 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCNeXt: An Effective Self-Supervised Stereo Depth Estimation Approach
Sep 26, 2025Depth Estimation plays a crucial role in recent applications in robotics, autonomous vehicles, and augmented reality. These scenarios commonly operate under constraints imposed by computational power. Stereo image pairs offer an effective solution for depth estimation since it only needs to estimate the disparity of pixels in image pairs to determine the depth in a known rectified system. Due to the difficulty in acquiring reliable ground-truth depth data across diverse scenarios, self-supervised techniques emerge as a solution, particularly when large unlabeled datasets are available. We propose a novel self-supervised convolutional approach that outperforms existing state-of-the-art Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) while balancing computational cost. The proposed CCNeXt architecture employs a modern CNN feature extractor with a novel windowed epipolar cross-attention module in the encoder, complemented by a comprehensive redesign of the depth estimation decoder. Our experiments demonstrate that CCNeXt achieves competitive metrics on the KITTI Eigen Split test data while being 10.18$\times$ faster than the current best model and achieves state-of-the-art results in all metrics in the KITTI Eigen Split Improved Ground Truth and Driving Stereo datasets when compared to recently proposed techniques. To ensure complete reproducibility, our project is accessible at \href{https://github.com/alelopes/CCNext}{\texttt{https://github.com/alelopes/CCNext}}.
Computer Vision Model Compression Techniques for Embedded Systems: A Survey
Aug 15, 2024
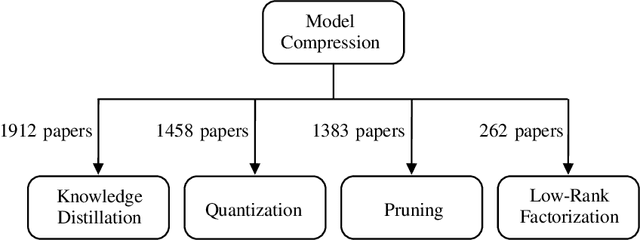


Deep neural networks have consistently represented the state of the art in most computer vision problems. In these scenarios, larger and more complex models have demonstrated superior performance to smaller architectures, especially when trained with plenty of representative data. With the recent adoption of Vision Transformer (ViT) based architectures and advanced Convolutional Neural Networks (CNNs), the total number of parameters of leading backbone architectures increased from 62M parameters in 2012 with AlexNet to 7B parameters in 2024 with AIM-7B. Consequently, deploying such deep architectures faces challenges in environments with processing and runtime constraints, particularly in embedded systems. This paper covers the main model compression techniques applied for computer vision tasks, enabling modern models to be used in embedded systems. We present the characteristics of compression subareas, compare different approaches, and discuss how to choose the best technique and expected variations when analyzing it on various embedded devices. We also share codes to assist researchers and new practitioners in overcoming initial implementation challenges for each subarea and present trends for Model Compression. Case studies for compression models are available at \href{https://github.com/venturusbr/cv-model-compression}{https://github.com/venturusbr/cv-model-compression}.
A Survey on RGB-D Datasets
Jan 15, 2022


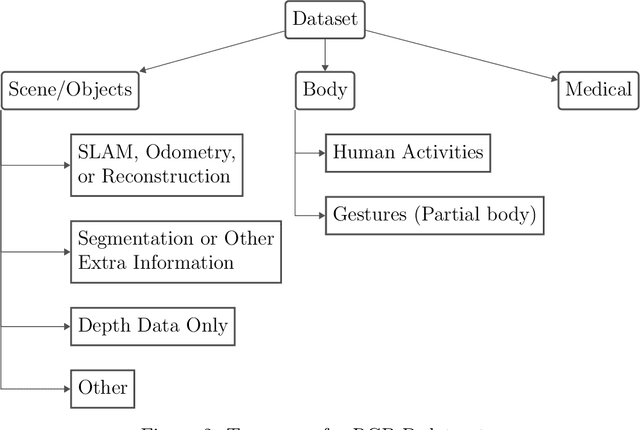
RGB-D data is essential for solving many problems in computer vision. Hundreds of public RGB-D datasets containing various scenes, such as indoor, outdoor, aerial, driving, and medical, have been proposed. These datasets are useful for different applications and are fundamental for addressing classic computer vision tasks, such as monocular depth estimation. This paper reviewed and categorized image datasets that include depth information. We gathered 203 datasets that contain accessible data and grouped them into three categories: scene/objects, body, and medical. We also provided an overview of the different types of sensors, depth applications, and we examined trends and future directions of the usage and creation of datasets containing depth data, and how they can be applied to investigate the development of generalizable machine learning models in the monocular depth estimation field.
