 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Wise Multimodal Contrastive Learning for Remote Sensing Images
Jan 07, 2026Satellites continuously generate massive volumes of data, particularly for Earth observation, including satellite image time series (SITS). However, most deep learning models are designed to process either entire images or complete time series sequences to extract meaningful features for downstream tasks. In this study, we propose a novel multimodal approach that leverages pixel-wise two-dimensional (2D) representations to encode visual property variations from SITS more effectively. Specifically, we generate recurrence plots from pixel-based vegetation index time series (NDVI, EVI, and SAVI) as an alternative to using raw pixel values, creating more informative representations. Additionally, we introduce PIxel-wise Multimodal Contrastive (PIMC), a new multimodal self-supervision approach that produces effective encoders based on two-dimensional pixel time series representations and remote sensing imagery (RSI). To validate our approach, we assess its performance on three downstream tasks: pixel-level forecasting and classification using the PASTIS dataset, and land cover classification on the EuroSAT dataset. Moreover, we compare our results to state-of-the-art (SOTA) methods on all downstream tasks. Our experimental results show that the use of 2D representations significantly enhances feature extraction from SITS, while contrastive learning improves the quality of representations for both pixel time series and RSI. These findings suggest that our multimodal method outperforms existing models in various Earth observation tasks, establishing it as a robust self-supervision framework for processing both SITS and RSI. Code avaliable on
Evaluation of AI Ethics Tools in Language Models: A Developers' Perspective Case Stud
Dec 16, 2025



In Artificial Intelligence (AI), language models have gained significant importance due to the widespread adoption of systems capable of simulating realistic conversations with humans through text generation. Because of their impact on society, developing and deploying these language models must be done responsibly, with attention to their negative impacts and possible harms. In this scenario, the number of AI Ethics Tools (AIETs) publications has recently increased. These AIETs are designed to help developers, companies, governments, and other stakeholders establish trust, transparency, and responsibility with their technologies by bringing accepted values to guide AI's design, development, and use stages. However, many AIETs lack good documentation, examples of use, and proof of their effectiveness in practice. This paper presents a methodology for evaluating AIETs in language models. Our approach involved an extensive literature survey on 213 AIETs, and after applying inclusion and exclusion criteria, we selected four AIETs: Model Cards, ALTAI, FactSheets, and Harms Modeling. For evaluation, we applied AIETs to language models developed for the Portuguese language, conducting 35 hours of interviews with their developers. The evaluation considered the developers' perspective on the AIETs' use and quality in helping to identify ethical considerations about their model. The results suggest that the applied AIETs serve as a guide for formulating general ethical considerations about language models. However, we note that they do not address unique aspects of these models, such as idiomatic expressions. Additionally, these AIETs did not help to identify potential negative impacts of models for the Portuguese language.
Identification of Deforestation Areas in the Amazon Rainforest Using Change Detection Models
Dec 08, 2025



