 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Consistency Loss for Monocular Visual Odometry with Attention-Based Deep Learning
Jan 19, 2024Deep learning algorithms have driven expressive progress in many complex tasks. The loss function is a core component of deep learning techniques, guiding the learning process of neural networks. This paper contributes by introducing a consistency loss for visual odometry with deep learning-based approaches. The motion consistency loss explores repeated motions that appear in consecutive overlapped video clips. Experimental results show that our approach increased the performance of a model on the KITTI odometry benchmark.
Real-Time Surface-to-Air Missile Engagement Zone Prediction Using Simulation and Machine Learning
Dec 05, 2023Surface-to-Air Missiles (SAMs) are crucial in modern air defense systems. A critical aspect of their effectiveness is the Engagement Zone (EZ), the spatial region within which a SAM can effectively engage and neutralize a target. Notably, the EZ is intrinsically related to the missile's maximum range; it defines the furthest distance at which a missile can intercept a target. The accurate computation of this EZ is essential but challenging due to the dynamic and complex factors involved, which often lead to high computational costs and extended processing times when using conventional simulation methods. In light of these challenges, our study investigates the potential of machine learning techniques, proposing an approach that integrates machine learning with a custom-designed simulation tool to train supervised algorithms. We leverage a comprehensive dataset of pre-computed SAM EZ simulations, enabling our model to accurately predict the SAM EZ for new input parameters. It accelerates SAM EZ simulations, enhances air defense strategic planning, and provides real-time insights, improving SAM system performance. The study also includes a comparative analysis of machine learning algorithms, illuminating their capabilities and performance metrics and suggesting areas for future research, highlighting the transformative potential of machine learning in SAM EZ simulations.
Transformer-based model for monocular visual odometry: a video understanding approach
May 10, 2023

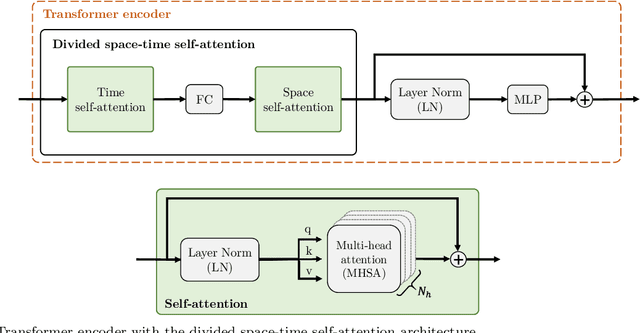

Estimating the camera pose given images of a single camera is a traditional task in mobile robots and autonomous vehicles. This problem is called monocular visual odometry and it often relies on geometric approaches that require engineering effort for a specific scenario. Deep learning methods have shown to be generalizable after proper training and a considerable amount of available data. Transformer-based architectures have dominated the state-of-the-art in natural language processing and computer vision tasks, such as image and video understanding. In this work, we deal with the monocular visual odometry as a video understanding task to estimate the 6-DoF camera's pose. We contribute by presenting the TSformer-VO model based on spatio-temporal self-attention mechanisms to extract features from clips and estimate the motions in an end-to-end manner. Our approach achieved competitive state-of-the-art performance compared with geometry-based and deep learning-based methods on the KITTI visual odometry dataset, outperforming the DeepVO implementation highly accepted in the visual odometry community.
Autonomous Agent for Beyond Visual Range Air Combat: A Deep Reinforcement Learning Approach
Apr 19, 2023
This work contributes to developing an agent based on deep reinforcement learning capable of acting in a beyond visual range (BVR) air combat simulation environment. The paper presents an overview of building an agent representing a high-performance fighter aircraft that can learn and improve its role in BVR combat over time based on rewards calculated using operational metrics. Also, through self-play experiments, it expects to generate new air combat tactics never seen before. Finally, we hope to examine a real pilot's ability, using virtual simulation, to interact in the same environment with the trained agent and compare their performances. This research will contribute to the air combat training context by developing agents that can interact with real pilots to improve their performances in air defense missions.
