 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Cyclopean-Eye in Stereo Vision
Jun 26, 2025



This work investigates the geometric foundations of modern stereo vision systems, with a focus on how 3D structure and human-inspired perception contribute to accurate depth reconstruction. We revisit the Cyclopean Eye model and propose novel geometric constraints that account for occlusions and depth discontinuities. Our analysis includes the evaluation of stereo feature matching quality derived from deep learning models, as well as the role of attention mechanisms in recovering meaningful 3D surfaces. Through both theoretical insights and empirical studies on real datasets, we demonstrate that combining strong geometric priors with learned features provides internal abstractions for understanding stereo vision systems.
Back to the Future Cyclopean Stereo: a human perception approach unifying deep and geometric constraints
Feb 28, 2025
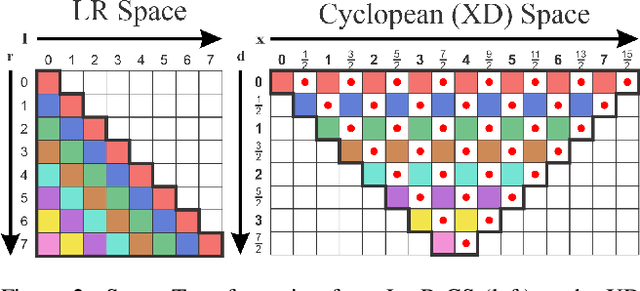


We innovate in stereo vision by explicitly providing analytical 3D surface models as viewed by a cyclopean eye model that incorporate depth discontinuities and occlusions. This geometrical foundation combined with learned stereo features allows our system to benefit from the strengths of both approaches. We also invoke a prior monocular model of surfaces to fill in occlusion regions or texture-less regions where data matching is not sufficient. Our results already are on par with the state-of-the-art purely data-driven methods and are of much better visual quality, emphasizing the importance of the 3D geometrical model to capture critical visual information. Such qualitative improvements may find applicability in virtual reality, for a better human experience, as well as in robotics, for reducing critical errors. Our approach aims to demonstrate that understanding and modeling geometrical properties of 3D surfaces is beneficial to computer vision research.
Causal Inference Real-Time Anomaly Detection with Synthetic Anomaly Monitoring (SAM)
Jan 30, 2025



Anomaly detection is essential for identifying rare and significant events across diverse domains such as finance, cybersecurity, and network monitoring. This paper presents Synthetic Anomaly Monitoring (SAM), an innovative approach that applies synthetic control methods from causal inference to improve both the accuracy and interpretability of anomaly detection processes. By modeling normal behavior through the treatment of each feature as a control unit, SAM identifies anomalies as deviations within this causal framework. We conducted extensive experiments comparing SAM with established benchmark models, including Isolation Forest, Local Outlier Factor (LOF), k-Nearest Neighbors (kNN), and One-Class Support Vector Machine (SVM), across five diverse datasets, including Credit Card Fraud, HTTP Dataset CSIC 2010, and KDD Cup 1999, among others. Our results demonstrate that SAM consistently delivers robust performance, highlighting its potential as a powerful tool for real-time anomaly detection in dynamic and complex environments.
Decoupling Decision-Making in Fraud Prevention through Classifier Calibration for Business Logic Action
Jan 10, 2024

