 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating OpenAI's Whisper ASR for Punctuation Prediction and Topic Modeling of life histories of the Museum of the Person
May 26, 2023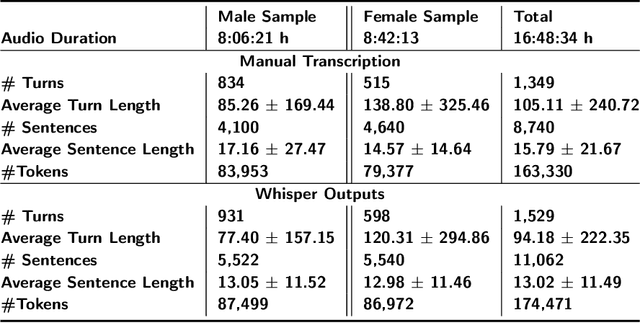
Automatic speech recognition (ASR) systems play a key role in applications involving human-machine interactions. Despite their importance, ASR models for the Portuguese language proposed in the last decade have limitations in relation to the correct identification of punctuation marks in automatic transcriptions, which hinder the use of transcriptions by other systems, models, and even by humans. However, recently Whisper ASR was proposed by OpenAI, a general-purpose speech recognition model that has generated great expectations in dealing with such limitations. This chapter presents the first study on the performance of Whisper for punctuation prediction in the Portuguese language. We present an experimental evaluation considering both theoretical aspects involving pausing points (comma) and complete ideas (exclamation, question, and fullstop), as well as practical aspects involving transcript-based topic modeling - an application dependent on punctuation marks for promising performance. We analyzed experimental results from videos of Museum of the Person, a virtual museum that aims to tell and preserve people's life histories, thus discussing the pros and cons of Whisper in a real-world scenario. Although our experiments indicate that Whisper achieves state-of-the-art results, we conclude that some punctuation marks require improvements, such as exclamation, semicolon and colon.
Interpretability Analysis of Deep Models for COVID-19 Detection
Nov 25, 2022
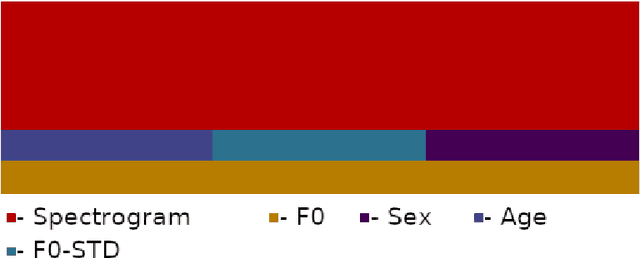
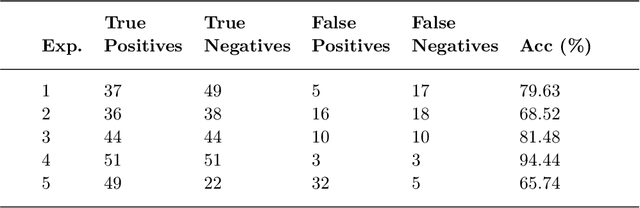
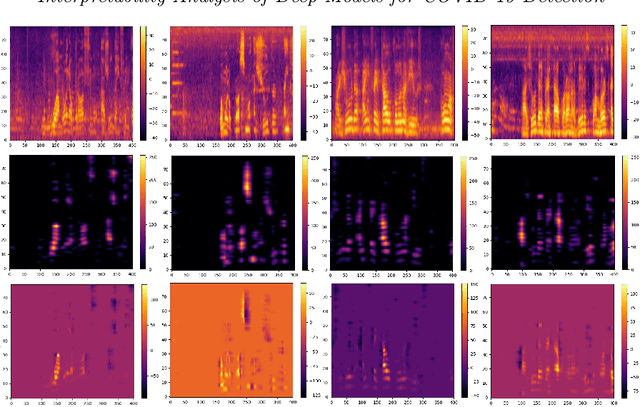
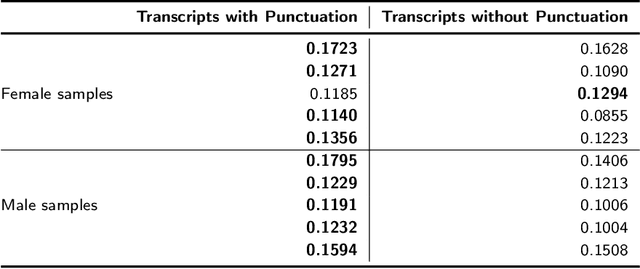
During the outbreak of COVID-19 pandemic, several research areas joined efforts to mitigate the damages caused by SARS-CoV-2. In this paper we present an interpretability analysis of a convolutional neural network based model for COVID-19 detection in audios. We investigate which features are important for model decision process, investigating spectrograms, F0, F0 standard deviation, sex and age. Following, we analyse model decisions by generating heat maps for the trained models to