Dense Prediction Transformer for Scale Estimation in Monocular Visual Odometry
Oct 04, 2022

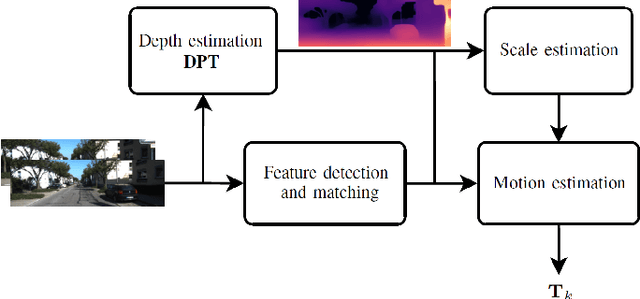
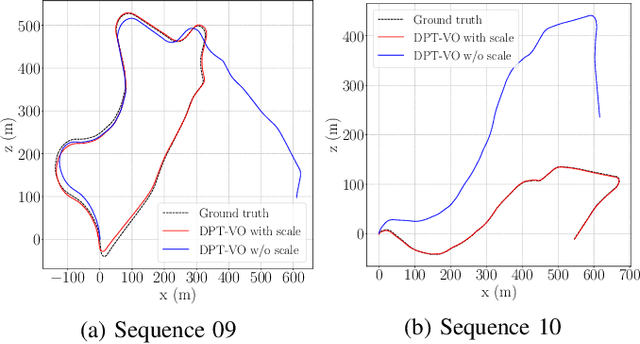
Monocular visual odometry consists of the estimation of the position of an agent through images of a single camera, and it is applied in autonomous vehicles, medical robots, and augmented reality. However, monocular systems suffer from the scale ambiguity problem due to the lack of depth information in 2D frames. This paper contributes by showing an application of the dense prediction transformer model for scale estimation in monocular visual odometry systems. Experimental results show that the scale drift problem of monocular systems can be reduced through the accurate estimation of the depth map by this model, achieving competitive state-of-the-art performance on a visual odometry benchmark.
Supervised Machine Learning for Effective Missile Launch Based on Beyond Visual Range Air Combat Simulations
Jul 09, 2022
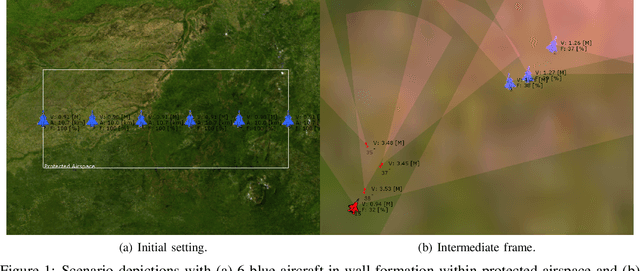

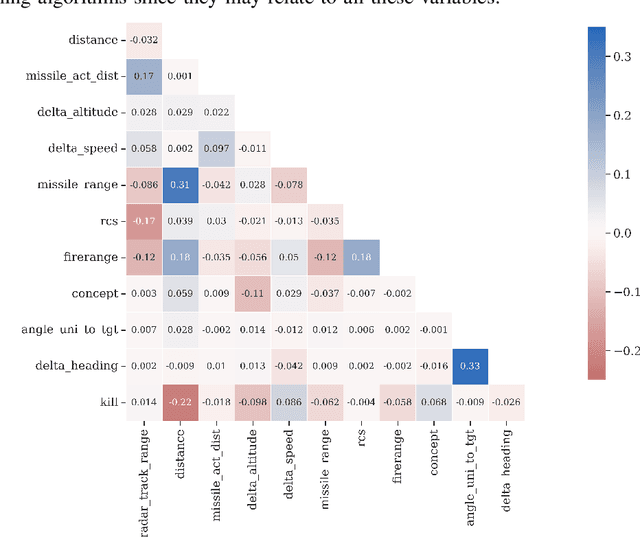
This work compares supervised machine learning methods using reliable data from constructive simulations to estimate the most effective moment for launching missiles during air combat. We employed resampling techniques to improve the predictive model, analyzing accuracy, precision, recall, and f1-score. Indeed, we could identify the remarkable performance of the models based on decision trees and the significant sensitivity of other algorithms to resampling techniques. The models with the best f1-score brought values of 0.379 and 0.465 without and with the resampling technique, respectively, which is an increase of 22.69%. Thus, if desirable, resampling techniques can improve the model's recall and f1-score with a slight decline in accuracy and precision. Therefore, through data obtained through constructive simulations, it is possible to develop decision support tools based on machine learning models, which may improve the flight quality in BVR air combat, increasing the effectiveness of offensive missions to hit a particular target.
