 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating OpenAI's Whisper ASR for Punctuation Prediction and Topic Modeling of life histories of the Museum of the Person
May 26, 2023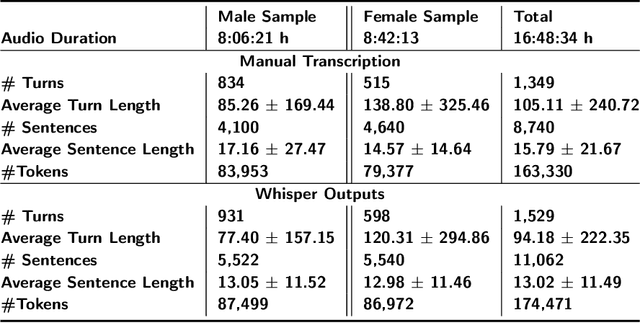
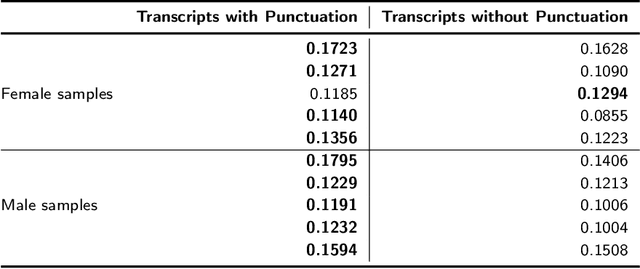
Automatic speech recognition (ASR) systems play a key role in applications involving human-machine interactions. Despite their importance, ASR models for the Portuguese language proposed in the last decade have limitations in relation to the correct identification of punctuation marks in automatic transcriptions, which hinder the use of transcriptions by other systems, models, and even by humans. However, recently Whisper ASR was proposed by OpenAI, a general-purpose speech recognition model that has generated great expectations in dealing with such limitations. This chapter presents the first study on the performance of Whisper for punctuation prediction in the Portuguese language. We present an experimental evaluation considering both theoretical aspects involving pausing points (comma) and complete ideas (exclamation, question, and fullstop), as well as practical aspects involving transcript-based topic modeling - an application dependent on punctuation marks for promising performance. We analyzed experimental results from videos of Museum of the Person, a virtual museum that aims to tell and preserve people's life histories, thus discussing the pros and cons of Whisper in a real-world scenario. Although our experiments indicate that Whisper achieves state-of-the-art results, we conclude that some punctuation marks require improvements, such as exclamation, semicolon and colon.