capture their attention during the decision process. Focusing on a explainable Inteligence Artificial approach, we show that studied models can taken unbiased decisions even in the presence of spurious data in the training set, given the adequate preprocessing steps. Our best model has 94.44% of accuracy in detection, with results indicating that models favors spectrograms for the decision process, particularly, high energy areas in the spectrogram related to prosodic domains, while F0 also leads to efficient COVID-19 detection.
NILC-Metrix: assessing the complexity of written and spoken language in Brazilian Portuguese
Dec 17, 2021

This paper presents and makes publicly available the NILC-Metrix, a computational system comprising 200 metrics proposed in studies on discourse, psycholinguistics, cognitive and computational linguistics, to assess textual complexity in Brazilian Portuguese (BP). These metrics are relevant for descriptive analysis and the creation of computational models and can be used to extract information from various linguistic levels of written and spoken language. The metrics in NILC-Metrix were developed during the last 13 years, starting in 2008 with Coh-Metrix-Port, a tool developed within the scope of the PorSimples project. Coh-Metrix-Port adapted some metrics to BP from the Coh-Metrix tool that computes metrics related to cohesion and coherence of texts in English. After the end of PorSimples in 2010, new metrics were added to the initial 48 metrics of Coh-Metrix-Port. Given the large number of metrics, we present them following an organisation similar to the metrics of Coh-Metrix v3.0 to facilitate comparisons made with metrics in Portuguese and English. In this paper, we illustrate the potential of NILC-Metrix by presenting three applications: (i) a descriptive analysis of the differences between children's film subtitles and texts written for Elementary School I and II (Final Years); (ii) a new predictor of textual complexity for the corpus of original and simplified texts of the PorSimples project; (iii) a complexity prediction model for school grades, using transcripts of children's story narratives told by teenagers. For each application, we evaluate which groups of metrics are more discriminative, showing their contribution for each task.
