Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariations of the Similarity Function of TextRank for Automated Summarization
Feb 11, 2016
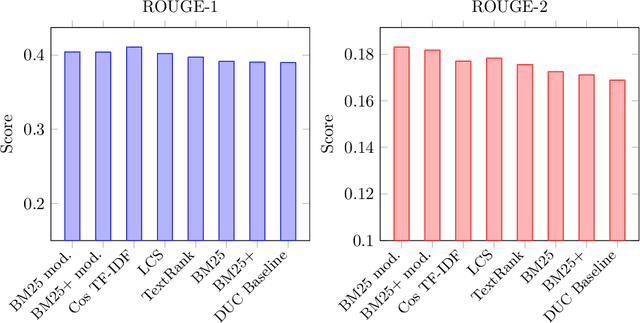
This article presents new alternatives to the similarity function for the TextRank algorithm for automatic summarization of texts. We describe the generalities of the algorithm and the different functions we propose. Some of these variants achieve a significative improvement using the same metrics and dataset as the original publication.
* 44 JAIIO - ASAI 2015 - ISSN: 2451-7585, pages 65-72
* 8 pages, 2 figures. Presented at the Argentine Symposium on Artificial Intelligence (ASAI) 2015 - 44 JAIIO (September 2015)
* 8 pages, 2 figures. Presented at the Argentine Symposium on Artificial Intelligence (ASAI) 2015 - 44 JAIIO (September 2015)
Via