 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Deployment Improves Planning Skills in LLMs
Dec 31, 2025We show that iterative deployment of large language models (LLMs), each fine-tuned on data carefully curated by users from the previous models' deployment, can significantly change the properties of the resultant models. By testing this mechanism on various planning domains, we observe substantial improvements in planning skills, with later models displaying emergent generalization by discovering much longer plans than the initial models. We then provide theoretical analysis showing that iterative deployment effectively implements reinforcement learning (RL) training in the outer-loop (i.e. not as part of intentional model training), with an implicit reward function. The connection to RL has two important implications: first, for the field of AI safety, as the reward function entailed by repeated deployment is not defined explicitly, and could have unexpected implications to the properties of future model deployments. Second, the mechanism highlighted here can be viewed as an alternative training regime to explicit RL, relying on data curation rather than explicit rewards.
Learning Without Critics? Revisiting GRPO in Classical Reinforcement Learning Environments
Nov 05, 2025Group Relative Policy Optimization (GRPO) has emerged as a scalable alternative to Proximal Policy Optimization (PPO) by eliminating the learned critic and instead estimating advantages through group-relative comparisons of trajectories. This simplification raises fundamental questions about the necessity of learned baselines in policy-gradient methods. We present the first systematic study of GRPO in classical single-task reinforcement learning environments, spanning discrete and continuous control tasks. Through controlled ablations isolating baselines, discounting, and group sampling, we reveal three key findings: (1) learned critics remain essential for long-horizon tasks: all critic-free baselines underperform PPO except in short-horizon environments like CartPole where episodic returns can be effective; (2) GRPO benefits from high discount factors (gamma = 0.99) except in HalfCheetah, where lack of early termination favors moderate discounting (gamma = 0.9); (3) smaller group sizes outperform larger ones, suggesting limitations in batch-based grouping strategies that mix unrelated episodes. These results reveal both the limitations of critic-free methods in classical control and the specific conditions where they remain viable alternatives to learned value functions.
Stabilizing Policy Gradients for Sample-Efficient Reinforcement Learning in LLM Reasoning
Oct 01, 2025Reinforcement Learning, particularly through policy gradient methods, has played a central role in enabling reasoning capabilities of Large Language Models. However, the optimization stability of policy gradients in this setting remains understudied. As a result, existing implementations often resort to conservative hyperparameter choices to ensure stability, which requires more training samples and increases computational costs. Hence, developing models for reliably tracking the underlying optimization dynamics and leveraging them into training enables more sample-efficient regimes and further unleashes scalable post-training. We address this gap by formalizing the stochastic optimization problem of policy gradients with explicit consideration of second-order geometry. We propose a tractable computational framework that tracks and leverages curvature information during policy updates. We further employ this framework to design interventions in the optimization process through data selection. The resultant algorithm, Curvature-Aware Policy Optimization (CAPO), identifies samples that contribute to unstable updates and masks them out. Theoretically, we establish monotonic improvement guarantees under realistic assumptions. On standard math reasoning benchmarks, we empirically show that CAPO ensures stable updates under aggressive learning regimes where baselines catastrophically fail. With minimal intervention (rejecting fewer than 8% of tokens), CAPO achieves up to 30x improvement in sample efficiency over standard GRPO for LLM reasoning.
InfoQuest: Evaluating Multi-Turn Dialogue Agents for Open-Ended Conversations with Hidden Context
Feb 17, 2025



While large language models excel at following explicit instructions, they often struggle with ambiguous or incomplete user requests, defaulting to verbose, generic responses rather than seeking clarification. We introduce InfoQuest, a multi-turn chat benchmark designed to evaluate how dialogue agents handle hidden context in open-ended user requests. The benchmark presents intentionally ambiguous scenarios that require models to engage in information-seeking dialogue through clarifying questions before providing appropriate responses. Our evaluation of both open and closed-source models reveals that while proprietary models generally perform better, all current assistants struggle with effectively gathering critical information, often requiring multiple turns to infer user intent and frequently defaulting to generic responses without proper clarification. We provide a systematic methodology for generating diverse scenarios and evaluating models' information-seeking capabilities, offering insights into the current limitations of language models in handling ambiguous requests through multi-turn interactions.