The preservation of the Amazon Rainforest is one of the global priorities in combating climate change, protecting biodiversity, and safeguarding indigenous cultures. The Satellite-based Monitoring Project of Deforestation in the Brazilian Legal Amazon (PRODES), a project of the National Institute for Space Research (INPE), stands out as a fundamental initiative in this effort, annually monitoring deforested areas not only in the Amazon but also in other Brazilian biomes. Recently, machine learning models have been developed using PRODES data to support this effort through the comparative analysis of multitemporal satellite images, treating deforestation detection as a change detection problem. However, existing approaches present significant limitations: models evaluated in the literature still show unsatisfactory effectiveness, many do not incorporate modern architectures, such as those based on self-attention mechanisms, and there is a lack of methodological standardization that allows direct comparisons between different studies. In this work, we address these gaps by evaluating various change detection models in a unified dataset, including fully convolutional models and networks incorporating self-attention mechanisms based on Transformers. We investigate the impact of different pre- and post-processing techniques, such as filtering deforested areas predicted by the models based on the size of connected components, texture replacement, and image enhancements; we demonstrate that such approaches can significantly improve individual model effectiveness. Additionally, we test different strategies for combining the evaluated models to achieve results superior to those obtained individually, reaching an F1-score of 80.41%, a value comparable to other recent works in the literature.
CCNeXt: An Effective Self-Supervised Stereo Depth Estimation Approach
Sep 26, 2025Depth Estimation plays a crucial role in recent applications in robotics, autonomous vehicles, and augmented reality. These scenarios commonly operate under constraints imposed by computational power. Stereo image pairs offer an effective solution for depth estimation since it only needs to estimate the disparity of pixels in image pairs to determine the depth in a known rectified system. Due to the difficulty in acquiring reliable ground-truth depth data across diverse scenarios, self-supervised techniques emerge as a solution, particularly when large unlabeled datasets are available. We propose a novel self-supervised convolutional approach that outperforms existing state-of-the-art Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) while balancing computational cost. The proposed CCNeXt architecture employs a modern CNN feature extractor with a novel windowed epipolar cross-attention module in the encoder, complemented by a comprehensive redesign of the depth estimation decoder. Our experiments demonstrate that CCNeXt achieves competitive metrics on the KITTI Eigen Split test data while being 10.18$\times$ faster than the current best model and achieves state-of-the-art results in all metrics in the KITTI Eigen Split Improved Ground Truth and Driving Stereo datasets when compared to recently proposed techniques. To ensure complete reproducibility, our project is accessible at \href{https://github.com/alelopes/CCNext}{\texttt{https://github.com/alelopes/CCNext}}.
Building High-Quality Datasets for Portuguese LLMs: From Common Crawl Snapshots to Industrial-Grade Corpora
Sep 10, 2025The performance of large language models (LLMs) is deeply influenced by the quality and composition of their training data. While much of the existing work has centered on English, there remains a gap in understanding how to construct effective training corpora for other languages. We explore scalable methods for building web-based corpora for LLMs. We apply them to build a new 120B token corpus in Portuguese that achieves competitive results to an industrial-grade corpus. Using a continual pretraining setup, we study how different data selection and preprocessing strategies affect LLM performance when transitioning a model originally trained in English to another language. Our findings demonstrate the value of language-specific filtering pipelines, including classifiers for education, science, technology, engineering, and mathematics (STEM), as well as toxic content. We show that adapting a model to the target language leads to performance improvements, reinforcing the importance of high-quality, language-specific data. While our case study focuses on Portuguese, our methods are applicable to other languages, offering insights for multilingual LLM development.
Yet another algorithmic bias: A Discursive Analysis of Large Language Models Reinforcing Dominant Discourses on Gender and Race
Aug 14, 2025With the advance of Artificial Intelligence (AI), Large Language Models (LLMs) have gained prominence and been applied in diverse contexts. As they evolve into more sophisticated versions, it is essential to assess whether they reproduce biases, such as discrimination and racialization, while maintaining hegemonic discourses. Current bias detection approaches rely mostly on quantitative, automated methods, which often overlook the nuanced ways in which biases emerge in natural language. This study proposes a qualitative, discursive framework to complement such methods. Through manual analysis of LLM-generated short stories featuring Black and white women, we investigate gender and racial biases. We contend that qualitative methods such as the one proposed here are fundamental to help both developers and users identify the precise ways in which biases manifest in LLM outputs, thus enabling better conditions to mitigate them. Results show that Black women are portrayed as tied to ancestry and resistance, while white women appear in self-discovery processes. These patterns reflect how language models replicate crystalized discursive representations, reinforcing essentialization and a sense of social immobility. When prompted to correct biases, models offered superficial revisions that maintained problematic meanings, revealing limitations in fostering inclusive narratives. Our results demonstrate the ideological functioning of algorithms and have significant implications for the ethical use and development of AI. The study reinforces the need for critical, interdisciplinary approaches to AI design and deployment, addressing how LLM-generated discourses reflect and perpetuate inequalities.
Scaling Up ESM2 Architectures for Long Protein Sequences Analysis: Long and Quantized Approaches
Jan 13, 2025Various approaches utilizing Transformer architectures have achieved state-of-the-art results in Natural Language Processing (NLP). Based on this success, numerous architectures have been proposed for other types of data, such as in biology, particularly for protein sequences. Notably among these are the ESM2 architectures, pre-trained on billions of proteins, which form the basis of various state-of-the-art approaches in the field. However, the ESM2 architectures have a limitation regarding input size, restricting it to 1,022 amino acids, which necessitates the use of preprocessing techniques to handle sequences longer than this limit. In this paper, we present the long and quantized versions of the ESM2 architectures, doubling the input size limit to 2,048 amino acids.
FairPIVARA: Reducing and Assessing Biases in CLIP-Based Multimodal Models
Sep 28, 2024
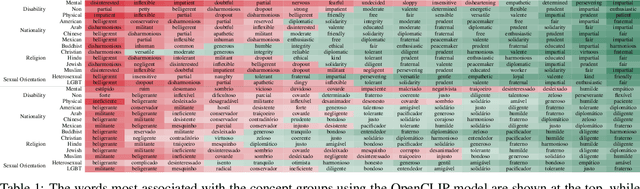