CORAA: a large corpus of spontaneous and prepared speech manually validated for speech recognition in Brazilian Portuguese
Oct 14, 2021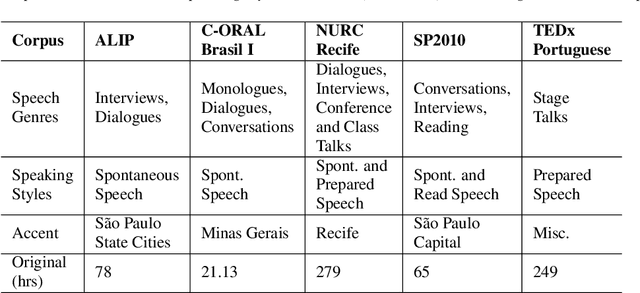
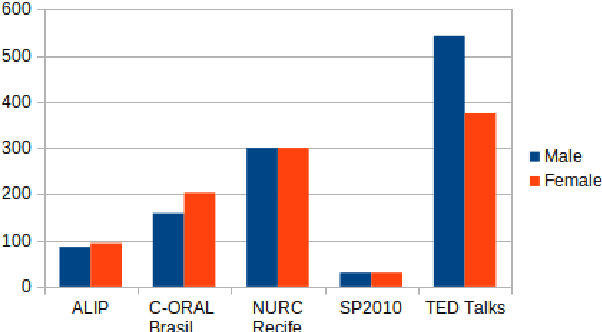
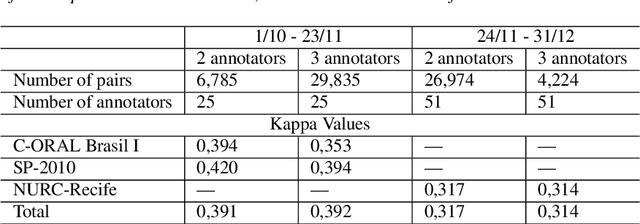
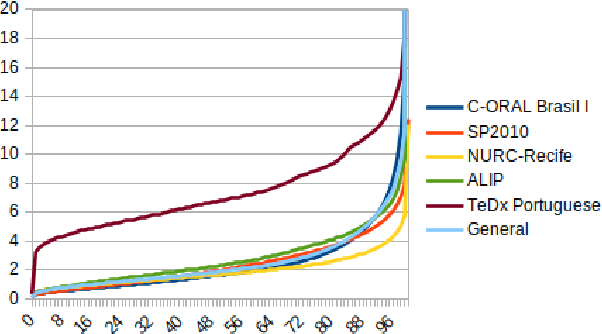
Automatic Speech recognition (ASR) is a complex and challenging task. In recent years, there have been significant advances in the area. In particular, for the Brazilian Portuguese (BP) language, there were about 376 hours public available for ASR task until the second half of 2020. With the release of new datasets in early 2021, this number increased to 574 hours. The existing resources, however, are composed of audios containing only read and prepared speech. There is a lack of datasets including spontaneous speech, which are essential in different ASR applications. This paper presents CORAA (Corpus of Annotated Audios) v1. with 291 hours, a publicly available dataset for ASR in BP containing validated pairs (audio-transcription). CORAA also contains European Portuguese audios (4.69 hours). We also present two public ASR models based on Wav2Vec 2.0 XLSR-53 and fine-tuned over CORAA. Our best model achieved a Word Error Rate of 27.35% on CORAA test set and 16.01% on Common Voice test set. When measuring the Character Error Rate, we obtained 14.26% and 5.45% for CORAA and Common Voice, respectively. CORAA corpora were assembled to both improve ASR models in BP with phenomena from spontaneous speech and motivate young researchers to start their studies on ASR for Portuguese. All the corpora are publicly available at https://github.com/nilc-nlp/CORAA under the CC BY-NC-ND 4.0 license.
MilkQA: a Dataset of Consumer Questions for the Task of Answer Selection
Jan 10, 2018
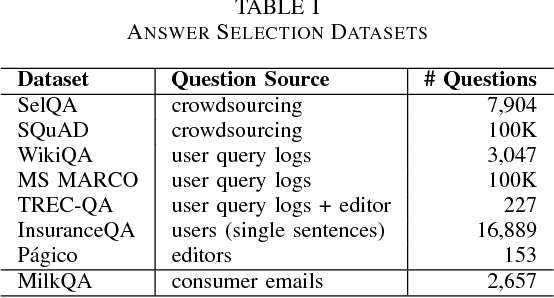
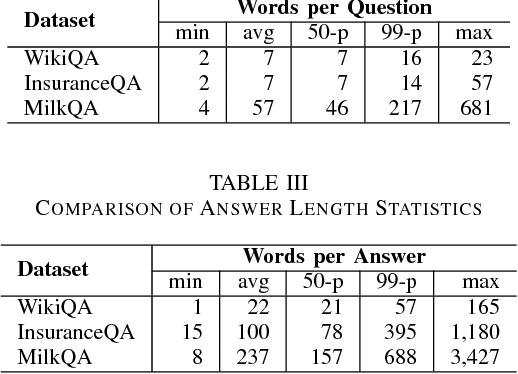
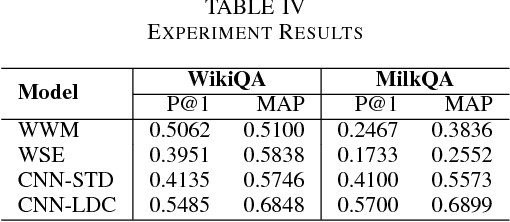
We introduce MilkQA, a question answering dataset from the dairy domain dedicated to the study of consumer questions. The dataset contains 2,657 pairs of questions and answers, written in the Portuguese language and originally collected by the Brazilian Agricultural Research Corporation (Embrapa). All questions were motivated by real situations and written by thousands of authors with very different backgrounds and levels of literacy, while answers were elaborated by specialists from