 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Pre-trained Audio Models for COVID-19 Detection: A Technical Report
Nov 18, 2025This technical report investigates the performance of pre-trained audio models on COVID-19 detection tasks using established benchmark datasets. We fine-tuned Audio-MAE and three PANN architectures (CNN6, CNN10, CNN14) on the Coswara and COUGHVID datasets, evaluating both intra-dataset and cross-dataset generalization. We implemented a strict demographic stratification by age and gender to prevent models from exploiting spurious correlations between demographic characteristics and COVID-19 status. Intra-dataset results showed moderate performance, with Audio-MAE achieving the strongest result on Coswara (0.82 AUC, 0.76 F1-score), while all models demonstrated limited performance on Coughvid (AUC 0.58-0.63). Cross-dataset evaluation revealed severe generalization failure across all models (AUC 0.43-0.68), with Audio-MAE showing strong performance degradation (F1-score 0.00-0.08). Our experiments demonstrate that demographic balancing, while reducing apparent model performance, provides more realistic assessment of COVID-19 detection capabilities by eliminating demographic leakage - a confounding factor that inflate performance metrics. Additionally, the limited dataset sizes after balancing (1,219-2,160 samples) proved insufficient for deep learning models that typically require substantially larger training sets. These findings highlight fundamental challenges in developing generalizable audio-based COVID-19 detection systems and underscore the importance of rigorous demographic controls for clinically robust model evaluation.
Regional, Lattice and Logical Representations of Neural Networks
Jun 06, 2025



A possible path to the interpretability of neural networks is to (approximately) represent them in the regional format of piecewise linear functions, where regions of inputs are associated to linear functions computing the network outputs. We present an algorithm for the translation of feedforward neural networks with ReLU activation functions in hidden layers and truncated identity activation functions in the output layer. We also empirically investigate the complexity of regional representations outputted by our method for neural networks with varying sizes. Lattice and logical representations of neural networks are straightforward from regional representations as long as they satisfy a specific property. So we empirically investigate to what extent the translations by our algorithm satisfy such property.
* In Proceedings LSFA 2024, arXiv:2506.05219
Contrasting Deep Learning Models for Direct Respiratory Insufficiency Detection Versus Blood Oxygen Saturation Estimation
Jul 30, 2024



We contrast high effectiveness of state of the art deep learning architectures designed for general audio classification tasks, refined for respiratory insufficiency (RI) detection and blood oxygen saturation (SpO2) estimation and classification through automated audio analysis. Recently, multiple deep learning architectures have been proposed to detect RI in COVID patients through audio analysis, achieving accuracy above 95% and F1-score above 0.93. RI is a condition associated with low SpO2 levels, commonly defined as the threshold SpO2 <92%. While SpO2 serves as a crucial determinant of RI, a medical doctor's diagnosis typically relies on multiple factors. These include respiratory frequency, heart rate, SpO2 levels, among others. Here we study pretrained audio neural networks (CNN6, CNN10 and CNN14) and the Masked Autoencoder (Audio-MAE) for RI detection, where these models achieve near perfect accuracy, surpassing previous results. Yet, for the regression task of estimating SpO2 levels, the models achieve root mean square error values exceeding the accepted clinical range of 3.5% for finger oximeters. Additionally, Pearson correlation coefficients fail to surpass 0.3. As deep learning models perform better in classification than regression, we transform SpO2-regression into a SpO2-threshold binary classification problem, with a threshold of 92%. However, this task still yields an F1-score below 0.65. Thus, audio analysis offers valuable insights into a patient's RI status, but does not provide accurate information about actual SpO2 levels, indicating a separation of domains in which voice and speech biomarkers may and may not be useful in medical diagnostics under current technologies.
Discriminant audio properties in deep learning based respiratory insufficiency detection in Brazilian Portuguese
May 27, 2024This work investigates Artificial Intelligence (AI) systems that detect respiratory insufficiency (RI) by analyzing speech audios, thus treating speech as a RI biomarker. Previous works collected RI data (P1) from COVID-19 patients during the first phase of the pandemic and trained modern AI models, such as CNNs and Transformers, which achieved $96.5\%$ accuracy, showing the feasibility of RI detection via AI. Here, we collect RI patient data (P2) with several causes besides COVID-19, aiming at extending AI-based RI detection. We also collected control data from hospital patients without RI. We show that the considered models, when trained on P1, do not generalize to P2, indicating that COVID-19 RI has features that may not be found in all RI types.
* 5 pages, 2 figures, 1 table. Published in Artificial Intelligence in Medicine (AIME) 2023
PeLLE: Encoder-based language models for Brazilian Portuguese based on open data
Feb 29, 2024