A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems
Mar 05, 2022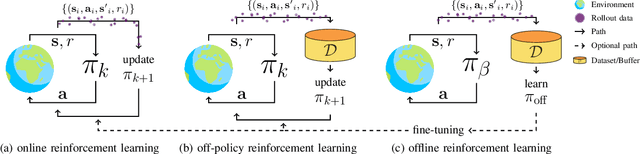
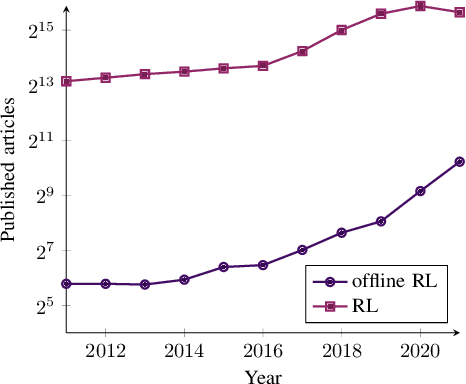
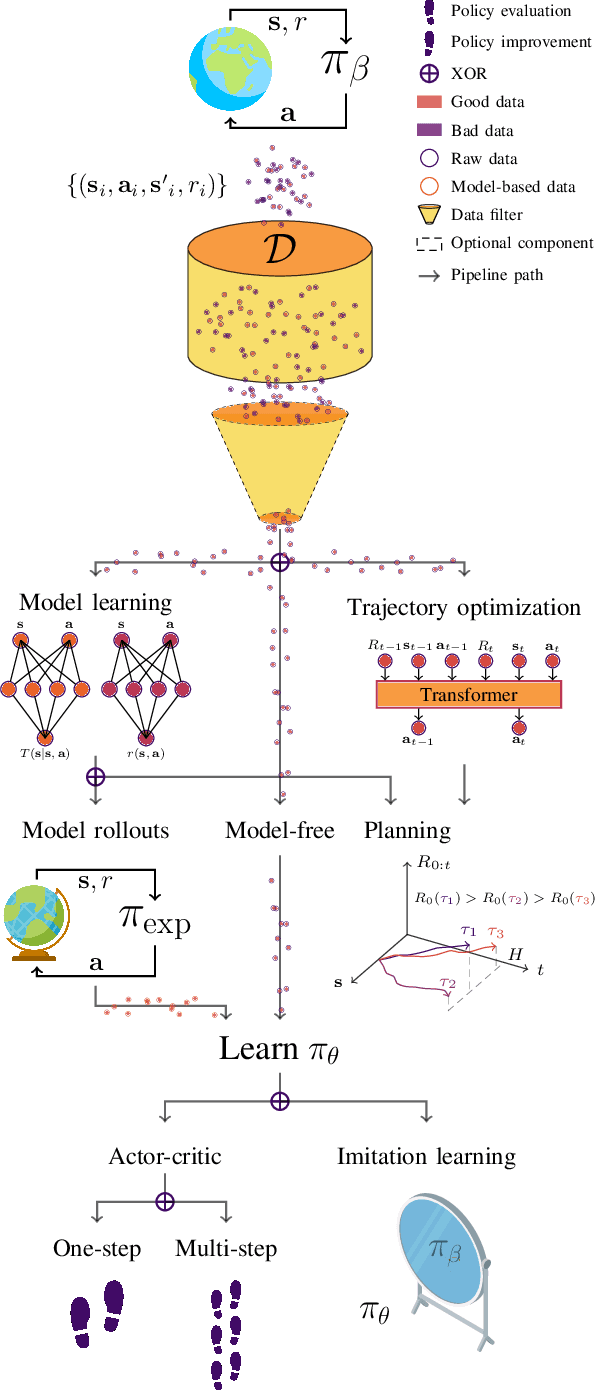
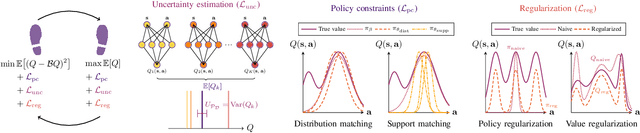
With the widespread adoption of deep learning, reinforcement learning (RL) has experienced a dramatic increase in popularity, scaling to previously intractable problems, such as playing complex games from pixel observations, sustaining conversations with humans, and controlling robotic agents. However, there is still a wide range of domains inaccessible to RL due to the high cost and danger of interacting with the environment. Offline RL is a paradigm that learns exclusively from static datasets of previously collected interactions, making it feasible to extract policies from large and diverse training datasets. Effective offline RL algorithms have a much wider range of applications than online RL, being particularly appealing for real-world applications such as education, healthcare, and robotics. In this work, we propose a unifying taxonomy to classify offline RL methods. Furthermore, we provide a comprehensive review of the latest algorithmic breakthroughs in the field, and a review of existing benchmarks' properties and shortcomings. Finally, we provide our perspective on open problems and propose future research directions for this rapidly growing field.