Embrapa's customer service. Our dataset was filtered and anonymized by three human annotators. Consumer questions are a challenging kind of question that is usually employed as a form of seeking information. Although several question answering datasets are available, most of such resources are not suitable for research on answer selection models for consumer questions. We aim to fill this gap by making MilkQA publicly available. We study the behavior of four answer selection models on MilkQA: two baseline models and two convolutional neural network archictetures. Our results show that MilkQA poses real challenges to computational models, particularly due to linguistic characteristics of its questions and to their unusually longer lengths. Only one of the experimented models gives reasonable results, at the cost of high computational requirements.
* 6 pages
Sentence Segmentation in Narrative Transcripts from Neuropsychological Tests using Recurrent Convolutional Neural Networks
Aug 15, 2017
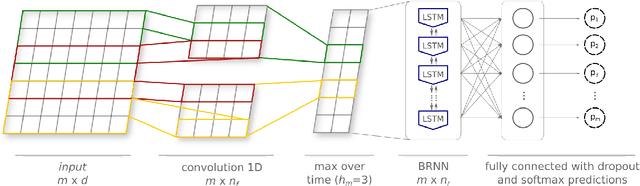
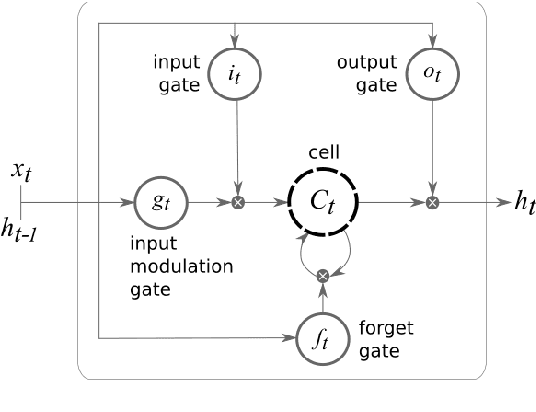
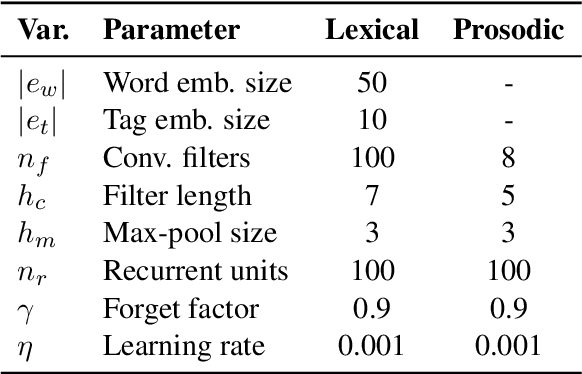
Automated discourse analysis tools based on Natural Language Processing (NLP) aiming at the diagnosis of language-impairing dementias generally extract several textual metrics of narrative transcripts. However, the absence of sentence boundary segmentation in the transcripts prevents the direct application of NLP methods which rely on these marks to function properly, such as taggers and parsers. We present the first steps taken towards automatic neuropsychological evaluation based on narrative discourse analysis, presenting a new automatic sentence segmentation method for impaired speech. Our model uses recurrent convolutional neural networks with prosodic, Part of Speech (PoS) features, and word embeddings. It was evaluated intrinsically on impaired, spontaneous speech, as well as, normal, prepared speech, and presents better results for healthy elderly (CTL) (F1 = 0.74) and Mild Cognitive Impairment (MCI) patients (F1 = 0.70) than the Conditional Random Fields method (F1 = 0.55 and 0.53, respectively) used in the same context of our study. The results suggest that our model is robust for impaired speech and can be used in automated discourse analysis tools to differentiate narratives produced by MCI and CTL.
