 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Designer: a Unified Model for Scene Search and Synthesis from Sketch
Aug 16, 2021
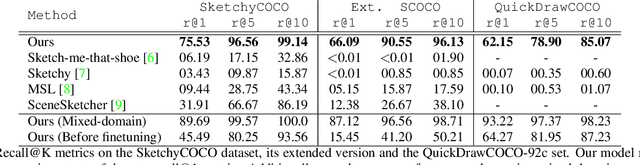
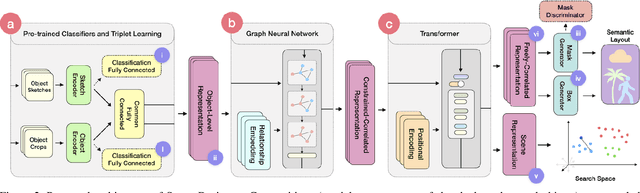
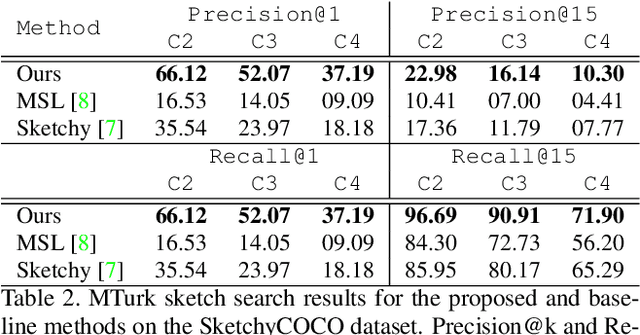
Scene Designer is a novel method for searching and generating images using free-hand sketches of scene compositions; i.e. drawings that describe both the appearance and relative positions of objects. Our core contribution is a single unified model to learn both a cross-modal search embedding for matching sketched compositions to images, and an object embedding for layout synthesis. We show that a graph neural network (GNN) followed by Transformer under our novel contrastive learning setting is required to allow learning correlations between object type, appearance and arrangement, driving a mask generation module that synthesises coherent scene layouts, whilst also delivering state of the art sketch based visual search of scenes.
A Visual Mining Approach to Improved Multiple-Instance Learning
Dec 14, 2020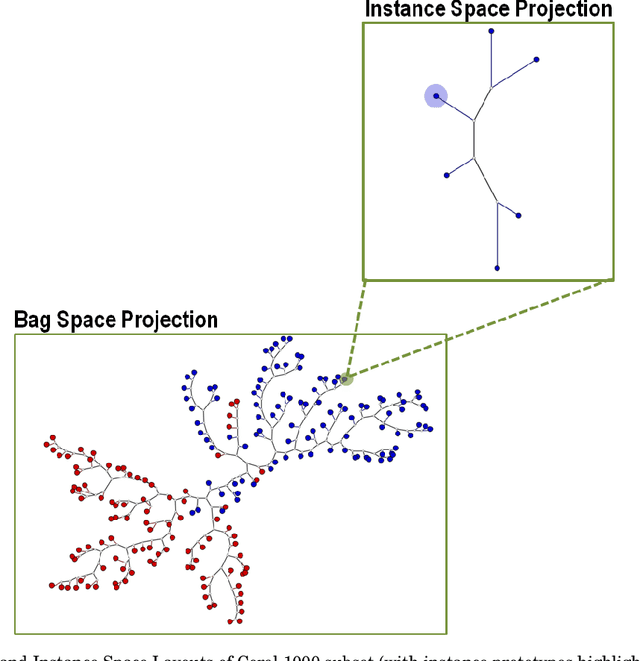
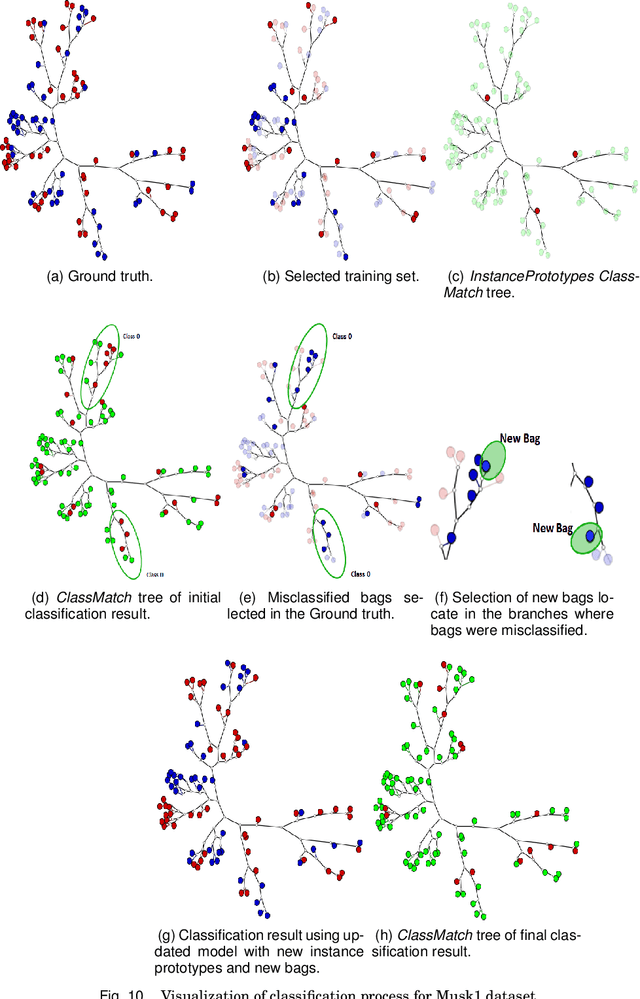

Multiple-instance learning (MIL) is a paradigm of machine learning that aims to classify a set (bag) of objects (instances), assigning labels only to the bags. This problem is often addressed by selecting an instance to represent each bag, transforming a MIL problem into a standard supervised learning. Visualization can be a useful tool to assess learning scenarios by incorporating the users' knowledge into the classification process. Considering that multiple-instance learning is a paradigm that cannot be handled by current visualization techniques, we propose a multiscale tree-based visualization to support MIL. The first level of the tree represents