 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing NURC/SP to Digital Life: the Role of Open-source Automatic Speech Recognition Models
Oct 14, 2022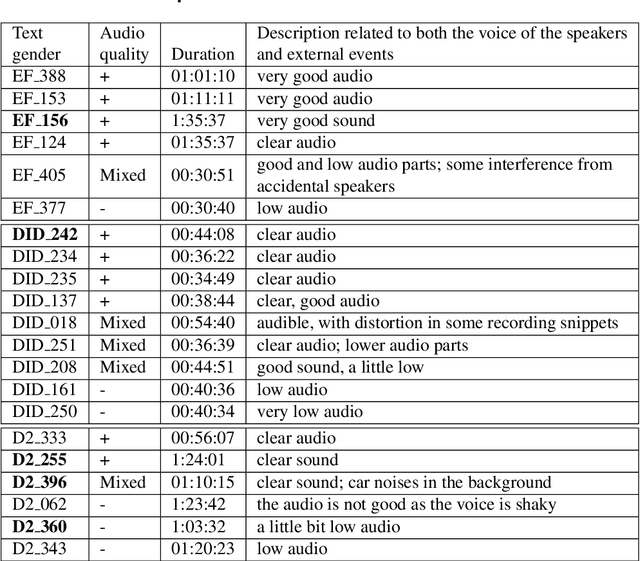

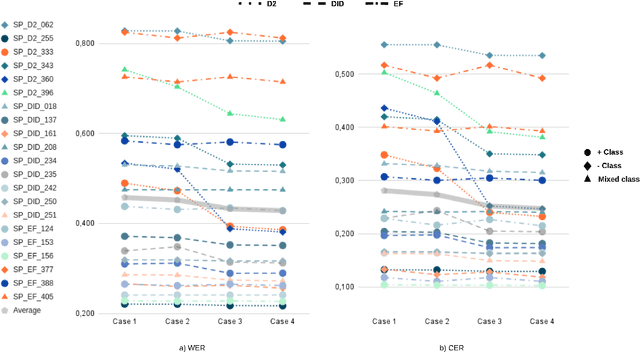
The NURC Project that started in 1969 to study the cultured linguistic urban norm spoken in five Brazilian capitals, was responsible for compiling a large corpus for each capital. The digitized NURC/SP comprises 375 inquiries in 334 hours of recordings taken in S\~ao Paulo capital. Although 47 inquiries have transcripts, there was no alignment between the audio-transcription, and 328 inquiries were not transcribed. This article presents an evaluation and error analysis of three automatic speech recognition models trained with spontaneous speech in Portuguese and one model trained with prepared speech. The evaluation allowed us to choose the best model, using WER and CER metrics, in a manually aligned sample of NURC/SP, to automatically transcribe 284 hours.
A single speaker is almost all you need for automatic speech recognition
Mar 29, 2022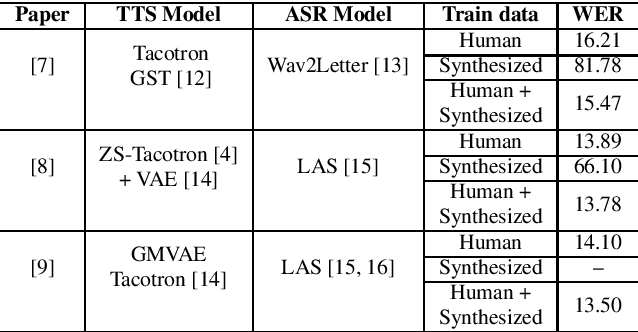
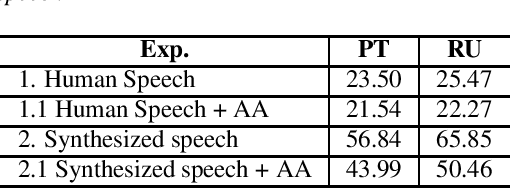

We explore the use of speech synthesis and voice conversion applied to augment datasets for automatic speech recognition (ASR) systems, in scenarios with only one speaker available for the target language. Through extensive experiments, we show that our approach achieves results compared to the state-of-the-art (SOTA) and requires only one speaker in the target language during speech synthesis/voice conversion model training. Finally, we show that it is possible to obtain promising results in the training of an ASR model with our data augmentation method and only a single real speaker in different target languages.
Automatic Classification of the Complexity of Nonfiction Texts in Portuguese for Early School Years
Apr 10, 2017
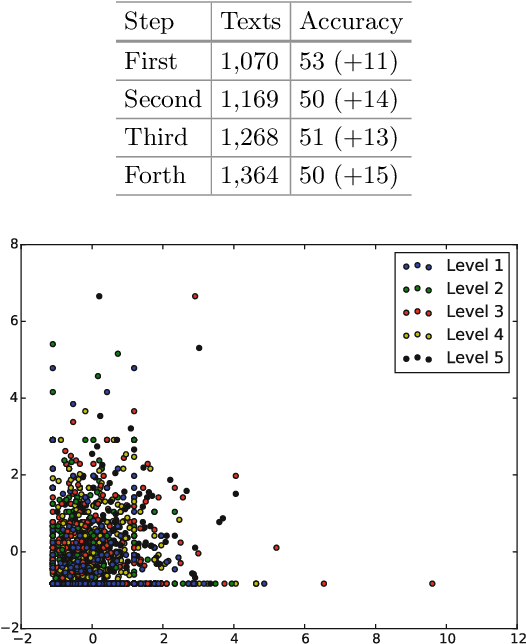
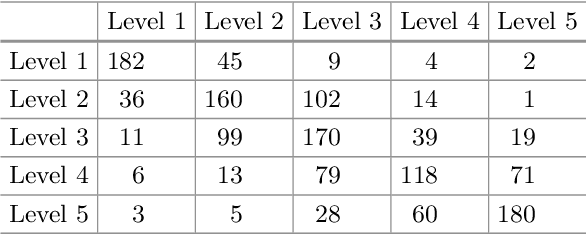
Recent research shows that most Brazilian students have serious problems regarding their reading skills. The full development of this skill is key for the academic and professional future of every citizen. Tools for classifying the complexity of reading materials for children aim to improve the quality of the model of teaching reading and text comprehension. For English, Fengs work [11] is considered the state-of-art in grade level prediction and achieved 74% of accuracy in automatically classifying 4 levels of textual complexity for close school grades. There are no classifiers for nonfiction texts for close grades in Portuguese. In this article, we propose a scheme for manual annotation of texts in 5 grade levels, which will be used for customized reading to avoid the lack of interest by students who are more advanced in reading and the blocking of those that still need to make further progress. We obtained 52% of accuracy in classifying texts into 5 levels and 74% in 3 levels. The results prove to be promising when compared to the state-of-art work.9
* PROPOR International Conference on the Computational Processing of Portuguese, 2016, 9 pages