In this paper we present PeLLE, a family of large language models based on the RoBERTa architecture, for Brazilian Portuguese, trained on curated, open data from the Carolina corpus. Aiming at reproducible results, we describe details of the pretraining of the models. We also evaluate PeLLE models against a set of existing multilingual and PT-BR refined pretrained Transformer-based LLM encoders, contrasting performance of large versus smaller-but-curated pretrained models in several downstream tasks. We conclude that several tasks perform better with larger models, but some tasks benefit from smaller-but-curated data in its pretraining.
Acoustic models of Brazilian Portuguese Speech based on Neural Transformers
Dec 14, 2023



An acoustic model, trained on a significant amount of unlabeled data, consists of a self-supervised learned speech representation useful for solving downstream tasks, perhaps after a fine-tuning of the model in the respective downstream task. In this work, we build an acoustic model of Brazilian Portuguese Speech through a Transformer neural network. This model was pretrained on more than $800$ hours of Brazilian Portuguese Speech, using a combination of pretraining techniques. Using a labeled dataset collected for the detection of respiratory insufficiency in Brazilian Portuguese speakers, we fine-tune the pretrained Transformer neural network on the following tasks: respiratory insufficiency detection, gender recognition and age group classification. We compare the performance of pretrained Transformers on these tasks with that of Transformers without previous pretraining, noting a significant improvement. In particular, the performance of respiratory insufficiency detection obtains the best reported results so far, indicating this kind of acoustic model as a promising tool for speech-as-biomarker approach. Moreover, the performance of gender recognition is comparable to the state of the art models in English.
Carolina: a General Corpus of Contemporary Brazilian Portuguese with Provenance, Typology and Versioning Information
Mar 28, 2023


