 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNILC-Metrix: assessing the complexity of written and spoken language in Brazilian Portuguese
Dec 17, 2021
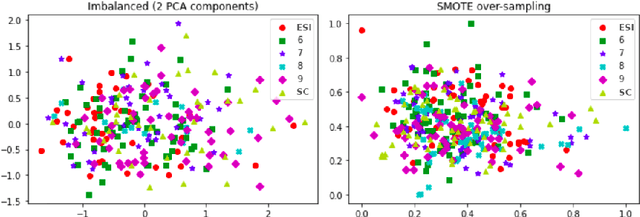

This paper presents and makes publicly available the NILC-Metrix, a computational system comprising 200 metrics proposed in studies on discourse, psycholinguistics, cognitive and computational linguistics, to assess textual complexity in Brazilian Portuguese (BP). These metrics are relevant for descriptive analysis and the creation of computational models and can be used to extract information from various linguistic levels of written and spoken language. The metrics in NILC-Metrix were developed during the last 13 years, starting in 2008 with Coh-Metrix-Port, a tool developed within the scope of the PorSimples project. Coh-Metrix-Port adapted some metrics to BP from the Coh-Metrix tool that computes metrics related to cohesion and coherence of texts in English. After the end of PorSimples in 2010, new metrics were added to the initial 48 metrics of Coh-Metrix-Port. Given the large number of metrics, we present them following an organisation similar to the metrics of Coh-Metrix v3.0 to facilitate comparisons made with metrics in Portuguese and English. In this paper, we illustrate the potential of NILC-Metrix by presenting three applications: (i) a descriptive analysis of the differences between children's film subtitles and texts written for Elementary School I and II (Final Years); (ii) a new predictor of textual complexity for the corpus of original and simplified texts of the PorSimples project; (iii) a complexity prediction model for school grades, using transcripts of children's story narratives told by teenagers. For each application, we evaluate which groups of metrics are more discriminative, showing their contribution for each task.
Automatic semantic role labeling on non-revised syntactic trees of journalistic texts
Apr 10, 2017
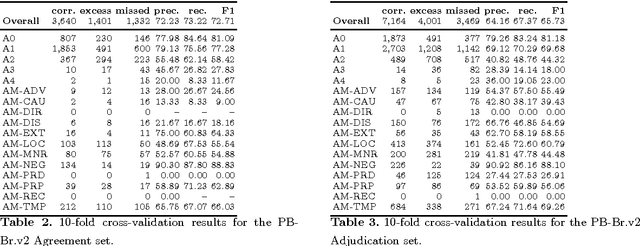
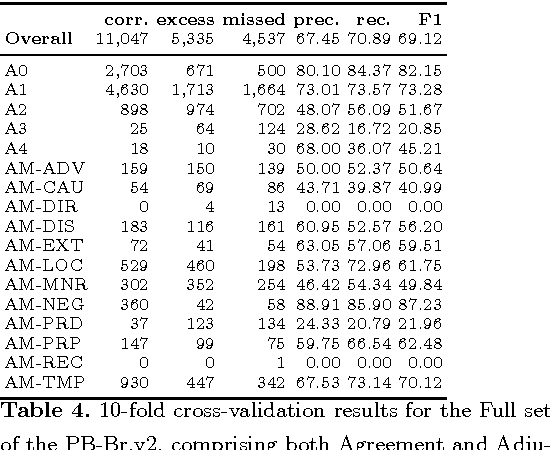
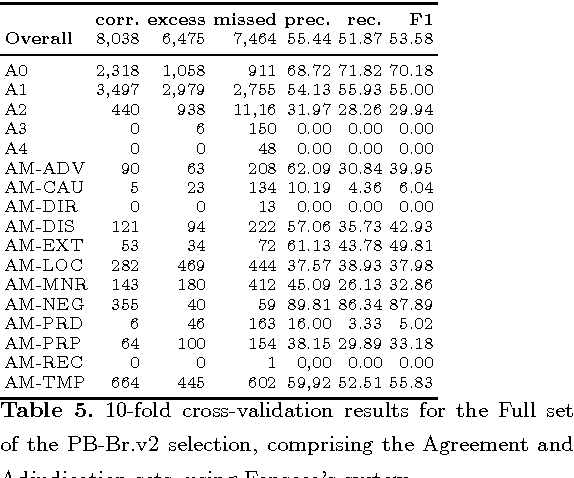
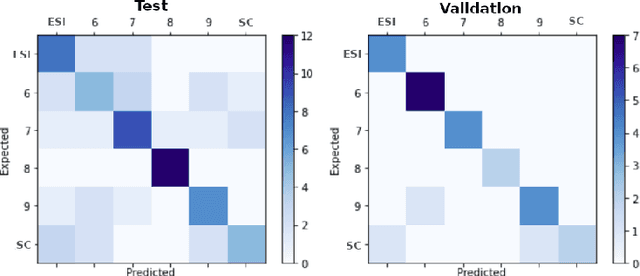
Semantic Role Labeling (SRL) is a Natural Language Processing task that enables the detection of events described in sentences and the participants of these events. For Brazilian Portuguese (BP), there are two studies recently concluded that perform SRL in journalistic texts. [1] obtained F1-measure scores of 79.6, using the PropBank.Br corpus, which has syntactic trees manually revised, [8], without using a treebank for training, obtained F1-measure scores of 68.0 for the same corpus. However, the use of manually revised syntactic trees for this task does not represent a real scenario of application. The goal of this paper is to evaluate the performance of SRL on revised and non-revised syntactic trees using a larger and balanced corpus of BP journalistic texts. First, we have shown that [1]'s system also performs better than [8]'s system on the larger corpus. Second, the SRL system trained on non-revised syntactic trees performs better over non-revised trees than a system trained on gold-standard data.
