 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference Real-Time Anomaly Detection with Synthetic Anomaly Monitoring (SAM)
Jan 30, 2025



Anomaly detection is essential for identifying rare and significant events across diverse domains such as finance, cybersecurity, and network monitoring. This paper presents Synthetic Anomaly Monitoring (SAM), an innovative approach that applies synthetic control methods from causal inference to improve both the accuracy and interpretability of anomaly detection processes. By modeling normal behavior through the treatment of each feature as a control unit, SAM identifies anomalies as deviations within this causal framework. We conducted extensive experiments comparing SAM with established benchmark models, including Isolation Forest, Local Outlier Factor (LOF), k-Nearest Neighbors (kNN), and One-Class Support Vector Machine (SVM), across five diverse datasets, including Credit Card Fraud, HTTP Dataset CSIC 2010, and KDD Cup 1999, among others. Our results demonstrate that SAM consistently delivers robust performance, highlighting its potential as a powerful tool for real-time anomaly detection in dynamic and complex environments.
Decoupling Decision-Making in Fraud Prevention through Classifier Calibration for Business Logic Action
Jan 10, 2024

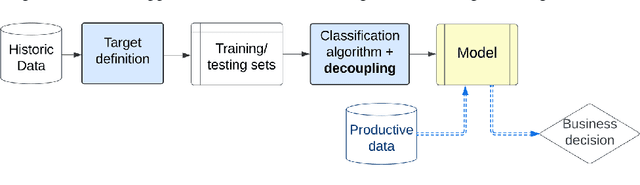

Machine learning models typically focus on specific targets like creating classifiers, often based on known population feature distributions in a business context. However, models calculating individual features adapt over time to improve precision, introducing the concept of decoupling: shifting from point evaluation to data distribution. We use calibration strategies as strategy for decoupling machine learning (ML) classifiers from score-based actions within business logic frameworks. To evaluate these strategies, we perform a comparative analysis using a real-world business scenario and multiple ML models. Our findings highlight the trade-offs and performance implications of the approach, offering valuable insights for practitioners seeking to optimize their decoupling efforts. In particular, the Isotonic and Beta calibration methods stand out for scenarios in which there is shift between training and testing data.