Sliding Puzzles Gym: A Scalable Benchmark for State Representation in Visual Reinforcement Learning
Oct 17, 2024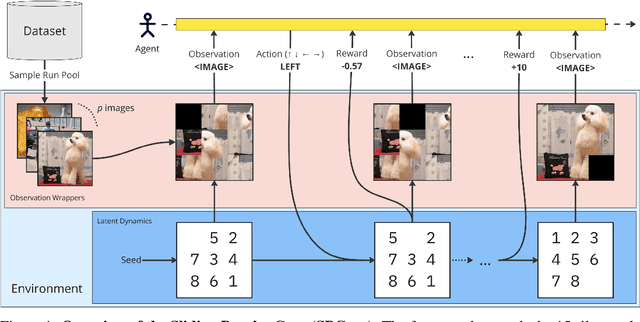


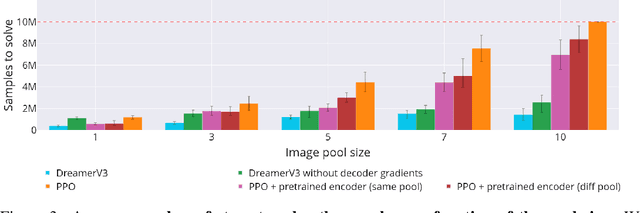
Learning effective visual representations is crucial in open-world environments where agents encounter diverse and unstructured observations. This ability enables agents to extract meaningful information from raw sensory inputs, like pixels, which is essential for generalization across different tasks. However, evaluating representation learning separately from policy learning remains a challenge in most reinforcement learning (RL) benchmarks. To address this, we introduce the Sliding Puzzles Gym (SPGym), a benchmark that extends the classic 15-tile puzzle with variable grid sizes and observation spaces, including large real-world image datasets. SPGym allows scaling the representation learning challenge while keeping the latent environment dynamics and algorithmic problem fixed, providing a targeted assessment of agents' ability to form compositional and generalizable state representations. Experiments with both model-free and model-based RL algorithms, with and without explicit representation learning components, show that as the representation challenge scales, SPGym effectively distinguishes agents based on their capabilities. Moreover, SPGym reaches difficulty levels where no tested algorithm consistently excels, highlighting key challenges and opportunities for advancing representation learning for decision-making research.
Temporal-Difference Variational Continual Learning
Oct 10, 2024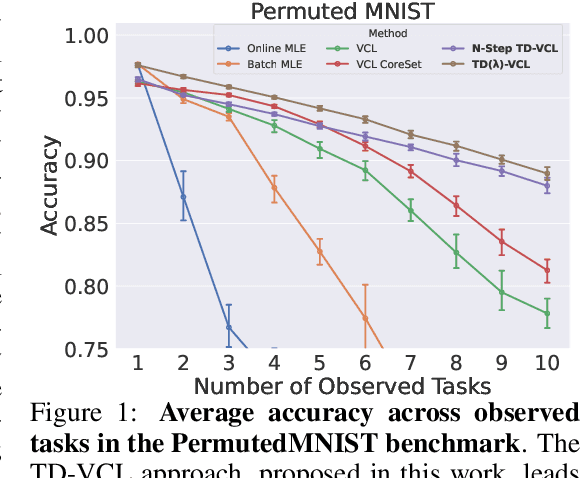
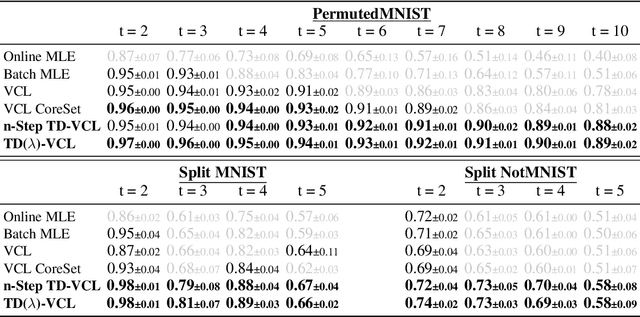
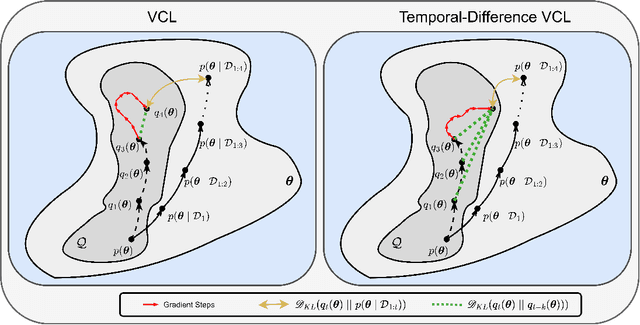

A crucial capability of Machine Learning models in real-world applications is the ability to continuously learn new tasks. This adaptability allows them to respond to potentially inevitable shifts in the data-generating distribution over time. However, in Continual Learning (CL) settings, models often struggle to balance learning new tasks (plasticity) with retaining previous knowledge (memory stability). Consequently, they are susceptible to Catastrophic Forgetting, which degrades performance and undermines the reliability of deployed systems. Variational Continual Learning methods tackle this challenge by employing a learning objective that recursively updates the posterior distribution and enforces it to stay close to the latest posterior estimate. Nonetheless, we argue that these methods may be ineffective due to compounding approximation errors over successive recursions. To mitigate this, we propose new learning objectives that integrate the regularization effects of multiple previous posterior estimations, preventing individual errors from dominating future posterior updates and compounding over time. We reveal insightful connections between these objectives and Temporal-Difference methods, a popular learning mechanism in Reinforcement Learning and Neuroscience. We evaluate the proposed objectives on challenging versions of popular CL benchmarks, demonstrating that they outperform standard Variational CL methods and non-variational baselines, effectively alleviating Catastrophic Forgetting.
