 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Barlow Twins and VICReg self-supervised learning for sound patterns of bird and anuran species
Dec 18, 2023Taking advantage of the structure of large datasets to pre-train Deep Learning models is a promising strategy to decrease the need for supervised data. Self-supervised learning methods, such as contrastive and its variation are a promising way towards obtaining better representations in many Deep Learning applications. Soundscape ecology is one application in which annotations are expensive and scarce, therefore deserving investigation to approximate methods that do not require annotations to those that rely on supervision. Our study involves the use of the methods Barlow Twins and VICReg to pre-train different models with the same small dataset with sound patterns of bird and anuran species. In a downstream task to classify those animal species, the models obtained results close to supervised ones, pre-trained in large generic datasets, and fine-tuned with the same task.
Understanding High Dimensional Spaces through Visual Means Employing Multidimensional Projections
Jul 12, 2022



Data visualisation helps understanding data represented by multiple variables, also called features, stored in a large matrix where individuals are stored in lines and variable values in columns. These data structures are frequently called multidimensional spaces.In this paper, we illustrate ways of employing the visual results of multidimensional projection algorithms to understand and fine-tune the parameters of their mathematical framework. Some of the common mathematical common to these approaches are Laplacian matrices, Euclidian distance, Cosine distance, and statistical methods such as Kullback-Leibler divergence, employed to fit probability distributions and reduce dimensions. Two of the relevant algorithms in the data visualisation field are t-distributed stochastic neighbourhood embedding (t-SNE) and Least-Square Projection (LSP). These algorithms can be used to understand several ranges of mathematical functions including their impact on datasets. In this article, mathematical parameters of underlying techniques such as Principal Component Analysis (PCA) behind t-SNE and mesh reconstruction methods behind LSP are adjusted to reflect the properties afforded by the mathematical formulation. The results, supported by illustrative methods of the processes of LSP and t-SNE, are meant to inspire students in understanding the mathematics behind such methods, in order to apply them in effective data analysis tasks in multiple applications.
A Visual Analytics Approach to Building Logistic Regression Models and its Application to Health Records
Jan 20, 2022
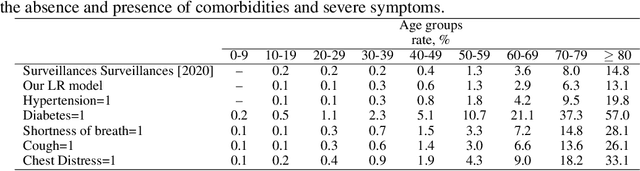


Multidimensional data analysis has become increasingly important in many fields, mainly due to current vast data availability and the increasing demand to extract knowledge from it. In most applications, the role of the final user is crucial to build proper machine learning models and to explain the patterns found in data. In this paper, we present an open unified approach for generating, evaluating, and applying regression models in high-dimensional data sets within a user-guided process. The approach is based on exposing a broad correlation panorama for attributes, by which the user can select relevant attributes to build and evaluate prediction models for one or more contexts. We name the approach UCReg (User-Centered Regression). We demonstrate effectiveness and efficiency of UCReg through the application of our framework to the analysis of Covid-19 and other synthetic and real health records data.
Implementing simple spectral denoising for environmental audio recordings
Jan 06, 2022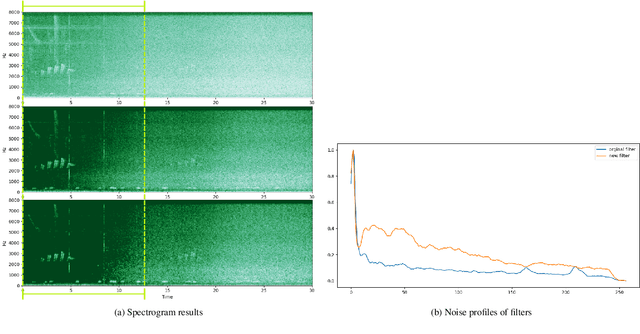
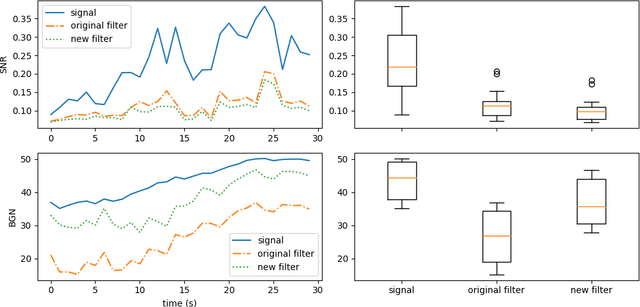