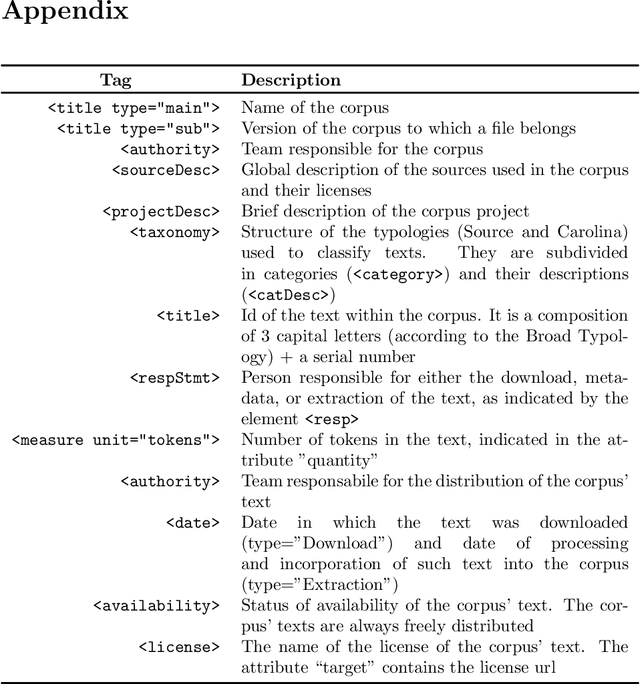
This paper presents the first publicly available version of the Carolina Corpus and discusses its future directions. Carolina is a large open corpus of Brazilian Portuguese texts under construction using web-as-corpus methodology enhanced with provenance, typology, versioning, and text integrality. The corpus aims at being used both as a reliable source for research in Linguistics and as an important resource for Computer Science research on language models, contributing towards removing Portuguese from the set of low-resource languages. Here we present the construction of the corpus methodology, comparing it with other existing methodologies, as well as the corpus current state: Carolina's first public version has $653,322,577$ tokens, distributed over $7$ broad types. Each text is annotated with several different metadata categories in its header, which we developed using TEI annotation standards. We also present ongoing derivative works and invite NLP researchers to contribute with their own.
Interpretability Analysis of Deep Models for COVID-19 Detection
Nov 25, 2022
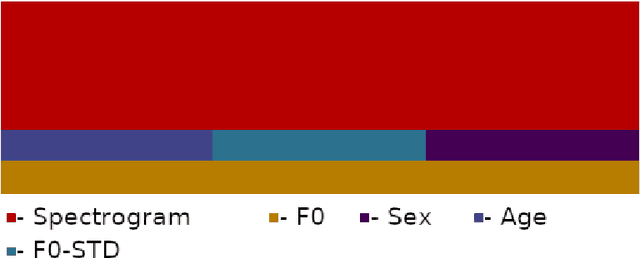
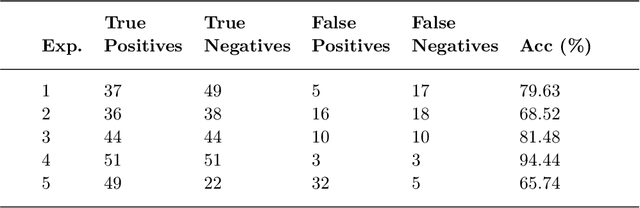
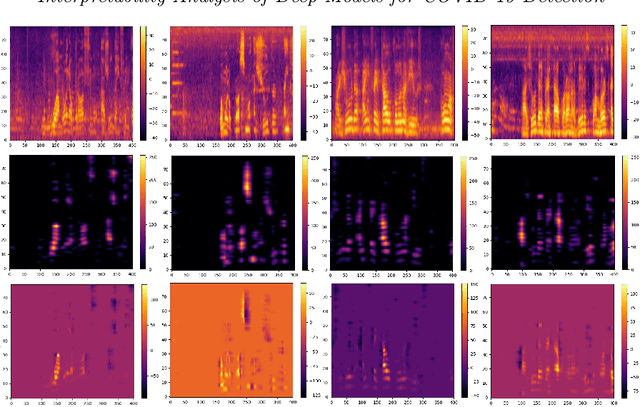
During the outbreak of COVID-19 pandemic, several research areas joined efforts to mitigate the damages caused by SARS-CoV-2. In this paper we present an interpretability analysis of a convolutional neural network based model for COVID-19 detection in audios. We investigate which features are important for model decision process, investigating spectrograms, F0, F0 standard deviation, sex and age. Following, we analyse model decisions by generating heat maps for the trained models to capture their attention during the decision process. Focusing on a explainable Inteligence Artificial approach, we show that studied models can taken unbiased decisions even in the presence of spurious data in the training set, given the adequate preprocessing steps. Our best model has 94.44% of accuracy in detection, with results indicating that models favors spectrograms for the decision process, particularly, high energy areas in the spectrogram related to prosodic domains, while F0 also leads to efficient COVID-19 detection.
Pretrained audio neural networks for Speech emotion recognition in Portuguese
Oct 26, 2022The goal of speech emotion recognition (SER) is to identify the emotional aspects of speech. The SER challenge for Brazilian Portuguese speech was proposed with short snippets of Portuguese which are classified as neutral, non-neutral female and non-neutral male according to paralinguistic elements (laughing, crying, etc). This dataset contains about $50$ minutes of Brazilian Portuguese speech. As the dataset leans on the small side, we investigate whether a combination of transfer learning and data augmentation techniques can produce positive results. Thus, by combining a data augmentation technique called SpecAugment, with the use of Pretrained Audio Neural Networks (PANNs) for transfer learning we are able to obtain interesting results. The PANNs (CNN6, CNN10 and CNN14) are pretrained on a large dataset called AudioSet containing more than $5000$ hours of audio. They were finetuned on the SER dataset and the best performing model (CNN10) on the validation set was submitted to the challenge, achieving an $F1$ score of $0.73$ up from $0.54$ from the baselines provided by the challenge. Moreover, we also tested the use of Transformer neural architecture, pretrained on about $600$ hours of Brazilian Portuguese audio data. Transformers, as well as more complex models of PANNs (CNN14), fail to generalize to the test set in the SER dataset and do not beat the baseline. Considering the limitation of the dataset sizes, currently the best approach for SER is using PANNs (specifically, CNN6 and CNN10).
Audio MFCC-gram Transformers for respiratory insufficiency detection in COVID-19
Oct 25, 2022



This work explores speech as a biomarker and investigates the detection of respiratory insufficiency (RI) by analyzing speech samples. Previous work \cite{spira2021} constructed a dataset of respiratory insufficiency COVID-19 patient utterances and analyzed it by means of a convolutional neural network achieving an accuracy of $87.04\%$, validating the hypothesis that one can detect RI through speech. Here, we study how Transformer neural network architectures can improve the performance on RI detection. This approach enables construction of an acoustic model. By choosing the correct pretraining technique, we generate a self-supervised acoustic model, leading to improved performance ($96.53\%$) of Transformers for RI detection.