the bags, and the second level represents the instances belonging to each bag, allowing the user to understand the data in an intuitive way. In addition, we propose two new instance selection methods for MIL, which help the user to improve the model even further. Our methods are also able to handle both binary and multiclass scenarios. In our experiments, SVM was used to build the classifiers. With support of the MILTree layout, the initial classification model was updated by changing the training set - composed by the prototype instances. Experimental results validate the effectiveness of our approach, showing that visual mining by MILTree can help users in exploring and improving models in MIL scenarios, and that our instance selection methods over-perform current available alternatives in most cases.
Sketchformer: Transformer-based Representation for Sketched Structure
Feb 24, 2020


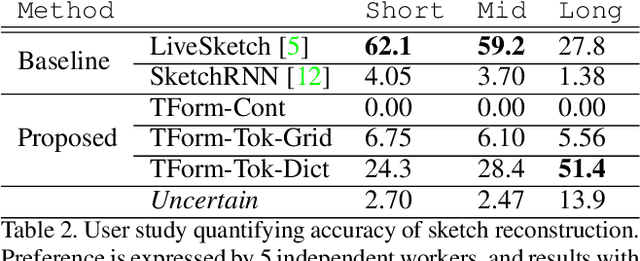
Sketchformer is a novel transformer-based representation for encoding free-hand sketches input in a vector form, i.e. as a sequence of strokes. Sketchformer effectively addresses multiple tasks: sketch classification, sketch based image retrieval (SBIR), and the reconstruction and interpolation of sketches. We report several variants exploring continuous and tokenized input representations, and contrast their performance. Our learned embedding, driven by a dictionary learning tokenization scheme, yields state of the art performance in classification and image retrieval tasks, when compared against baseline representations driven by LSTM sequence to sequence architectures: SketchRNN and derivatives. We show that sketch reconstruction and interpolation are improved significantly by the Sketchformer embedding for complex sketches with longer stroke sequences.
