 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-an-Anchor: Sub-epoch Fast Model Adaptation for Zero-shot Sketch-based Image Retrieval
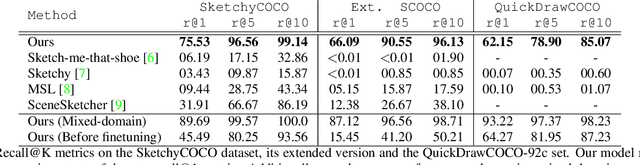
Mar 29, 2023Sketch-an-Anchor is a novel method to train state-of-the-art Zero-shot Sketch-based Image Retrieval (ZSSBIR) models in under an epoch. Most studies break down the problem of ZSSBIR into two parts: domain alignment between images and sketches, inherited from SBIR, and generalization to unseen data, inherent to the zero-shot protocol. We argue one of these problems can be considerably simplified and re-frame the ZSSBIR problem around the already-stellar yet underexplored Zero-shot Image-based Retrieval performance of off-the-shelf models. Our fast-converging model keeps the single-domain performance while learning to extract similar representations from sketches. To this end we introduce our Semantic Anchors -- guiding embeddings learned from word-based semantic spaces and features from off-the-shelf models -- and combine them with our novel Anchored Contrastive Loss. Empirical evidence shows we can achieve state-of-the-art performance on all benchmark datasets while training for 100x less iterations than other methods.
Training Deep Networks from Zero to Hero: avoiding pitfalls and going beyond
Sep 06, 2021
Training deep neural networks may be challenging in real world data. Using models as black-boxes, even with transfer learning, can result in poor generalization or inconclusive results when it comes to small datasets or specific applications. This tutorial covers the basic steps as well as more recent options to improve models, in particular, but not restricted to, supervised learning. It can be particularly useful in datasets that are not as well-prepared as those in challenges, and also under scarce annotation and/or small data. We describe basic procedures: as data preparation, optimization and transfer learning, but also recent architectural choices such as use of transformer modules, alternative convolutional layers, activation functions, wide and deep networks, as well as training procedures including as curriculum, contrastive and self-supervised learning.
Scene Designer: a Unified Model for Scene Search and Synthesis from Sketch
Aug 16, 2021
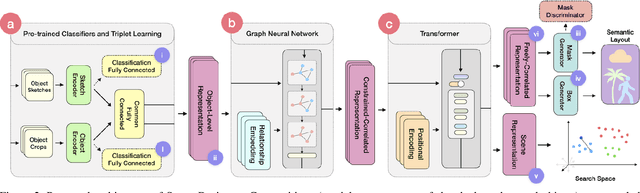
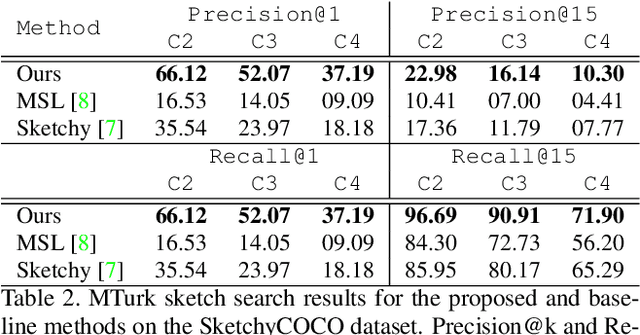
Scene Designer is a novel method for searching and generating images using free-hand sketches of scene compositions; i.e. drawings that describe both the appearance and relative positions of objects. Our core contribution is a single unified model to learn both a cross-modal search embedding for matching sketched compositions to images, and an object embedding for layout synthesis. We show that a graph neural network (GNN) followed by Transformer under our novel contrastive learning setting is required to allow learning correlations between object type, appearance and arrangement, driving a mask generation module that synthesises coherent scene layouts, whilst also delivering state of the art sketch based visual search of scenes.
Sketchformer: Transformer-based Representation for Sketched Structure
Feb 24, 2020


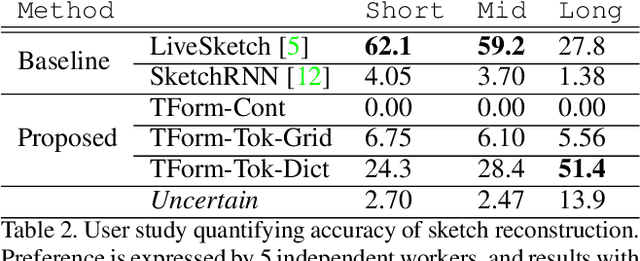
Sketchformer is a novel transformer-based representation for encoding free-hand sketches input in a vector form, i.e. as a sequence of strokes. Sketchformer effectively addresses multiple tasks: sketch classification, sketch based image retrieval (SBIR), and the reconstruction and interpolation of sketches. We report several variants exploring continuous and tokenized input representations, and contrast their performance. Our learned embedding, driven by a dictionary learning tokenization scheme, yields state of the art performance in classification and image retrieval tasks, when compared against baseline representations driven by LSTM sequence to sequence architectures: SketchRNN and derivatives. We show that sketch reconstruction and interpolation are improved significantly by the Sketchformer embedding for complex sketches with longer stroke sequences.