Deep Bayesian Active Learning for Preference Modeling in Large Language Models
Jun 14, 2024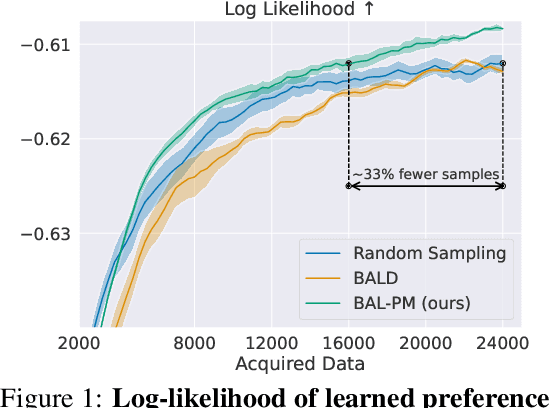


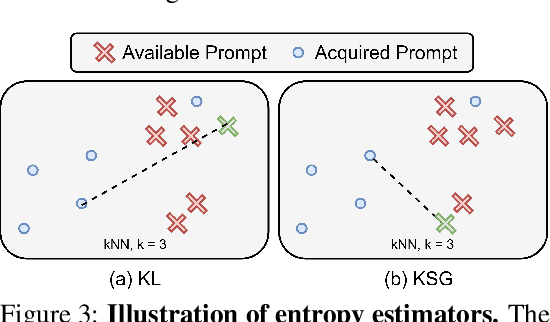
Leveraging human preferences for steering the behavior of Large Language Models (LLMs) has demonstrated notable success in recent years. Nonetheless, data selection and labeling are still a bottleneck for these systems, particularly at large scale. Hence, selecting the most informative points for acquiring human feedback may considerably reduce the cost of preference labeling and unleash the further development of LLMs. Bayesian Active Learning provides a principled framework for addressing this challenge and has demonstrated remarkable success in diverse settings. However, previous attempts to employ it for Preference Modeling did not meet such expectations. In this work, we identify that naive epistemic uncertainty estimation leads to the acquisition of redundant samples. We address this by proposing the Bayesian Active Learner for Preference Modeling (BAL-PM), a novel stochastic acquisition policy that not only targets points of high epistemic uncertainty according to the preference model but also seeks to maximize the entropy of the acquired prompt distribution in the feature space spanned by the employed LLM. Notably, our experiments demonstrate that BAL-PM requires 33% to 68% fewer preference labels in two popular human preference datasets and exceeds previous stochastic Bayesian acquisition policies.
