 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating OpenAI's Whisper ASR for Punctuation Prediction and Topic Modeling of life histories of the Museum of the Person
May 26, 2023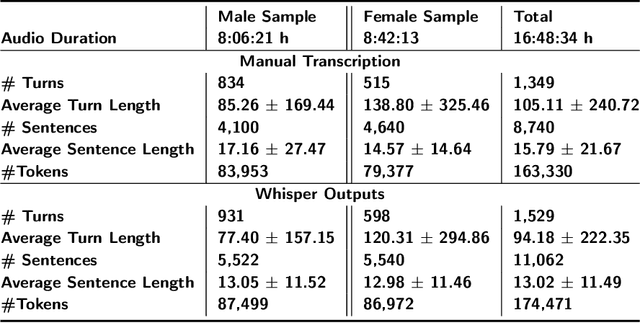
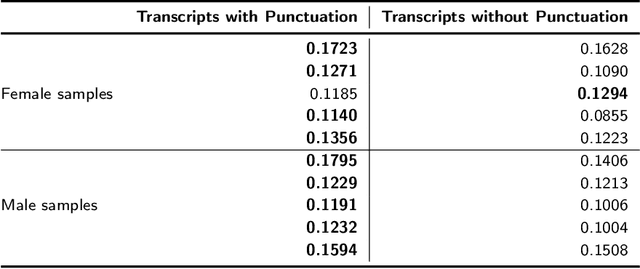
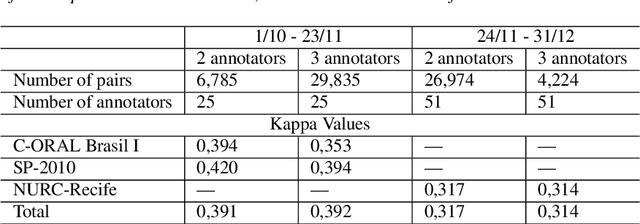
Automatic speech recognition (ASR) systems play a key role in applications involving human-machine interactions. Despite their importance, ASR models for the Portuguese language proposed in the last decade have limitations in relation to the correct identification of punctuation marks in automatic transcriptions, which hinder the use of transcriptions by other systems, models, and even by humans. However, recently Whisper ASR was proposed by OpenAI, a general-purpose speech recognition model that has generated great expectations in dealing with such limitations. This chapter presents the first study on the performance of Whisper for punctuation prediction in the Portuguese language. We present an experimental evaluation considering both theoretical aspects involving pausing points (comma) and complete ideas (exclamation, question, and fullstop), as well as practical aspects involving transcript-based topic modeling - an application dependent on punctuation marks for promising performance. We analyzed experimental results from videos of Museum of the Person, a virtual museum that aims to tell and preserve people's life histories, thus discussing the pros and cons of Whisper in a real-world scenario. Although our experiments indicate that Whisper achieves state-of-the-art results, we conclude that some punctuation marks require improvements, such as exclamation, semicolon and colon.
CORAA: a large corpus of spontaneous and prepared speech manually validated for speech recognition in Brazilian Portuguese
Oct 14, 2021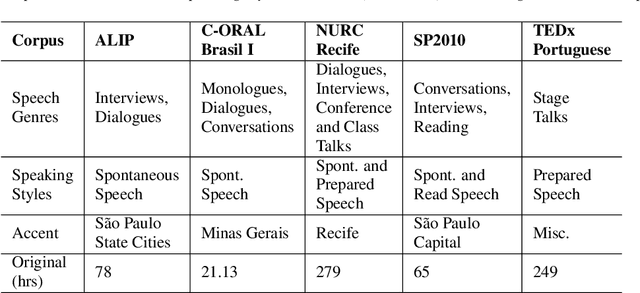
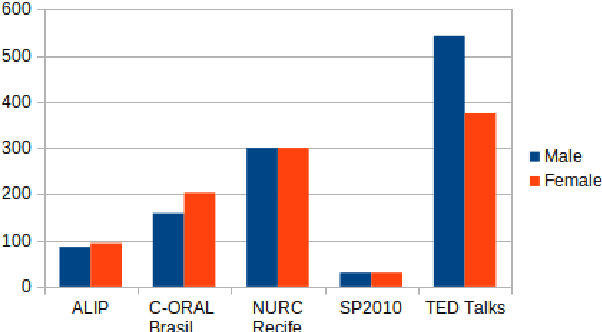
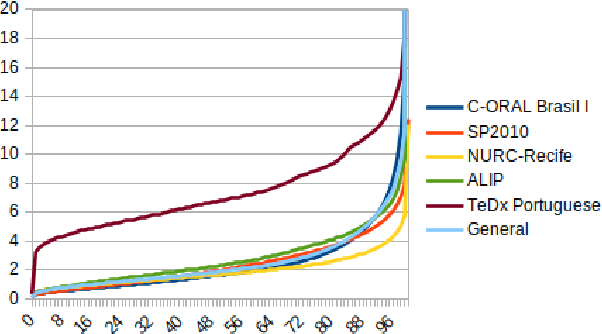
