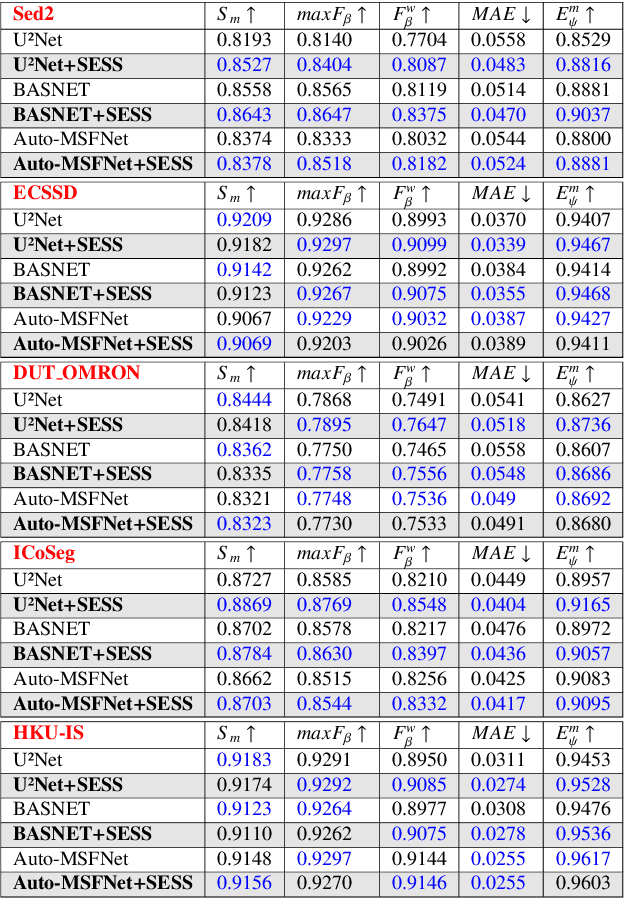

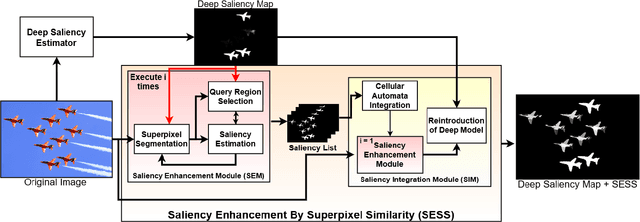
Saliency Object Detection (SOD) has several applications in image analysis. Deep-learning-based SOD methods are among the most effective, but they may miss foreground parts with similar colors. To circumvent the problem, we introduce a post-processing method, named \textit{Saliency Enhancement over Superpixel Similarity} (SESS), which executes two operations alternately for saliency completion: object-based superpixel segmentation and superpixel-based saliency estimation. SESS uses an input saliency map to estimate seeds for superpixel delineation and define superpixel queries in foreground and background. A new saliency map results from color similarities between queries and superpixels. The process repeats for a given number of iterations, such that all generated saliency maps are combined into a single one by cellular automata. Finally, post-processed and initial maps are merged using their average values per superpixel. We demonstrate that SESS can consistently and considerably improve the results of three deep-learning-based SOD methods on five image datasets.
ITSELF: Iterative Saliency Estimation fLexible Framework
Jun 30, 2020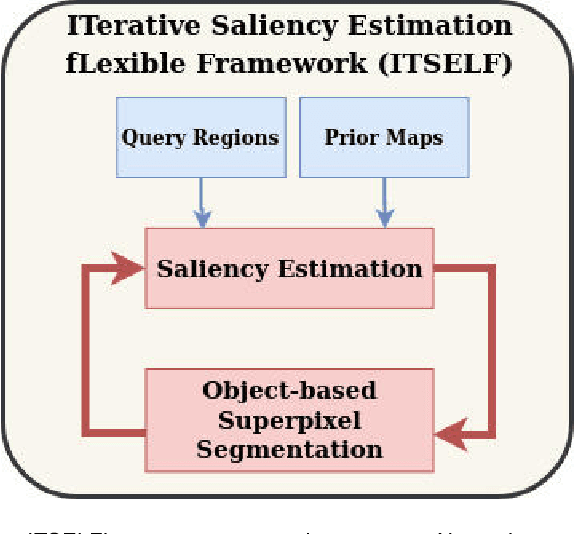
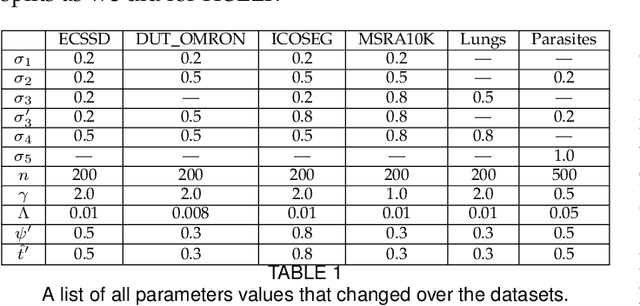
