 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer Vision Model Compression Techniques for Embedded Systems: A Survey
Aug 15, 2024
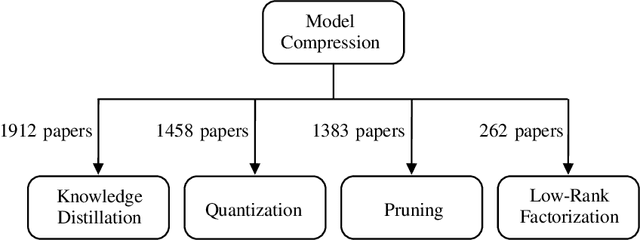


Deep neural networks have consistently represented the state of the art in most computer vision problems. In these scenarios, larger and more complex models have demonstrated superior performance to smaller architectures, especially when trained with plenty of representative data. With the recent adoption of Vision Transformer (ViT) based architectures and advanced Convolutional Neural Networks (CNNs), the total number of parameters of leading backbone architectures increased from 62M parameters in 2012 with AlexNet to 7B parameters in 2024 with AIM-7B. Consequently, deploying such deep architectures faces challenges in environments with processing and runtime constraints, particularly in embedded systems. This paper covers the main model compression techniques applied for computer vision tasks, enabling modern models to be used in embedded systems. We present the characteristics of compression subareas, compare different approaches, and discuss how to choose the best technique and expected variations when analyzing it on various embedded devices. We also share codes to assist researchers and new practitioners in overcoming initial implementation challenges for each subarea and present trends for Model Compression. Case studies for compression models are available at \href{https://github.com/venturusbr/cv-model-compression}{https://github.com/venturusbr/cv-model-compression}.
Training Deep Networks from Zero to Hero: avoiding pitfalls and going beyond
Sep 06, 2021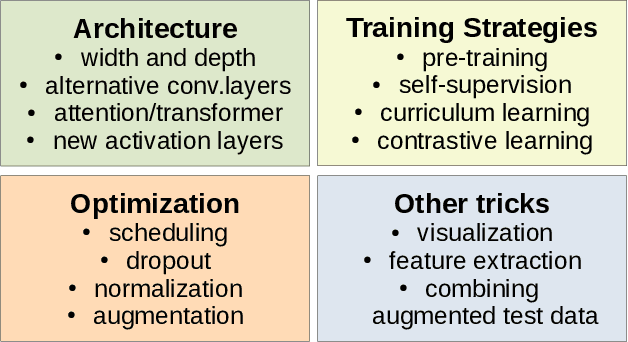
Training deep neural networks may be challenging in real world data. Using models as black-boxes, even with transfer learning, can result in poor generalization or inconclusive results when it comes to small datasets or specific applications. This tutorial covers the basic steps as well as more recent options to improve models, in particular, but not restricted to, supervised learning. It can be particularly useful in datasets that are not as well-prepared as those in challenges, and also under scarce annotation and/or small data. We describe basic procedures: as data preparation, optimization and transfer learning, but also recent architectural choices such as use of transformer modules, alternative convolutional layers, activation functions, wide and deep networks, as well as training procedures including as curriculum, contrastive and self-supervised learning.
Generalization of feature embeddings transferred from different video anomaly detection domains
Jan 28, 2019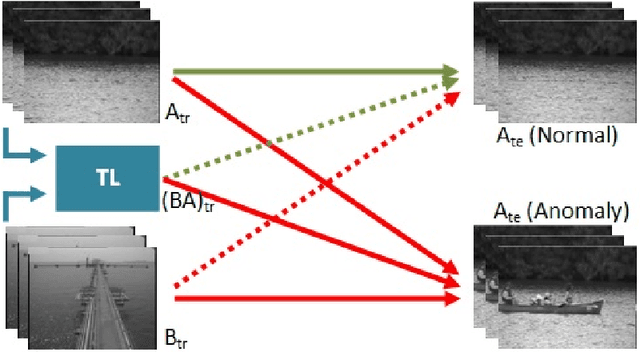
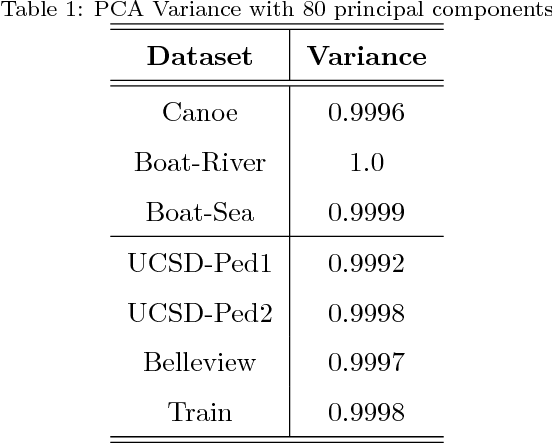


Detecting anomalous activity in video surveillance often involves using only normal activity data in order to learn an accurate detector. Due to lack of annotated data for some specific target domain, one could employ existing data from a source domain to produce better predictions. Hence, transfer learning presents itself as an important tool. But how to analyze the resulting data space? This paper investigates video anomaly detection, in particular feature embeddings of pre-trained CNN that can be used with non-fully supervised data. By proposing novel cross-domain generalization measures, we study how source features can generalize for different target video domains, as well as analyze unsupervised transfer learning. The proposed generalization measures are not only a theorical approach, but show to be useful in practice as a way to understand which datasets can be used or transferred to describe video frames, which it is possible to better discriminate between normal and anomalous activity.