Automatic Speech recognition (ASR) is a complex and challenging task. In recent years, there have been significant advances in the area. In particular, for the Brazilian Portuguese (BP) language, there were about 376 hours public available for ASR task until the second half of 2020. With the release of new datasets in early 2021, this number increased to 574 hours. The existing resources, however, are composed of audios containing only read and prepared speech. There is a lack of datasets including spontaneous speech, which are essential in different ASR applications. This paper presents CORAA (Corpus of Annotated Audios) v1. with 291 hours, a publicly available dataset for ASR in BP containing validated pairs (audio-transcription). CORAA also contains European Portuguese audios (4.69 hours). We also present two public ASR models based on Wav2Vec 2.0 XLSR-53 and fine-tuned over CORAA. Our best model achieved a Word Error Rate of 27.35% on CORAA test set and 16.01% on Common Voice test set. When measuring the Character Error Rate, we obtained 14.26% and 5.45% for CORAA and Common Voice, respectively. CORAA corpora were assembled to both improve ASR models in BP with phenomena from spontaneous speech and motivate young researchers to start their studies on ASR for Portuguese. All the corpora are publicly available at https://github.com/nilc-nlp/CORAA under the CC BY-NC-ND 4.0 license.
Hybrid Model with Time Modeling for Sequential Recommender Systems
Mar 07, 2021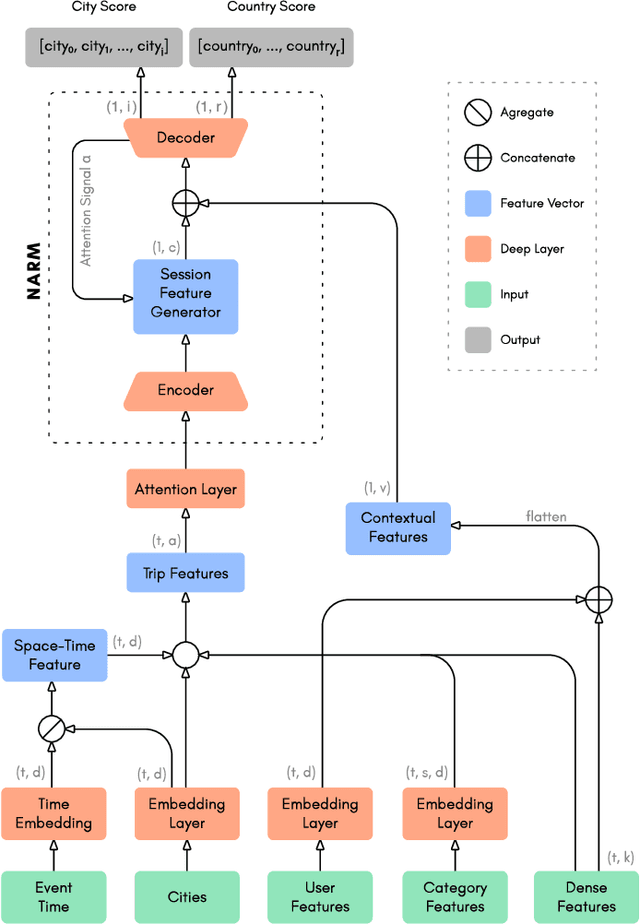
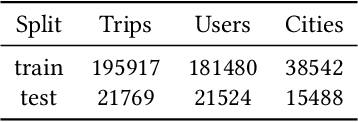

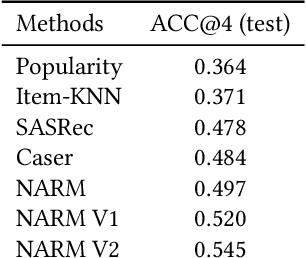
Deep learning based methods have been used successfully in recommender system problems. Approaches using recurrent neural networks, transformers, and attention mechanisms are useful to model users' long- and short-term preferences in sequential interactions. To explore different session-based recommendation solutions, Booking.com recently organized the WSDM WebTour 2021 Challenge, which aims to benchmark models to recommend the final city in a trip. This study presents our approach to this challenge. We conducted several experiments to test different state-of-the-art deep learning architectures for recommender systems. Further, we proposed some changes to Neural Attentive Recommendation Machine (NARM), adapted its architecture for the challenge objective, and implemented training approaches that can be used in any session-based model to improve accuracy. Our experimental result shows that the improved NARM outperforms all other state-of-the-art benchmark methods.
