 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrasting Deep Learning Models for Direct Respiratory Insufficiency Detection Versus Blood Oxygen Saturation Estimation
Jul 30, 2024



We contrast high effectiveness of state of the art deep learning architectures designed for general audio classification tasks, refined for respiratory insufficiency (RI) detection and blood oxygen saturation (SpO2) estimation and classification through automated audio analysis. Recently, multiple deep learning architectures have been proposed to detect RI in COVID patients through audio analysis, achieving accuracy above 95% and F1-score above 0.93. RI is a condition associated with low SpO2 levels, commonly defined as the threshold SpO2 <92%. While SpO2 serves as a crucial determinant of RI, a medical doctor's diagnosis typically relies on multiple factors. These include respiratory frequency, heart rate, SpO2 levels, among others. Here we study pretrained audio neural networks (CNN6, CNN10 and CNN14) and the Masked Autoencoder (Audio-MAE) for RI detection, where these models achieve near perfect accuracy, surpassing previous results. Yet, for the regression task of estimating SpO2 levels, the models achieve root mean square error values exceeding the accepted clinical range of 3.5% for finger oximeters. Additionally, Pearson correlation coefficients fail to surpass 0.3. As deep learning models perform better in classification than regression, we transform SpO2-regression into a SpO2-threshold binary classification problem, with a threshold of 92%. However, this task still yields an F1-score below 0.65. Thus, audio analysis offers valuable insights into a patient's RI status, but does not provide accurate information about actual SpO2 levels, indicating a separation of domains in which voice and speech biomarkers may and may not be useful in medical diagnostics under current technologies.
Discriminant audio properties in deep learning based respiratory insufficiency detection in Brazilian Portuguese
May 27, 2024This work investigates Artificial Intelligence (AI) systems that detect respiratory insufficiency (RI) by analyzing speech audios, thus treating speech as a RI biomarker. Previous works collected RI data (P1) from COVID-19 patients during the first phase of the pandemic and trained modern AI models, such as CNNs and Transformers, which achieved $96.5\%$ accuracy, showing the feasibility of RI detection via AI. Here, we collect RI patient data (P2) with several causes besides COVID-19, aiming at extending AI-based RI detection. We also collected control data from hospital patients without RI. We show that the considered models, when trained on P1, do not generalize to P2, indicating that COVID-19 RI has features that may not be found in all RI types.
* 5 pages, 2 figures, 1 table. Published in Artificial Intelligence in Medicine (AIME) 2023
Bringing NURC/SP to Digital Life: the Role of Open-source Automatic Speech Recognition Models
Oct 14, 2022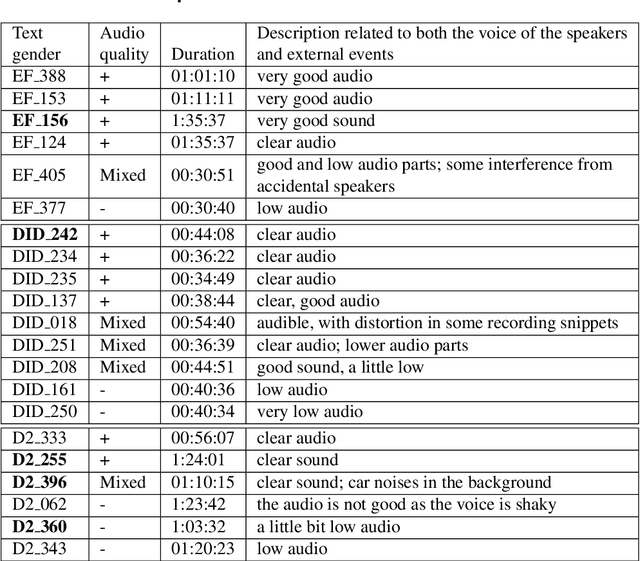

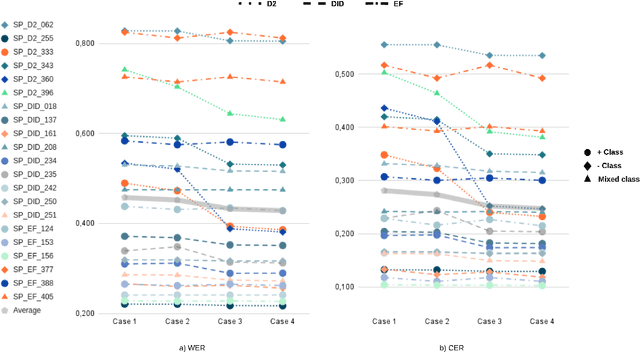
The NURC Project that started in 1969 to study the cultured linguistic urban norm spoken in five Brazilian capitals, was responsible for compiling a large corpus for each capital. The digitized NURC/SP comprises 375 inquiries in 334 hours of recordings taken in S\~ao Paulo capital. Although 47 inquiries have transcripts, there was no alignment between the audio-transcription, and 328 inquiries were not transcribed. This article presents an evaluation and error analysis of three automatic speech recognition models trained with spontaneous speech in Portuguese and one model trained with prepared speech. The evaluation allowed us to choose the best model, using WER and CER metrics, in a manually aligned sample of NURC/SP, to automatically transcribe 284 hours.