Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHash2Vec, Feature Hashing for Word Embeddings
Paper and Code
Aug 31, 2016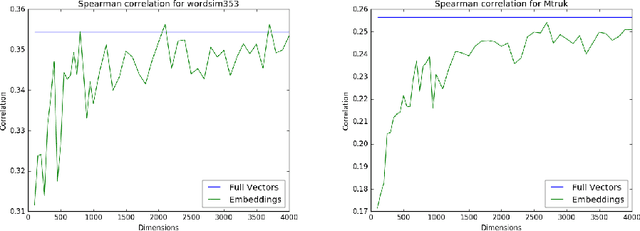

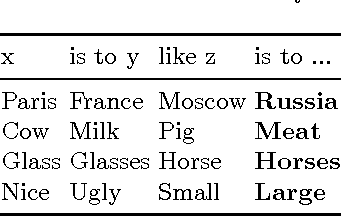
In this paper we propose the application of feature hashing to create word embeddings for natural language processing. Feature hashing has been used successfully to create document vectors in related tasks like document classification. In this work we show that feature hashing can be applied to obtain word embeddings in linear time with the size of the data. The results show that this algorithm, that does not need training, is able to capture the semantic meaning of words. We compare the results against GloVe showing that they are similar. As far as we know this is the first application of feature hashing to the word embeddings problem and the results indicate this is a scalable technique with practical results for NLP applications.
* 45 JAIIO - ASAI 2016 - ISSN: 2451-7585 - Pages 33-40 * ASAI 2016, 45JAIIO
View paper on