* 5 pages, 2 figures, WSDM Workshop on Web Tourism 2021
MARS-Gym: A Gym framework to model, train, and evaluate Recommender Systems for Marketplaces
Sep 30, 2020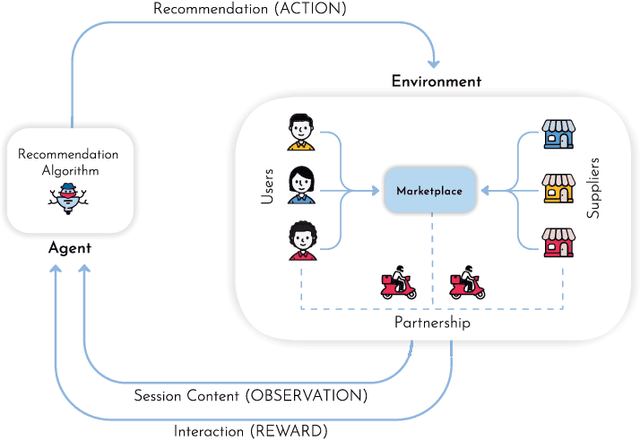
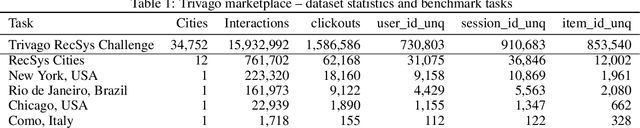
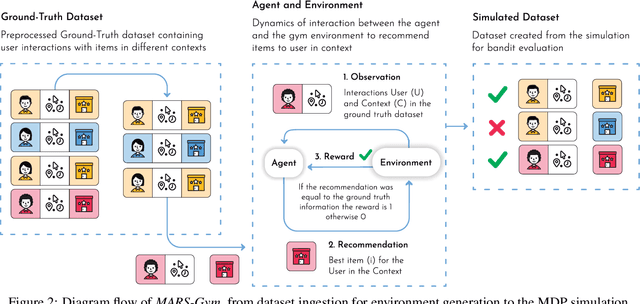
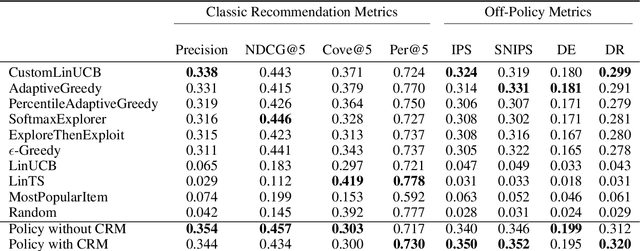
Recommender Systems are especially challenging for marketplaces since they must maximize user satisfaction while maintaining the healthiness and fairness of such ecosystems. In this context, we observed a lack of resources to design, train, and evaluate agents that learn by interacting within these environments. For this matter, we propose MARS-Gym, an open-source framework to empower researchers and engineers to quickly build and evaluate Reinforcement Learning agents for recommendations in marketplaces. MARS-Gym addresses the whole development pipeline: data processing, model design and optimization, and multi-sided evaluation. We also provide the implementation of a diverse set of baseline agents, with a metrics-driven analysis of them in the Trivago marketplace dataset, to illustrate how to conduct a holistic assessment using the available metrics of recommendation, off-policy estimation, and fairness. With MARS-Gym, we expect to bridge the gap between academic research and production systems, as well as to facilitate the design of new algorithms and applications.