Transformers are Meta-Reinforcement Learners
Jun 14, 2022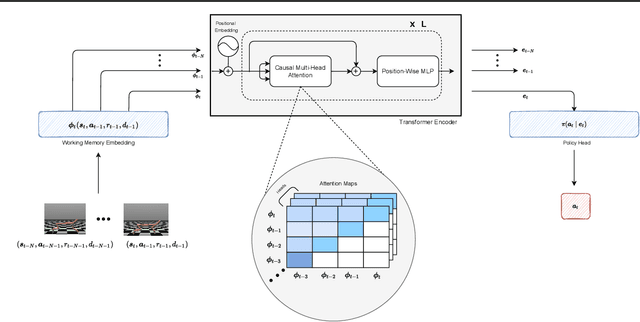
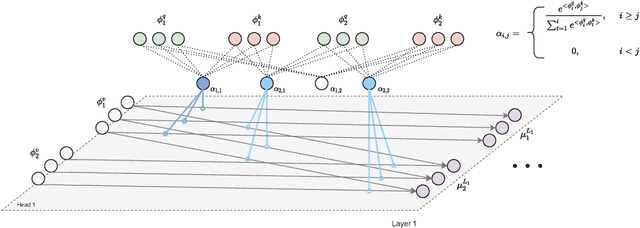
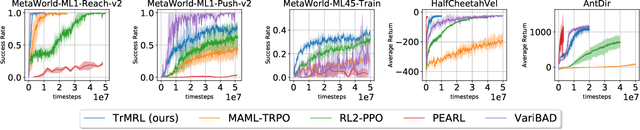
The transformer architecture and variants presented remarkable success across many machine learning tasks in recent years. This success is intrinsically related to the capability of handling long sequences and the presence of context-dependent weights from the attention mechanism. We argue that these capabilities suit the central role of a Meta-Reinforcement Learning algorithm. Indeed, a meta-RL agent needs to infer the task from a sequence of trajectories. Furthermore, it requires a fast adaptation strategy to adapt its policy for a new task -- which can be achieved using the self-attention mechanism. In this work, we present TrMRL (Transformers for Meta-Reinforcement Learning), a meta-RL agent that mimics the memory reinstatement mechanism using the transformer architecture. It associates the recent past of working memories to build an episodic memory recursively through the transformer layers. We show that the self-attention computes a consensus representation that minimizes the Bayes Risk at each layer and provides meaningful features to compute the best actions. We conducted experiments in high-dimensional continuous control environments for locomotion and dexterous manipulation. Results show that TrMRL presents comparable or superior asymptotic performance, sample efficiency, and out-of-distribution generalization compared to the baselines in these environments.
MARS-Gym: A Gym framework to model, train, and evaluate Recommender Systems for Marketplaces
Sep 30, 2020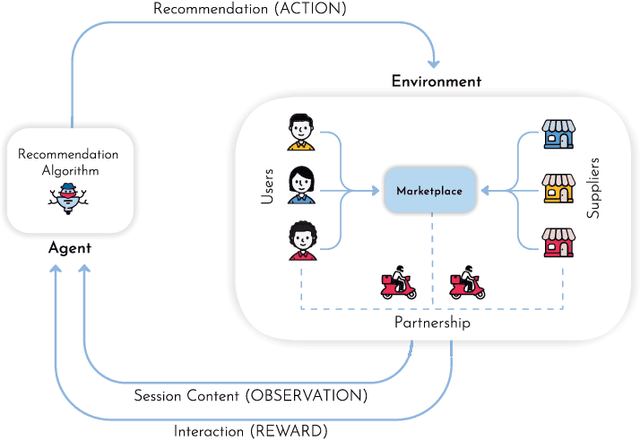
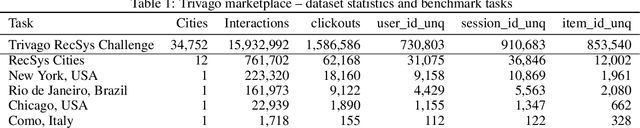
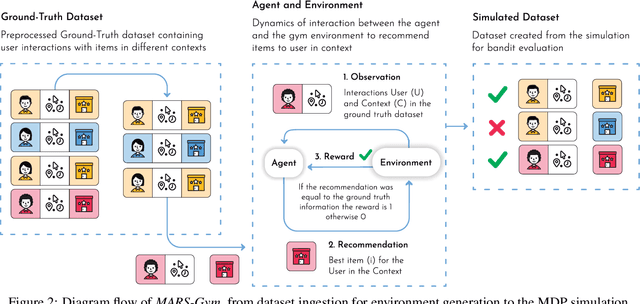
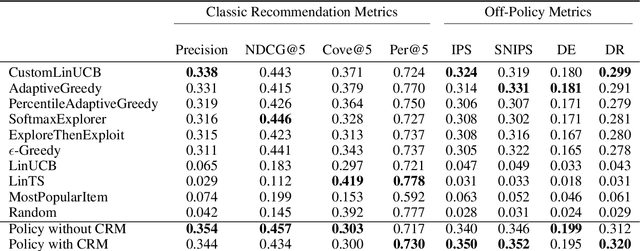
Recommender Systems are especially challenging for marketplaces since they must maximize user satisfaction while maintaining the healthiness and fairness of such ecosystems. In this context, we observed a lack of resources to design, train, and evaluate agents that learn by interacting within these environments. For this matter, we propose MARS-Gym, an open-source framework to empower researchers and engineers to quickly build and evaluate Reinforcement Learning agents for recommendations in marketplaces. MARS-Gym addresses the whole development pipeline: data processing, model design and optimization, and multi-sided evaluation. We also provide the implementation of a diverse set of baseline agents, with a metrics-driven analysis of them in the Trivago marketplace dataset, to illustrate how to conduct a holistic assessment using the available metrics of recommendation, off-policy estimation, and fairness. With MARS-Gym, we expect to bridge the gap between academic research and production systems, as well as to facilitate the design of new algorithms and applications.