Multi-channel MR Reconstruction (MC-MRRec) Challenge -- Comparing Accelerated MR Reconstruction Models and Assessing Their Genereralizability to Datasets Collected with Different Coils
Nov 10, 2020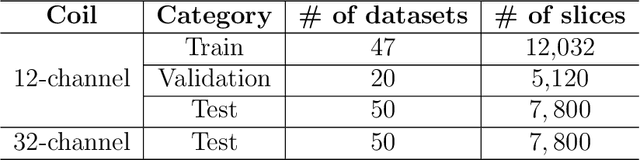
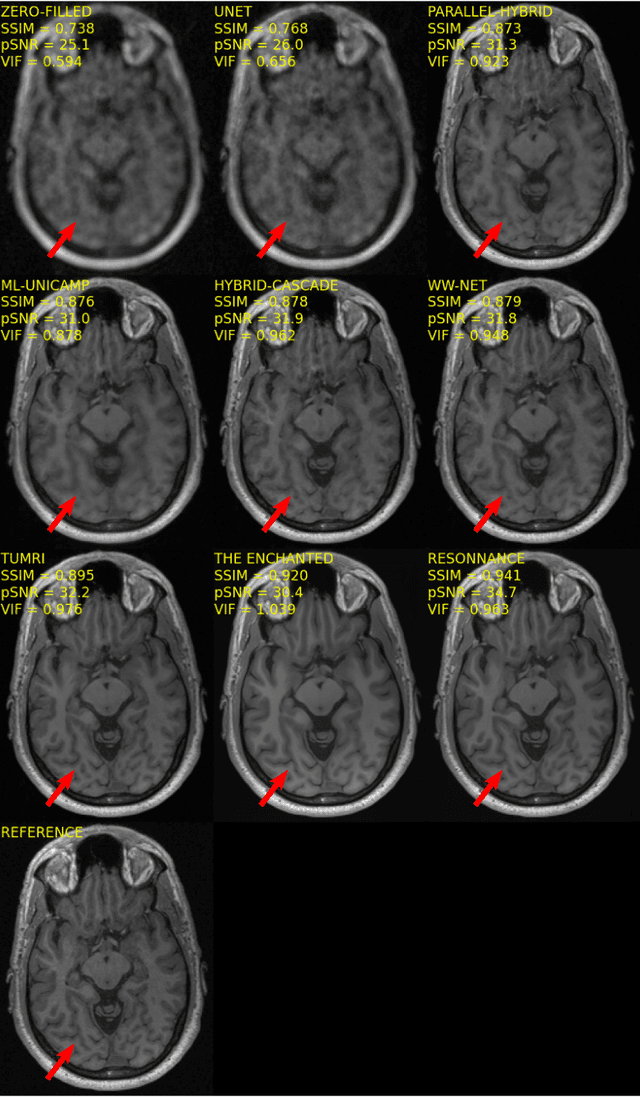
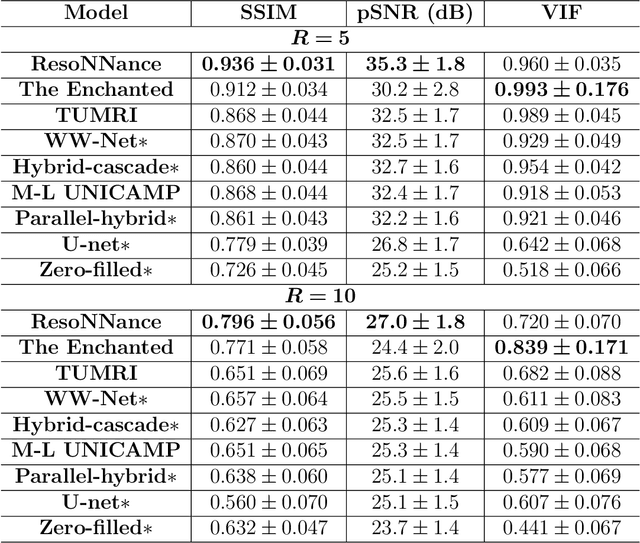
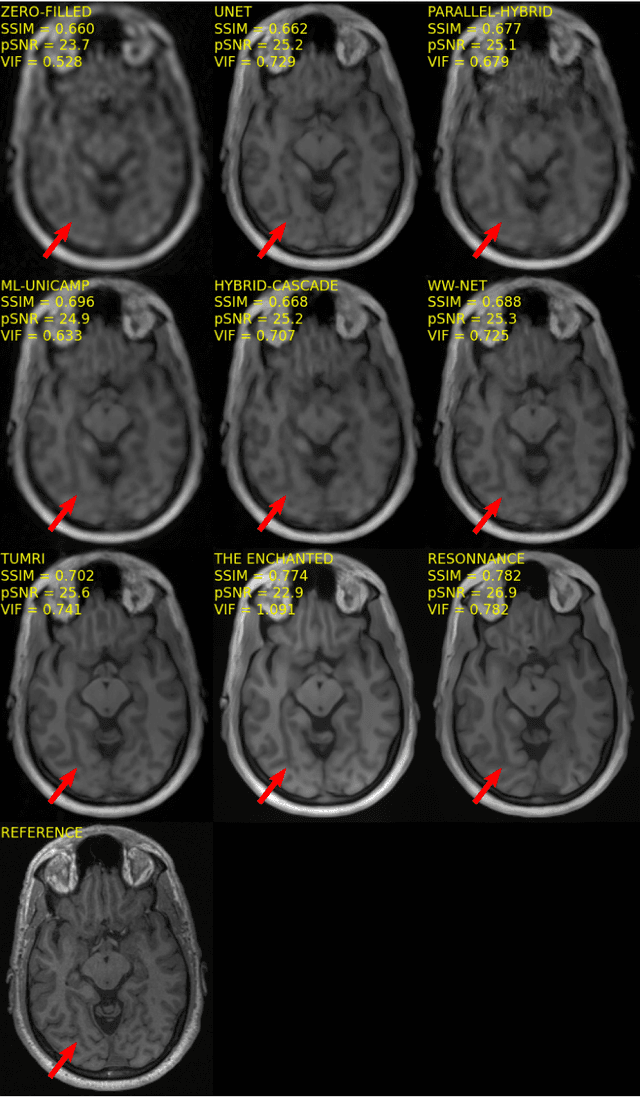
The 2020 Multi-channel Magnetic Resonance Reconstruction (MC-MRRec) Challenge had two primary goals: 1) compare different MR image reconstruction models on a large dataset and 2) assess the generalizability of these models to datasets acquired with a different number of receiver coils (i.e., multiple channels). The challenge had two tracks: Track 01 focused on assessing models trained and tested with 12-channel data. Track 02 focused on assessing models trained with 12-channel data and tested on both 12-channel and 32-channel data. While the challenge is ongoing, here we describe the first edition of the challenge and summarise submissions received prior to 5 September 2020. Track 01 had five baseline models and received four independent submissions. Track 02 had two baseline models and received two independent submissions. This manuscript provides relevant comparative information on the current state-of-the-art of MR reconstruction and highlights the challenges of obtaining generalizable models that are required prior to clinical adoption. Both challenge tracks remain open and will provide an objective performance assessment for future submissions. Subsequent editions of the challenge are proposed to investigate new concepts and strategies, such as the integration of potentially available longitudinal information during the MR reconstruction process. An outline of the proposed second edition of the challenge is presented in this manuscript.
Lite Training Strategies for Portuguese-English and English-Portuguese Translation
Aug 20, 2020



Despite the widespread adoption of deep learning for machine translation, it is still expensive to develop high-quality translation models. In this work, we investigate the use of pre-trained models, such as T5 for Portuguese-English and English-Portuguese translation tasks using low-cost hardware. We explore the use of Portuguese and English pre-trained language models and propose an adaptation of the English tokenizer to represent Portuguese characters, such as diaeresis, acute and grave accents. We compare our models to the Google Translate API and MarianMT on a subset of the ParaCrawl dataset, as well as to the winning submission to the WMT19 Biomedical Translation Shared Task. We also describe our submission to the WMT20 Biomedical Translation Shared Task. Our results show that our models have a competitive performance to state-of-the-art models while being trained on modest hardware (a single 8GB gaming GPU for nine days). Our data, models and code are available at https://github.com/unicamp-dl/Lite-T5-Translation.