Automatic semantic role labeling on non-revised syntactic trees of journalistic texts
Apr 10, 2017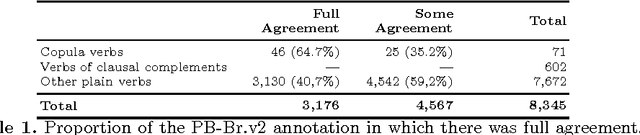
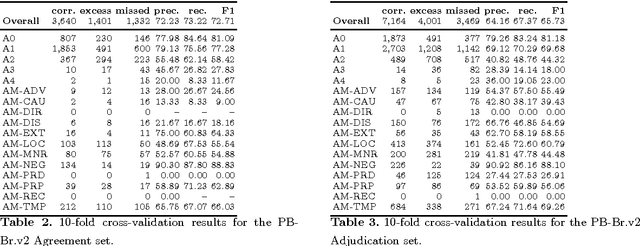
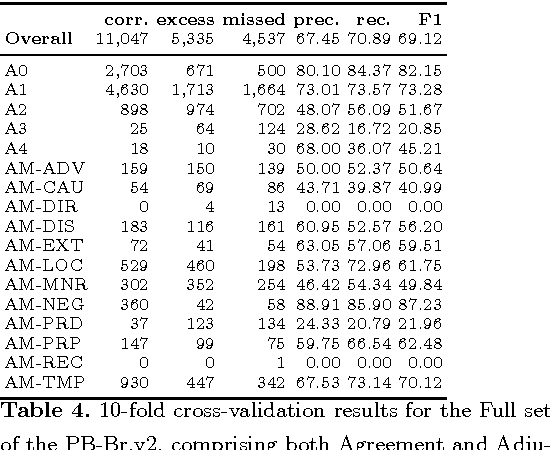
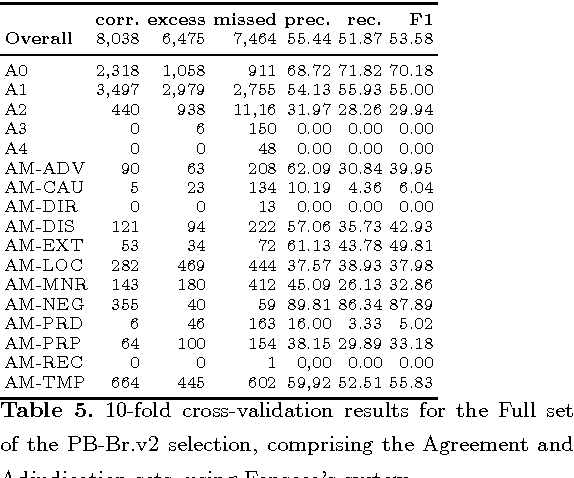
Semantic Role Labeling (SRL) is a Natural Language Processing task that enables the detection of events described in sentences and the participants of these events. For Brazilian Portuguese (BP), there are two studies recently concluded that perform SRL in journalistic texts. [1] obtained F1-measure scores of 79.6, using the PropBank.Br corpus, which has syntactic trees manually revised, [8], without using a treebank for training, obtained F1-measure scores of 68.0 for the same corpus. However, the use of manually revised syntactic trees for this task does not represent a real scenario of application. The goal of this paper is to evaluate the performance of SRL on revised and non-revised syntactic trees using a larger and balanced corpus of BP journalistic texts. First, we have shown that [1]'s system also performs better than [8]'s system on the larger corpus. Second, the SRL system trained on non-revised syntactic trees performs better over non-revised trees than a system trained on gold-standard data.
* PROPOR International Conference on the Computational Processing of Portuguese, 2016, 8 pages