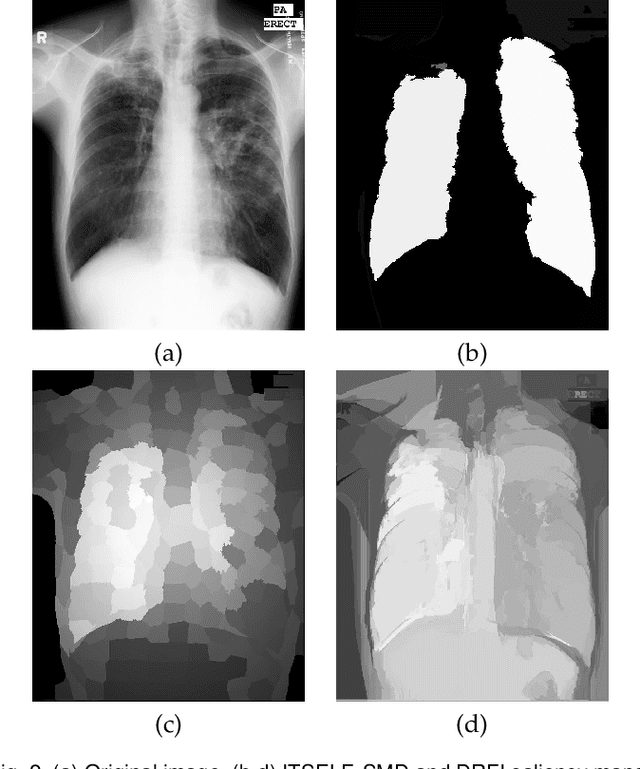
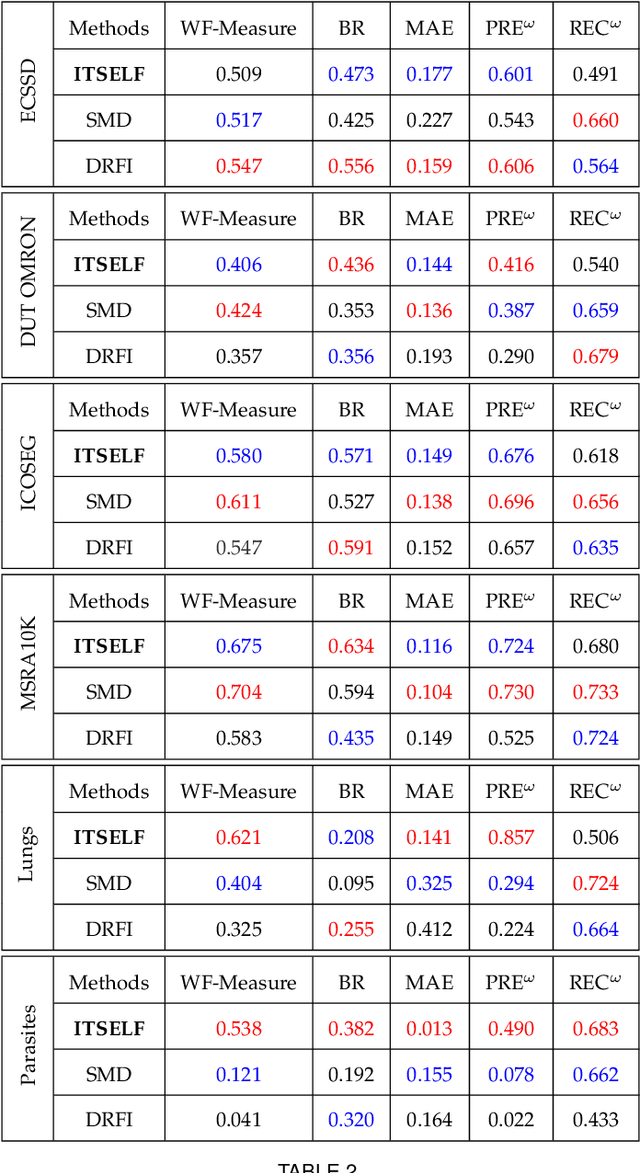
Saliency object detection estimates the objects that most stand out in an image. The available unsupervised saliency estimators rely on a pre-determined set of assumptions of how humans perceive saliency to create discriminating features. By fixing the pre-selected assumptions as integral part of their models, these methods cannot be easily extended for specific settings and different image domains. We then propose an superpixel-based ITerative Saliency Estimation fLexible Framework (ITSELF) that allows any number of user-defined assumptions to be added to the model when required. Thanks to recent advancement on superpixel segmentation algorithms, saliency-maps can be used to improve superpixel delineation. By combining a saliency-based superpixel algorithm to a superpixel-based saliency estimator, we propose a novel saliency/superpixel self-improving loop to iteratively enhance saliency maps. We compared ITSELF to two state-of-the-art saliency estimators on five metrics and six datasets, four of which are composed of natural-images, and two of biomedical-images. Experiments show that our approach is more robust than the compared methods, presenting competitive results on natural-image datasets and outperforming them on biomedical-image datasets.