Weapon Engagement Zone Maximum Launch Range Estimation Using a Deep Neural Network
Nov 17, 2021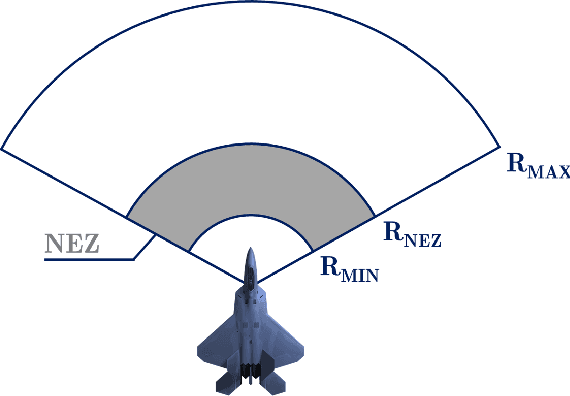
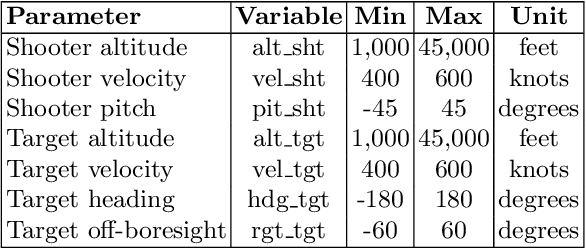
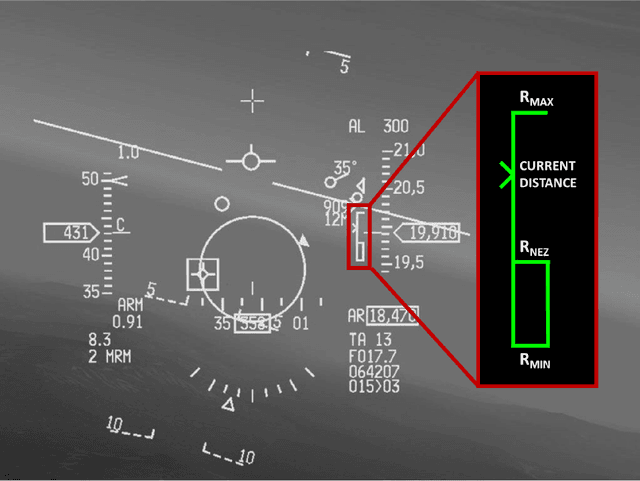
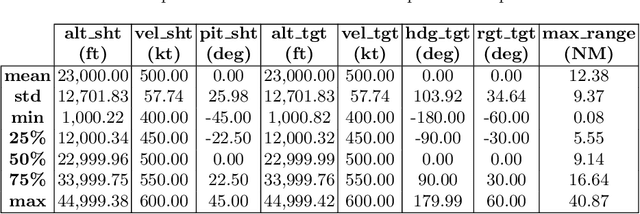
This work investigates the use of a Deep Neural Network (DNN) to perform an estimation of the Weapon Engagement Zone (WEZ) maximum launch range. The WEZ allows the pilot to identify an airspace in which the available missile has a more significant probability of successfully engaging a particular target, i.e., a hypothetical area surrounding an aircraft in which an adversary is vulnerable to a shot. We propose an approach to determine the WEZ of a given missile using 50,000 simulated launches in variate conditions. These simulations are used to train a DNN that can predict the WEZ when the aircraft finds itself on different firing conditions, with a coefficient of determination of 0.99. It provides another procedure concerning preceding research since it employs a non-discretized model, i.e., it considers all directions of the WEZ at once, which has not been done previously. Additionally, the proposed method uses an experimental design that allows for fewer simulation runs, providing faster model training.