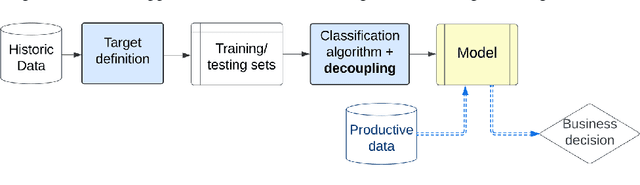

Machine learning models typically focus on specific targets like creating classifiers, often based on known population feature distributions in a business context. However, models calculating individual features adapt over time to improve precision, introducing the concept of decoupling: shifting from point evaluation to data distribution. We use calibration strategies as strategy for decoupling machine learning (ML) classifiers from score-based actions within business logic frameworks. To evaluate these strategies, we perform a comparative analysis using a real-world business scenario and multiple ML models. Our findings highlight the trade-offs and performance implications of the approach, offering valuable insights for practitioners seeking to optimize their decoupling efforts. In particular, the Isotonic and Beta calibration methods stand out for scenarios in which there is shift between training and testing data.
Evaluation of Barlow Twins and VICReg self-supervised learning for sound patterns of bird and anuran species
Dec 18, 2023Taking advantage of the structure of large datasets to pre-train Deep Learning models is a promising strategy to decrease the need for supervised data. Self-supervised learning methods, such as contrastive and its variation are a promising way towards obtaining better representations in many Deep Learning applications. Soundscape ecology is one application in which annotations are expensive and scarce, therefore deserving investigation to approximate methods that do not require annotations to those that rely on supervision. Our study involves the use of the methods Barlow Twins and VICReg to pre-train different models with the same small dataset with sound patterns of bird and anuran species. In a downstream task to classify those animal species, the models obtained results close to supervised ones, pre-trained in large generic datasets, and fine-tuned with the same task.
Dendrogram distance: an evaluation metric for generative networks using hierarchical clustering
Nov 28, 2023We present a novel metric for generative modeling evaluation, focusing primarily on generative networks. The method uses dendrograms to represent real and fake data, allowing for the divergence between training and generated samples to be computed. This metric focus on mode collapse, targeting generators that are not able to capture all modes in the training set. To evaluate the proposed method it is introduced a validation scheme based on sampling from real datasets, therefore the metric is evaluated in a controlled environment and proves to be competitive with other state-of-the-art approaches.