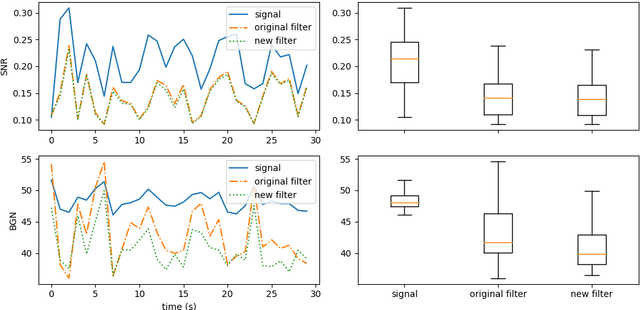
This technical report details changes applied to a noise filter to facilitate its application and improve its results. The filter is applied to denoise natural sounds recorded in the wild and to generate an acoustic index used in soundscape analysis.
A Visual Mining Approach to Improved Multiple-Instance Learning
Dec 14, 2020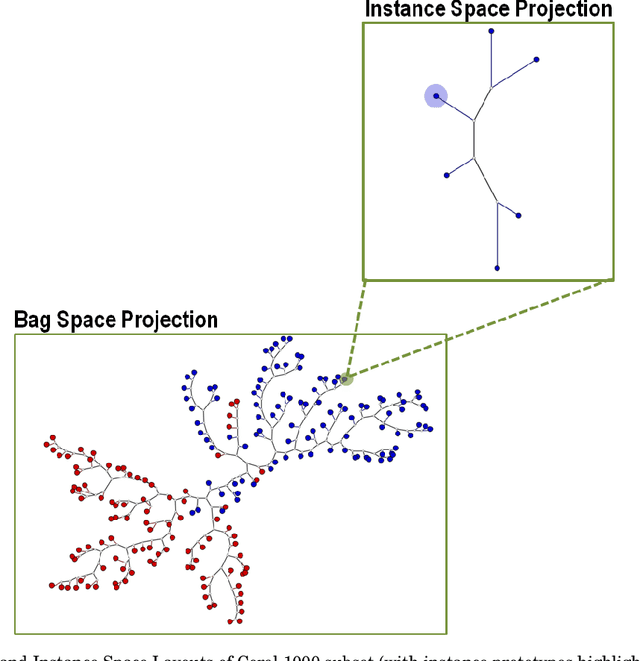
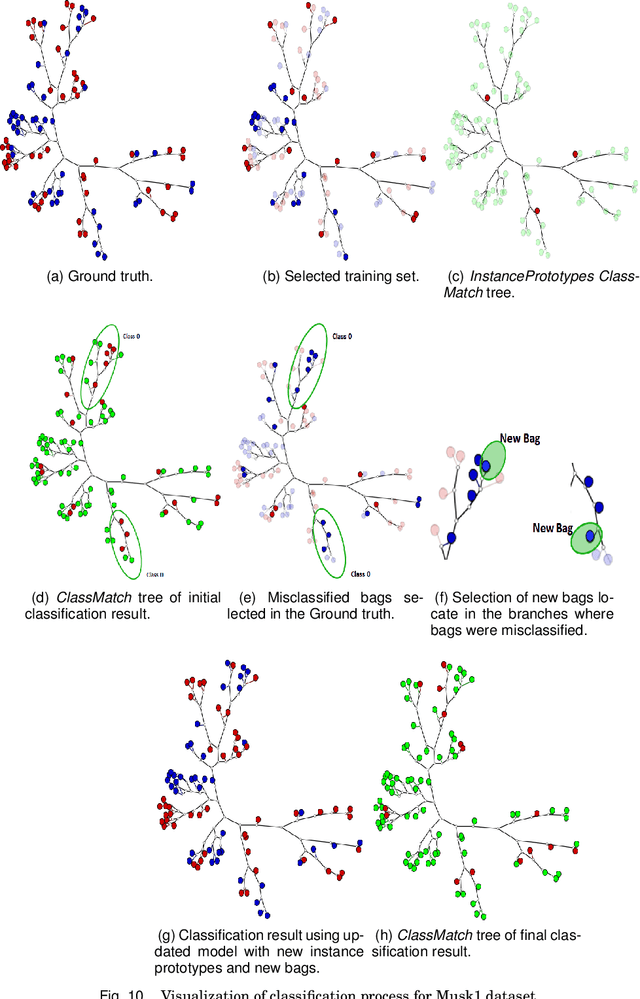

Multiple-instance learning (MIL) is a paradigm of machine learning that aims to classify a set (bag) of objects (instances), assigning labels only to the bags. This problem is often addressed by selecting an instance to represent each bag, transforming a MIL problem into a standard supervised learning. Visualization can be a useful tool to assess learning scenarios by incorporating the users' knowledge into the classification process. Considering that multiple-instance learning is a paradigm that cannot be handled by current visualization techniques, we propose a multiscale tree-based visualization to support MIL. The first level of the tree represents the bags, and the second level represents the instances belonging to each bag, allowing the user to understand the data in an intuitive way. In addition, we propose two new instance selection methods for MIL, which help the user to improve the model even further. Our methods are also able to handle both binary and multiclass scenarios. In our experiments, SVM was used to build the classifiers. With support of the MILTree layout, the initial classification model was updated by changing the training set - composed by the prototype instances. Experimental results validate the effectiveness of our approach, showing that visual mining by MILTree can help users in exploring and improving models in MIL scenarios, and that our instance selection methods over-perform current available alternatives in most cases.