Engagement Decision Support for Beyond Visual Range Air Combat
Nov 17, 2021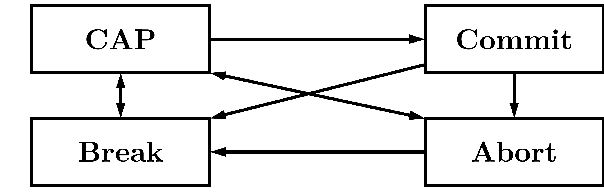
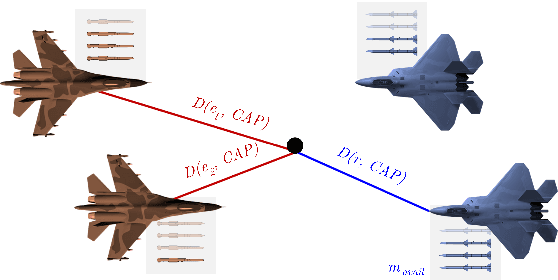
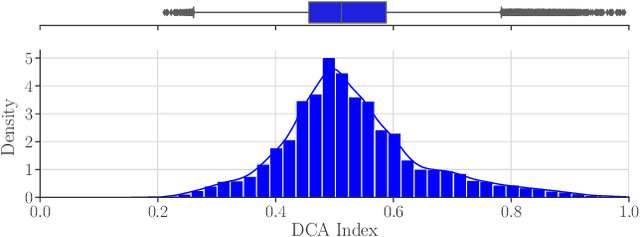
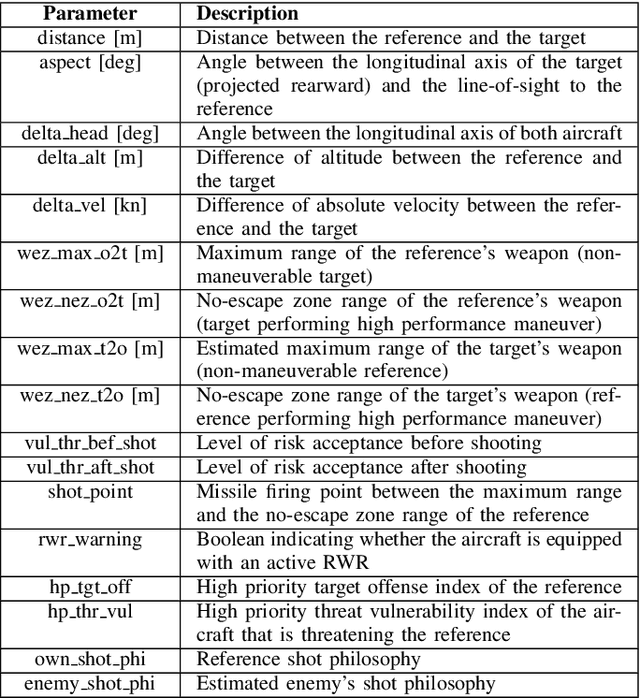
This work aims to provide an engagement decision support tool for Beyond Visual Range (BVR) air combat in the context of Defensive Counter Air (DCA) missions. In BVR air combat, engagement decision refers to the choice of the moment the pilot engages a target by assuming an offensive stance and executing corresponding maneuvers. To model this decision, we use the Brazilian Air Force's Aerospace Simulation Environment (Ambiente de Simula\c{c}\~ao Aeroespacial - ASA in Portuguese), which generated 3,729 constructive simulations lasting 12 minutes each and a total of 10,316 engagements. We analyzed all samples by an operational metric called the DCA index, which represents, based on the experience of subject matter experts, the degree of success in this type of mission. This metric considers the distances of the aircraft of the same team and the opposite team, the point of Combat Air Patrol, and the number of missiles used. By defining the engagement status right before it starts and the average of the DCA index throughout the engagement, we create a supervised learning model to determine the quality of a new engagement. An algorithm based on decision trees, working with the XGBoost library, provides a regression model to predict the DCA index with a coefficient of determination close to 0.8 and a Root Mean Square Error of 0.05 that can furnish parameters to the BVR pilot to decide whether or not to engage. Thus, using data obtained through simulations, this work contributes by building a decision support system based on machine learning for BVR air combat.