Sketch-an-Anchor: Sub-epoch Fast Model Adaptation for Zero-shot Sketch-based Image Retrieval
Mar 29, 2023Sketch-an-Anchor is a novel method to train state-of-the-art Zero-shot Sketch-based Image Retrieval (ZSSBIR) models in under an epoch. Most studies break down the problem of ZSSBIR into two parts: domain alignment between images and sketches, inherited from SBIR, and generalization to unseen data, inherent to the zero-shot protocol. We argue one of these problems can be considerably simplified and re-frame the ZSSBIR problem around the already-stellar yet underexplored Zero-shot Image-based Retrieval performance of off-the-shelf models. Our fast-converging model keeps the single-domain performance while learning to extract similar representations from sketches. To this end we introduce our Semantic Anchors -- guiding embeddings learned from word-based semantic spaces and features from off-the-shelf models -- and combine them with our novel Anchored Contrastive Loss. Empirical evidence shows we can achieve state-of-the-art performance on all benchmark datasets while training for 100x less iterations than other methods.
Improving Data Quality with Training Dynamics of Gradient Boosting Decision Trees
Oct 20, 2022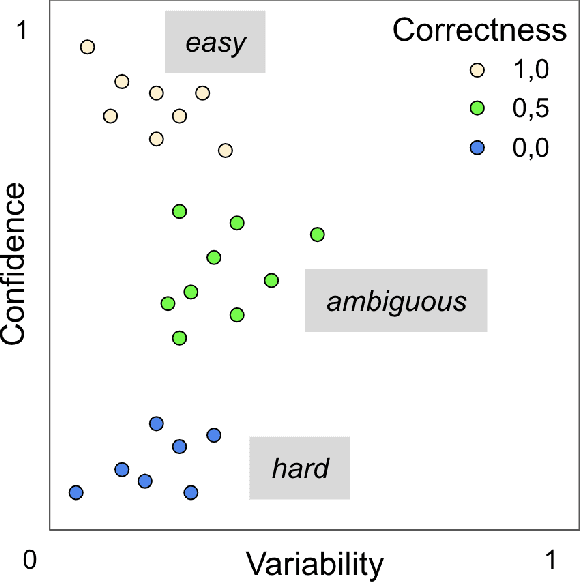
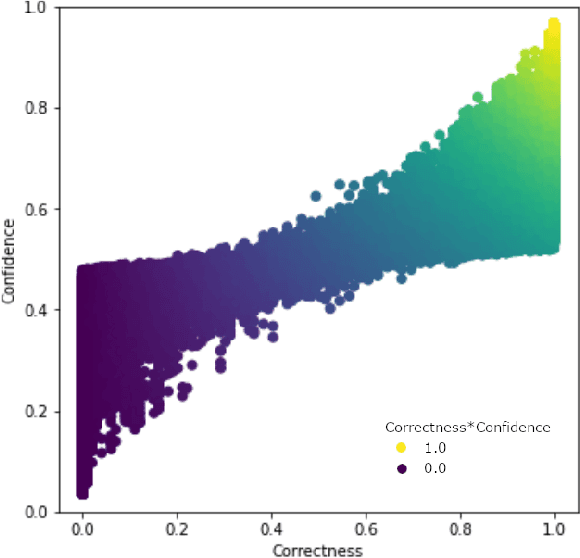
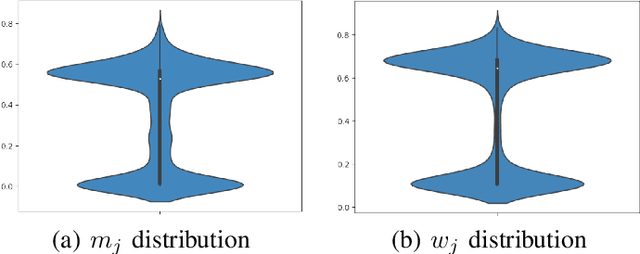
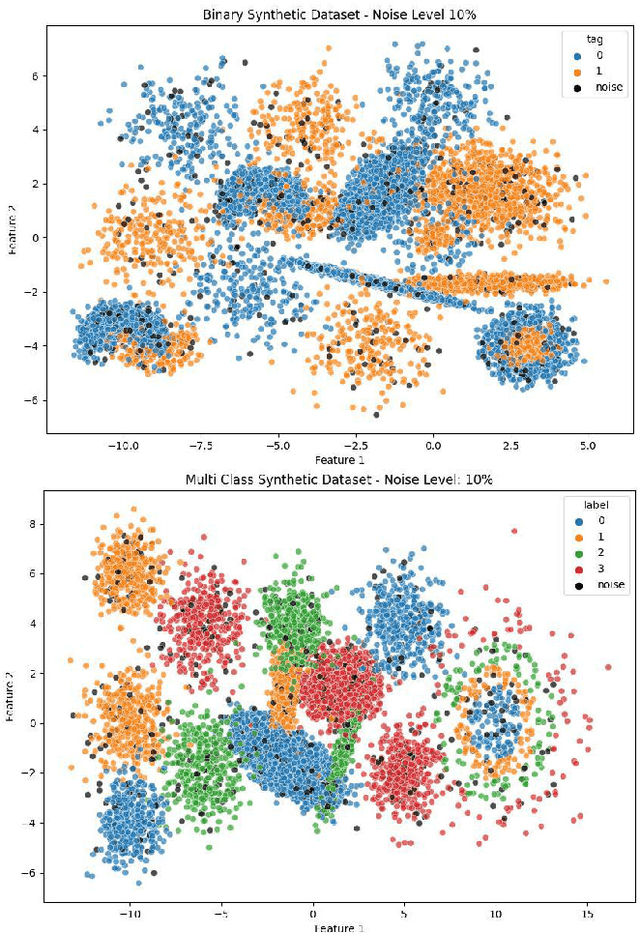
Real world datasets contain incorrectly labeled instances that hamper the performance of the model and, in particular, the ability to generalize out of distribution. Also, each example might have different contribution towards learning. This motivates studies to better understanding of the role of data instances with respect to their contribution in good metrics in models. In this paper we propose a method based on metrics computed from training dynamics of Gradient Boosting Decision Trees (GBDTs) to assess the behavior of each training example. We focus on datasets containing mostly tabular or structured data, for which the use of Decision Trees ensembles are still the state-of-the-art in terms of performance. We show results on detecting noisy labels in order to either remove them, improving models' metrics in synthetic and real datasets, as well as a productive dataset. Our methods achieved the best results overall when compared with confident learning and heuristics.
A single speaker is almost all you need for automatic speech recognition
Mar 29, 2022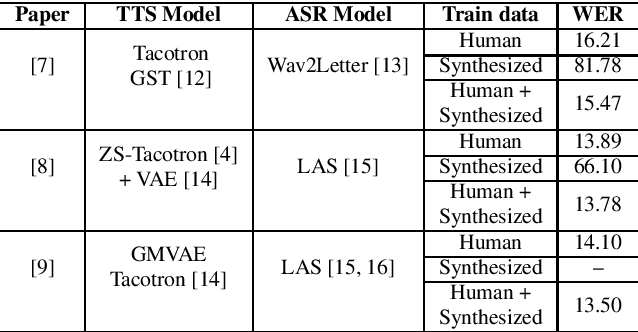
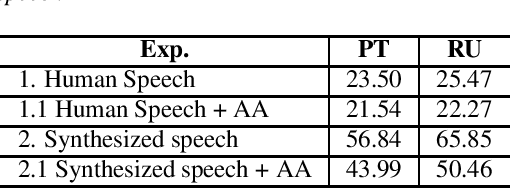

