 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Decision-Making in Fraud Prevention through Classifier Calibration for Business Logic Action
Jan 10, 2024

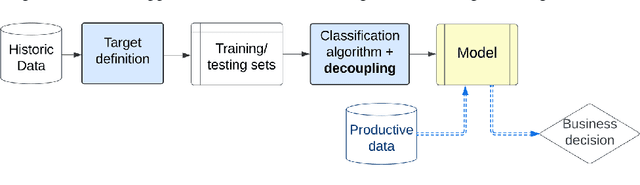

Machine learning models typically focus on specific targets like creating classifiers, often based on known population feature distributions in a business context. However, models calculating individual features adapt over time to improve precision, introducing the concept of decoupling: shifting from point evaluation to data distribution. We use calibration strategies as strategy for decoupling machine learning (ML) classifiers from score-based actions within business logic frameworks. To evaluate these strategies, we perform a comparative analysis using a real-world business scenario and multiple ML models. Our findings highlight the trade-offs and performance implications of the approach, offering valuable insights for practitioners seeking to optimize their decoupling efforts. In particular, the Isotonic and Beta calibration methods stand out for scenarios in which there is shift between training and testing data.
Improving Data Quality with Training Dynamics of Gradient Boosting Decision Trees
Oct 20, 2022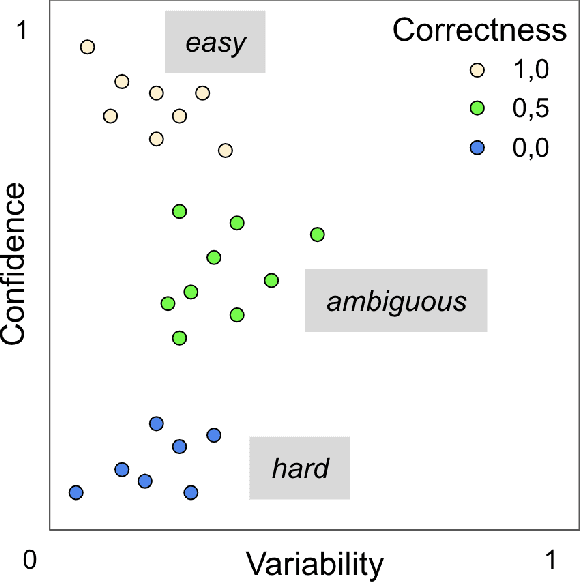
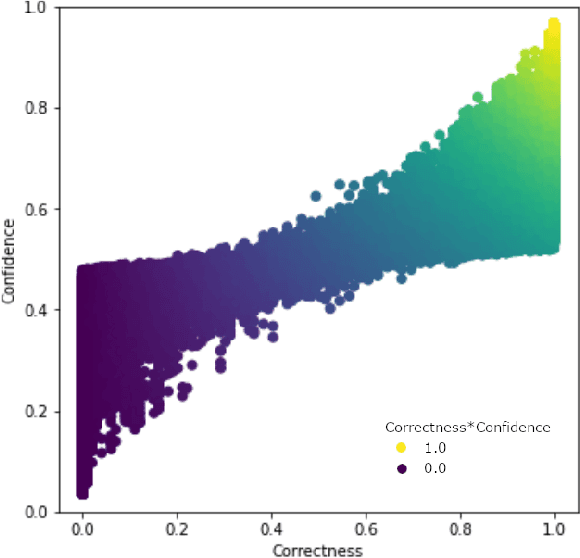
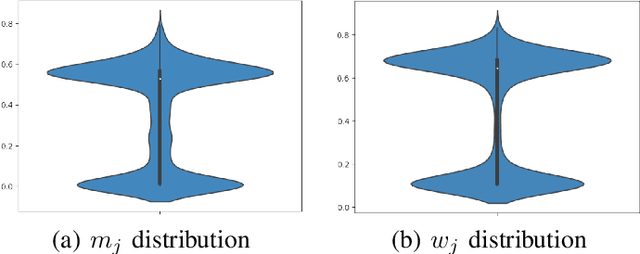
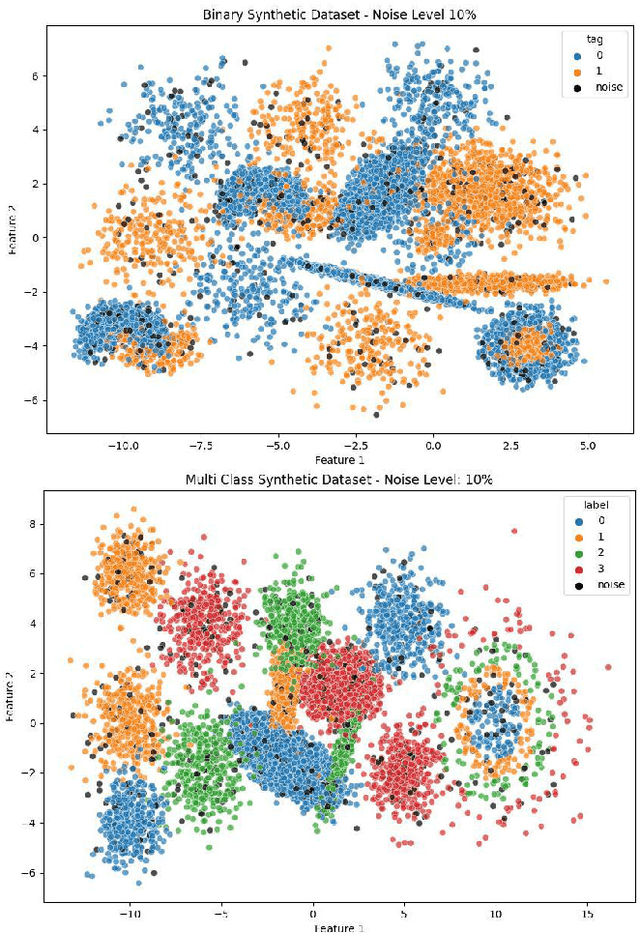
Real world datasets contain incorrectly labeled instances that hamper the performance of the model and, in particular, the ability to generalize out of distribution. Also, each example might have different contribution towards learning. This motivates studies to better understanding of the role of data instances with respect to their contribution in good metrics in models. In this paper we propose a method based on metrics computed from training dynamics of Gradient Boosting Decision Trees (GBDTs) to assess the behavior of each training example. We focus on datasets containing mostly tabular or structured data, for which the use of Decision Trees ensembles are still the state-of-the-art in terms of performance. We show results on detecting noisy labels in order to either remove them, improving models' metrics in synthetic and real datasets, as well as a productive dataset. Our methods achieved the best results overall when compared with confident learning and heuristics.
Iterative evaluation of LSTM cells
Jul 11, 2018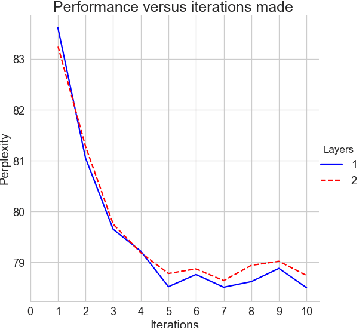