* PROPOR International Conference on the Computational Processing of Portuguese, 2016, 8 pages
Automatic Classification of the Complexity of Nonfiction Texts in Portuguese for Early School Years
Apr 10, 2017
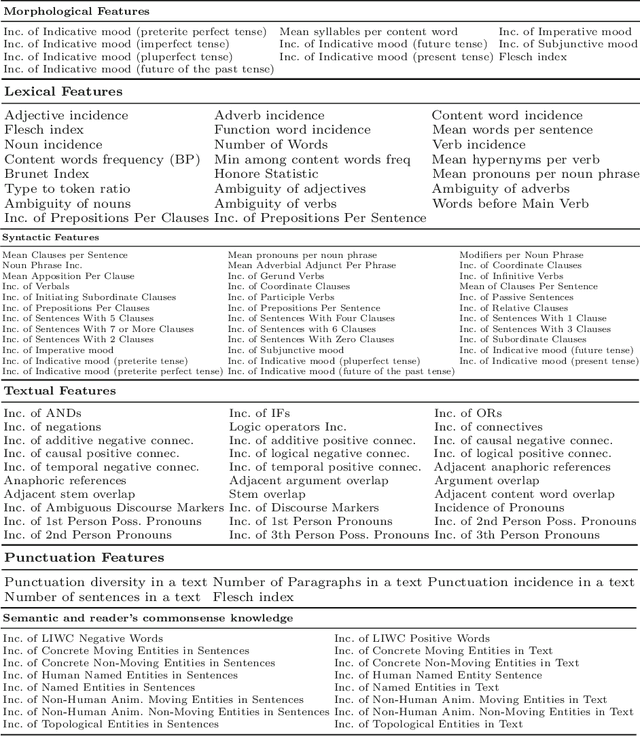
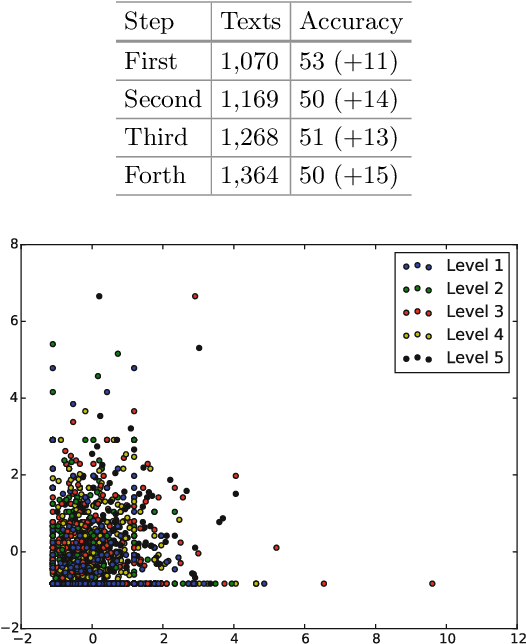
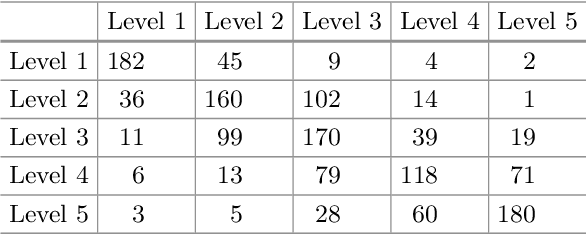
Recent research shows that most Brazilian students have serious problems regarding their reading skills. The full development of this skill is key for the academic and professional future of every citizen. Tools for classifying the complexity of reading materials for children aim to improve the quality of the model of teaching reading and text comprehension. For English, Fengs work [11] is considered the state-of-art in grade level prediction and achieved 74% of accuracy in automatically classifying 4 levels of textual complexity for close school grades. There are no classifiers for nonfiction texts for close grades in Portuguese. In this article, we propose a scheme for manual annotation of texts in 5 grade levels, which will be used for customized reading to avoid the lack of interest by students who are more advanced in reading and the blocking of those that still need to make further progress. We obtained 52% of accuracy in classifying texts into 5 levels and 74% in 3 levels. The results prove to be promising when compared to the state-of-art work.9
* PROPOR International Conference on the Computational Processing of Portuguese, 2016, 9 pages