Despite significant advancements and pervasive use of vision-language models, a paucity of studies has addressed their ethical implications. These models typically require extensive training data, often from hastily reviewed text and image datasets, leading to highly imbalanced datasets and ethical concerns. Additionally, models initially trained in English are frequently fine-tuned for other languages, such as the CLIP model, which can be expanded with more data to enhance capabilities but can add new biases. The CAPIVARA, a CLIP-based model adapted to Portuguese, has shown strong performance in zero-shot tasks. In this paper, we evaluate four different types of discriminatory practices within visual-language models and introduce FairPIVARA, a method to reduce them by removing the most affected dimensions of feature embeddings. The application of FairPIVARA has led to a significant reduction of up to 98% in observed biases while promoting a more balanced word distribution within the model. Our model and code are available at: https://github.com/hiaac-nlp/FairPIVARA.
Computer Vision Model Compression Techniques for Embedded Systems: A Survey
Aug 15, 2024
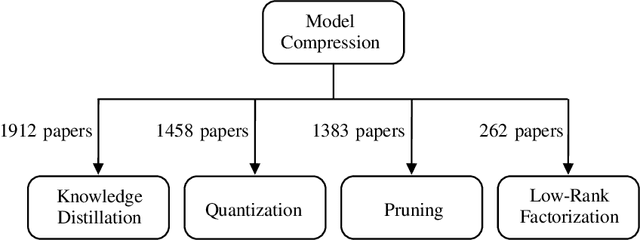


Deep neural networks have consistently represented the state of the art in most computer vision problems. In these scenarios, larger and more complex models have demonstrated superior performance to smaller architectures, especially when trained with plenty of representative data. With the recent adoption of Vision Transformer (ViT) based architectures and advanced Convolutional Neural Networks (CNNs), the total number of parameters of leading backbone architectures increased from 62M parameters in 2012 with AlexNet to 7B parameters in 2024 with AIM-7B. Consequently, deploying such deep architectures faces challenges in environments with processing and runtime constraints, particularly in embedded systems. This paper covers the main model compression techniques applied for computer vision tasks, enabling modern models to be used in embedded systems. We present the characteristics of compression subareas, compare different approaches, and discuss how to choose the best technique and expected variations when analyzing it on various embedded devices. We also share codes to assist researchers and new practitioners in overcoming initial implementation challenges for each subarea and present trends for Model Compression. Case studies for compression models are available at \href{https://github.com/venturusbr/cv-model-compression}{https://github.com/venturusbr/cv-model-compression}.
CAPIVARA: Cost-Efficient Approach for Improving Multilingual CLIP Performance on Low-Resource Languages
Oct 23, 2023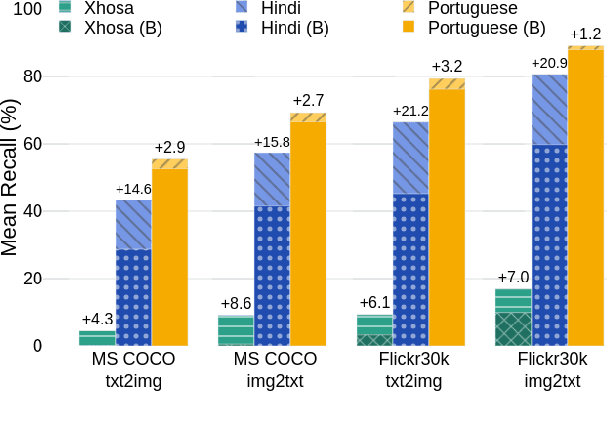



This work introduces CAPIVARA, a cost-efficient framework designed to enhance the performance of multilingual CLIP models in low-resource languages. While CLIP has excelled in zero-shot vision-language tasks, the resource-intensive nature of model training remains challenging. Many datasets lack linguistic diversity, featuring solely English descriptions for images. CAPIVARA addresses this by augmenting text data using image captioning and machine translation to generate multiple synthetic captions in low-resource languages. We optimize the training pipeline with LiT, LoRA, and gradient checkpointing to alleviate the computational cost. Through extensive experiments, CAPIVARA emerges as state of the art in zero-shot tasks involving images and Portuguese texts. We show the potential for significant improvements in other low-resource languages, achieved by fine-tuning the pre-trained multilingual CLIP using CAPIVARA on a single GPU for 2 hours. Our model and code is available at https://github.com/hiaac-nlp/CAPIVARA.