In this work we present a modification in the conventional flow of information through a LSTM network, which we consider well suited for RNNs in general. The modification leads to a iterative scheme where the computations performed by the LSTM cell are repeated over a constant input and cell state values, while updating the hidden state a finite number of times. We provide theoretical and empirical evidence to support the augmented capabilities of the iterative scheme and show examples related to language modeling. The modification yields an enhancement in the model performance comparable with the original model augmented more than 3 times in terms of the total amount of parameters.
From Imitation to Prediction, Data Compression vs Recurrent Neural Networks for Natural Language Processing
May 01, 2017
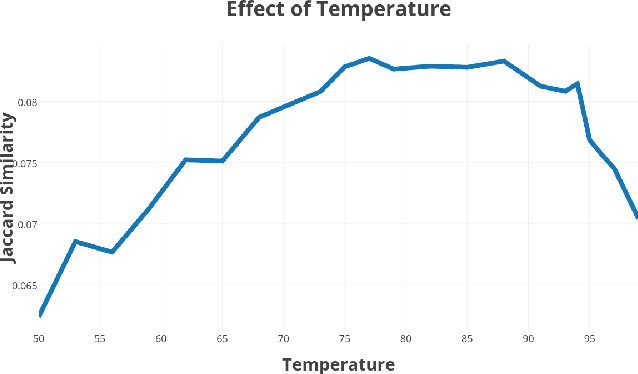
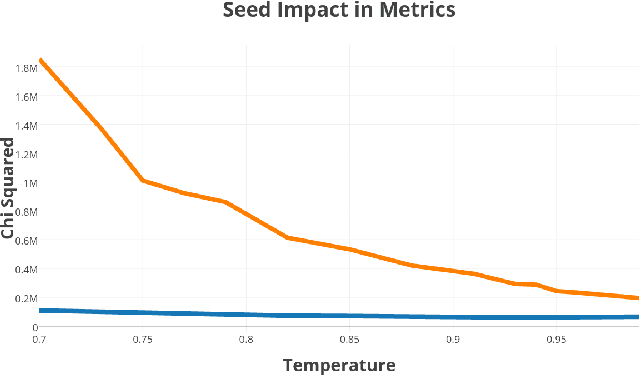

