 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Data Quality with Training Dynamics of Gradient Boosting Decision Trees
Oct 20, 2022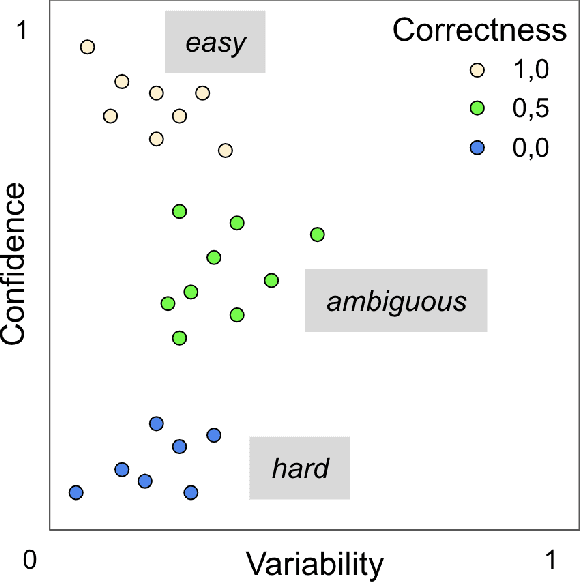
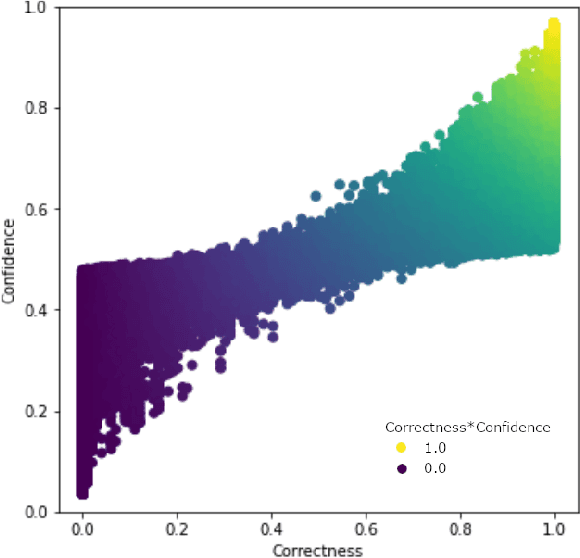
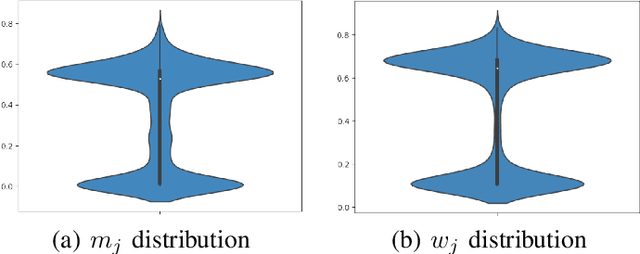
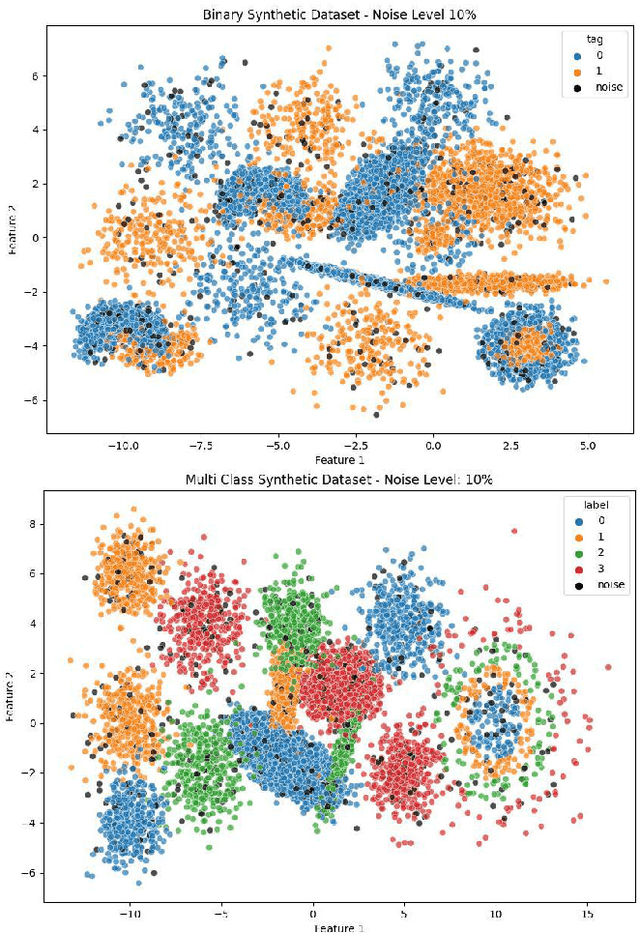
Real world datasets contain incorrectly labeled instances that hamper the performance of the model and, in particular, the ability to generalize out of distribution. Also, each example might have different contribution towards learning. This motivates studies to better understanding of the role of data instances with respect to their contribution in good metrics in models. In this paper we propose a method based on metrics computed from training dynamics of Gradient Boosting Decision Trees (GBDTs) to assess the behavior of each training example. We focus on datasets containing mostly tabular or structured data, for which the use of Decision Trees ensembles are still the state-of-the-art in terms of performance. We show results on detecting noisy labels in order to either remove them, improving models' metrics in synthetic and real datasets, as well as a productive dataset. Our methods achieved the best results overall when compared with confident learning and heuristics.