We explore the use of speech synthesis and voice conversion applied to augment datasets for automatic speech recognition (ASR) systems, in scenarios with only one speaker available for the target language. Through extensive experiments, we show that our approach achieves results compared to the state-of-the-art (SOTA) and requires only one speaker in the target language during speech synthesis/voice conversion model training. Finally, we show that it is possible to obtain promising results in the training of an ASR model with our data augmentation method and only a single real speaker in different target languages.
Implementing simple spectral denoising for environmental audio recordings
Jan 06, 2022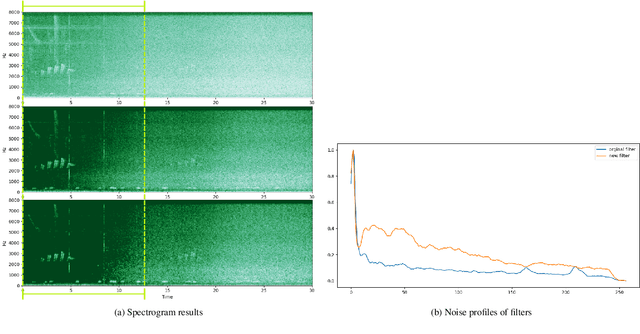
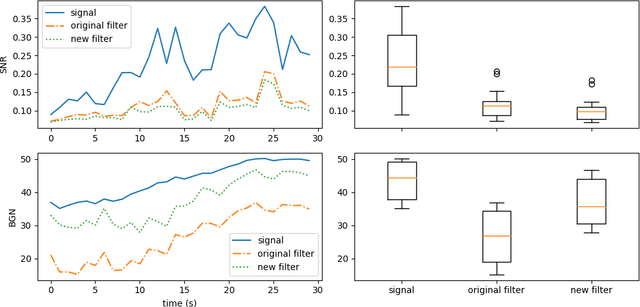

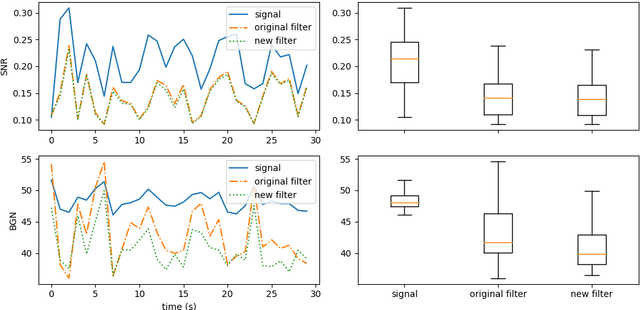
This technical report details changes applied to a noise filter to facilitate its application and improve its results. The filter is applied to denoise natural sounds recorded in the wild and to generate an acoustic index used in soundscape analysis.