Deep Representations for Iris, Face, and Fingerprint Spoofing Detection
Jan 29, 2015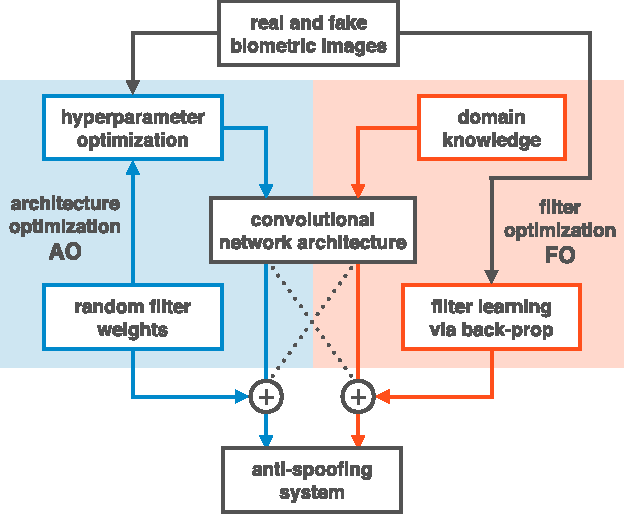
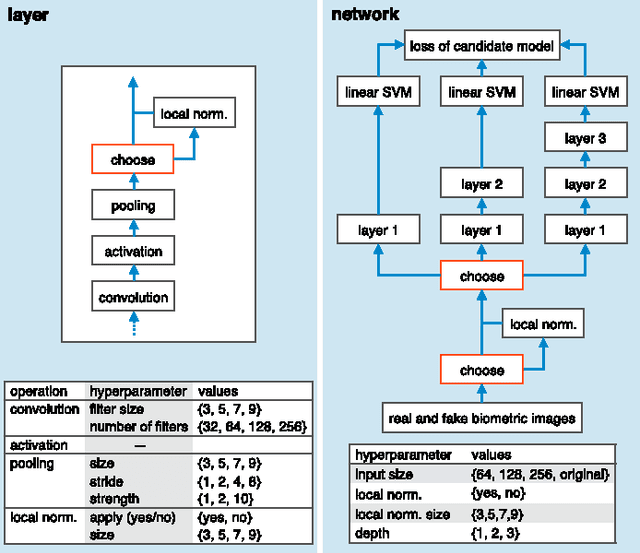
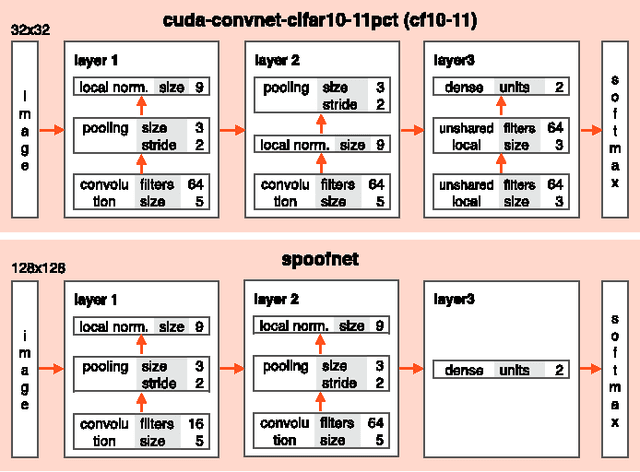

Biometrics systems have significantly improved person identification and authentication, playing an important role in personal, national, and global security. However, these systems might be deceived (or "spoofed") and, despite the recent advances in spoofing detection, current solutions often rely on domain knowledge, specific biometric reading systems, and attack types. We assume a very limited knowledge about biometric spoofing at the sensor to derive outstanding spoofing detection systems for iris, face, and fingerprint modalities based on two deep learning approaches. The first approach consists of learning suitable convolutional network architectures for each domain, while the second approach focuses on learning the weights of the network via back-propagation. We consider nine biometric spoofing benchmarks --- each one containing real and fake samples of a given biometric modality and attack type --- and learn deep representations for each benchmark by combining and contrasting the two learning approaches. This strategy not only provides better comprehension of how these approaches interplay, but also creates systems that exceed the best known results in eight out of the nine benchmarks. The results strongly indicate that spoofing detection systems based on convolutional networks can be robust to attacks already known and possibly adapted, with little effort, to image-based attacks that are yet to come.