Bottom-Up Meta-Policy Search
Oct 22, 2019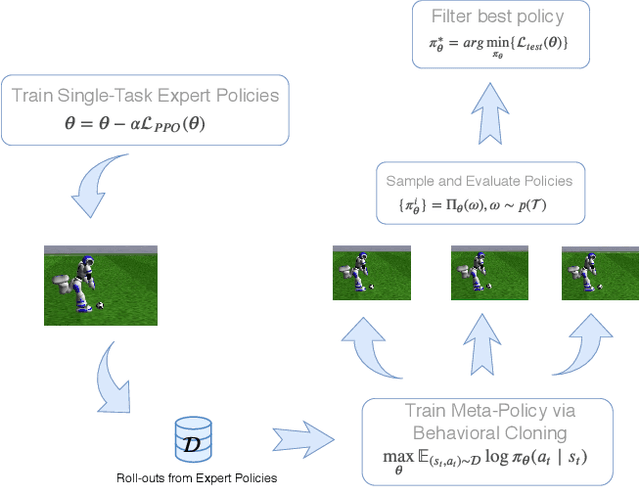
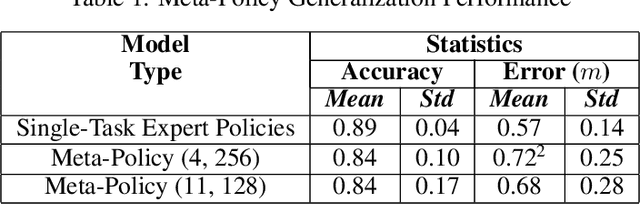
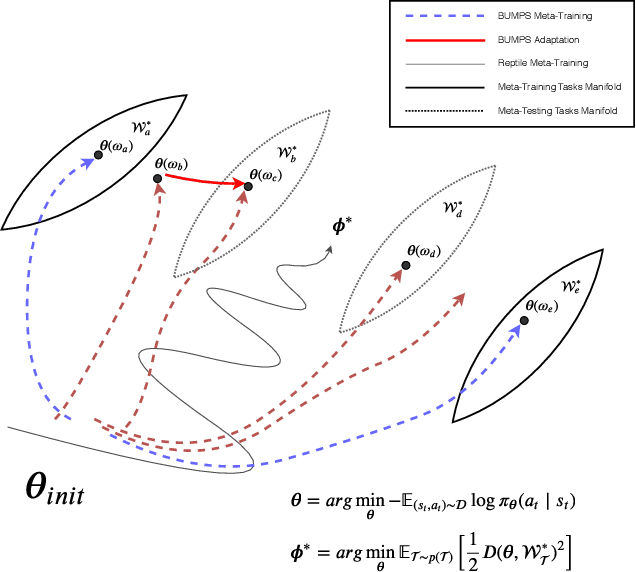
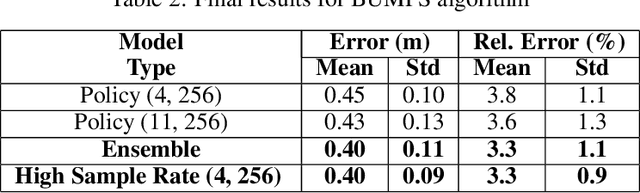
Despite of the recent progress in agents that learn through interaction, there are several challenges in terms of sample efficiency and generalization across unseen behaviors during training. To mitigate these problems, we propose and apply a first-order Meta-Learning algorithm called Bottom-Up Meta-Policy Search (BUMPS), which works with two-phase optimization procedure: firstly, in a meta-training phase, it distills few expert policies to create a meta-policy capable of generalizing knowledge to unseen tasks during training; secondly, it applies a fast adaptation strategy named Policy Filtering, which evaluates few policies sampled from the meta-policy distribution and selects which best solves the task. We conducted all experiments in the RoboCup 3D Soccer Simulation domain, in the context of kick motion learning. We show that, given our experimental setup, BUMPS works in scenarios where simple multi-task Reinforcement Learning does not. Finally, we performed experiments in a way to evaluate each component of the algorithm.