In recent studies [1][13][12] Recurrent Neural Networks were used for generative processes and their surprising performance can be explained by their ability to create good predictions. In addition, data compression is also based on predictions. What the problem comes down to is whether a data compressor could be used to perform as well as recurrent neural networks in natural language processing tasks. If this is possible,then the problem comes down to determining if a compression algorithm is even more intelligent than a neural network in specific tasks related to human language. In our journey we discovered what we think is the fundamental difference between a Data Compression Algorithm and a Recurrent Neural Network.
Hash2Vec, Feature Hashing for Word Embeddings
Aug 31, 2016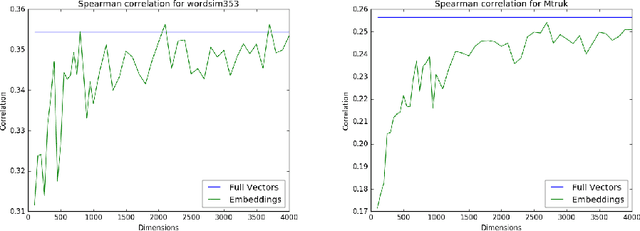

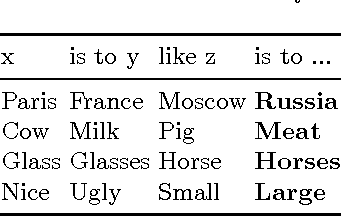
In this paper we propose the application of feature hashing to create word embeddings for natural language processing. Feature hashing has been used successfully to create document vectors in related tasks like document classification. In this work we show that feature hashing can be applied to obtain word embeddings in linear time with the size of the data. The results show that this algorithm, that does not need training, is able to capture the semantic meaning of words. We compare the results against GloVe showing that they are similar. As far as we know this is the first application of feature hashing to the word embeddings problem and the results indicate this is a scalable technique with practical results for NLP applications.
* ASAI 2016, 45JAIIO
Variations of the Similarity Function of TextRank for Automated Summarization
Feb 11, 2016
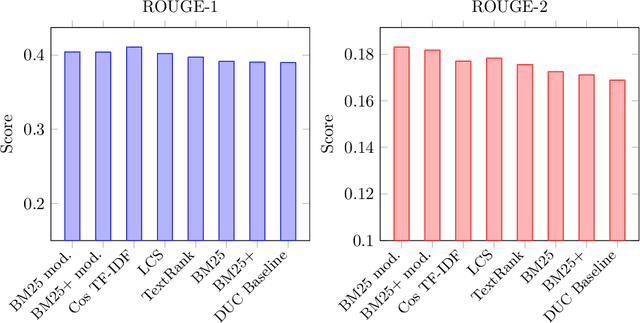
This article presents new alternatives to the similarity function for the TextRank algorithm for automatic summarization of texts. We describe the generalities of the algorithm and the different functions we propose. Some of these variants achieve a significative improvement using the same metrics and dataset as the original publication.
* 8 pages, 2 figures. Presented at the Argentine Symposium on Artificial Intelligence (ASAI) 2015 - 44 JAIIO (September 2015)