An incremental linear-time learning algorithm for the Optimum-Path Forest classifier
Nov 23, 2016
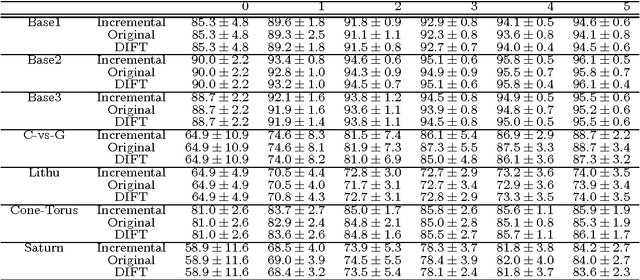
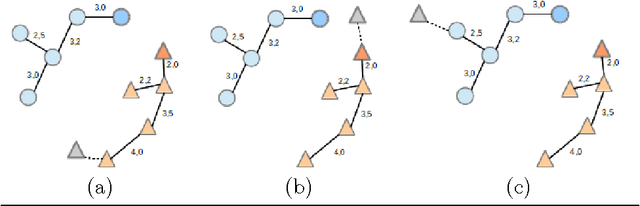
We present a classification method with incremental capabilities based on the Optimum-Path Forest classifier (OPF). The OPF considers instances as nodes of a fully-connected training graph, arc weights represent distances between two feature vectors. Our algorithm includes new instances in an OPF in linear-time, while keeping similar accuracies when compared with the original quadratic-time model.
Generalisation and Sharing in Triplet Convnets for Sketch based Visual Search
Nov 16, 2016



We propose and evaluate several triplet CNN architectures for measuring the similarity between sketches and photographs, within the context of the sketch based image retrieval (SBIR) task. In contrast to recent fine-grained SBIR work, we study the ability of our networks to generalise across diverse object categories from limited training data, and explore in detail strategies for weight sharing, pre-processing, data augmentation and dimensionality reduction. We exceed the performance of pre-existing techniques on both the Flickr15k category level SBIR benchmark by $18\%$, and the TU-Berlin SBIR benchmark by $\sim10 \mathcal{T}_b$, when trained on the 250 category TU-Berlin classification dataset augmented with 25k corresponding photographs harvested from the Internet.
An empirical study on the effects of different types of noise in image classification tasks
Sep 09, 2016
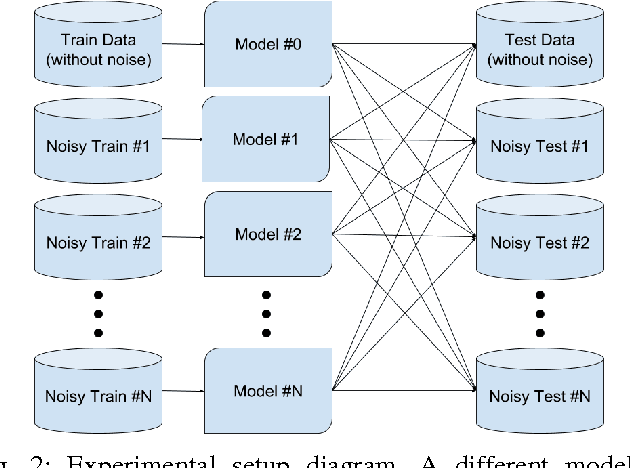

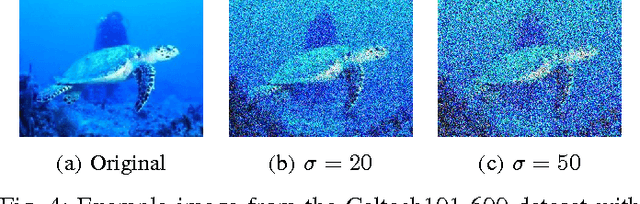
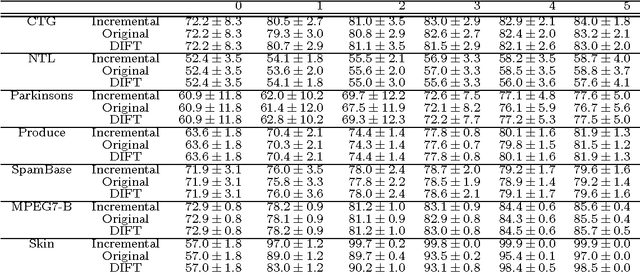
Image classification is one of the main research problems in computer vision and machine learning. Since in most real-world image classification applications there is no control over how the images are captured, it is necessary to consider the possibility that these images might be affected by noise (e.g. sensor noise in a low-quality surveillance camera). In this paper we analyse the impact of three different types of noise on descriptors extracted by two widely used feature extraction methods (LBP and HOG) and how denoising the images can help to mitigate this problem. We carry out experiments on two different datasets and consider several types of noise, noise levels, and denoising methods. Our results show that noise can hinder classification performance considerably and make classes harder to separate. Although denoising methods were not able to reach the same performance of the noise-free scenario, they improved classification results for noisy data.