Bottom-Up Meta-Policy Search
Oct 22, 2019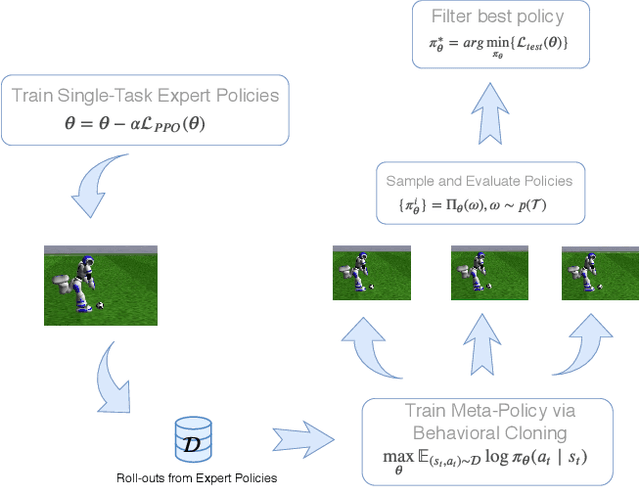
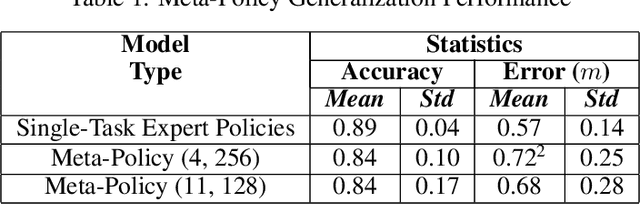
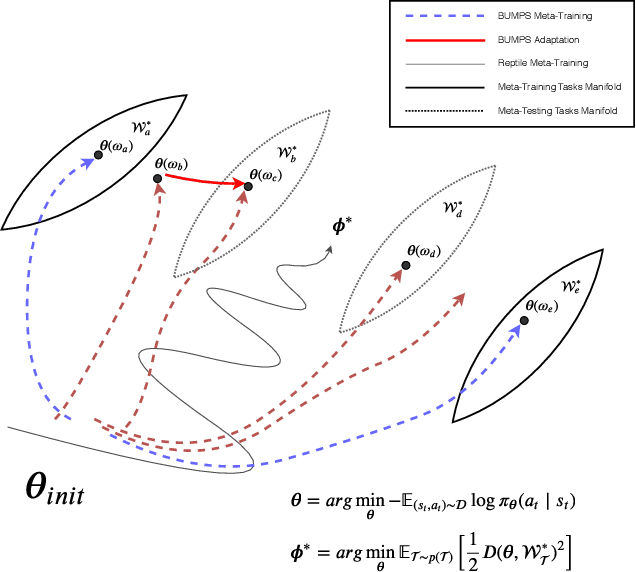
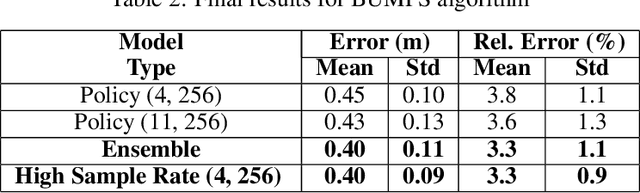
Despite of the recent progress in agents that learn through interaction, there are several challenges in terms of sample efficiency and generalization across unseen behaviors during training. To mitigate these problems, we propose and apply a first-order Meta-Learning algorithm called Bottom-Up Meta-Policy Search (BUMPS), which works with two-phase optimization procedure: firstly, in a meta-training phase, it distills few expert policies to create a meta-policy capable of generalizing knowledge to unseen tasks during training; secondly, it applies a fast adaptation strategy named Policy Filtering, which evaluates few policies sampled from the meta-policy distribution and selects which best solves the task. We conducted all experiments in the RoboCup 3D Soccer Simulation domain, in the context of kick motion learning. We show that, given our experimental setup, BUMPS works in scenarios where simple multi-task Reinforcement Learning does not. Finally, we performed experiments in a way to evaluate each component of the algorithm.