 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Strategies for Parkinson Tremor Classification Using Wearable Sensor Data
Jan 30, 2025



Parkinson's disease (PD) is a neurological disorder requiring early and accurate diagnosis for effective management. Machine learning (ML) has emerged as a powerful tool to enhance PD classification and diagnostic accuracy, particularly by leveraging wearable sensor data. This survey comprehensively reviews current ML methodologies used in classifying Parkinsonian tremors, evaluating various tremor data acquisition methodologies, signal preprocessing techniques, and feature selection methods across time and frequency domains, highlighting practical approaches for tremor classification. The survey explores ML models utilized in existing studies, ranging from traditional methods such as Support Vector Machines (SVM) and Random Forests to advanced deep learning architectures like Convolutional Neural Networks (CNN) and Long Short-Term Memory networks (LSTM). We assess the efficacy of these models in classifying tremor patterns associated with PD, considering their strengths and limitations. Furthermore, we discuss challenges and discrepancies in current research and broader challenges in applying ML to PD diagnosis using wearable sensor data. We also outline future research directions to advance ML applications in PD diagnostics, providing insights for researchers and practitioners.
Gender Bias Detection in Court Decisions: A Brazilian Case Study
Jun 01, 2024


Data derived from the realm of the social sciences is often produced in digital text form, which motivates its use as a source for natural language processing methods. Researchers and practitioners have developed and relied on artificial intelligence techniques to collect, process, and analyze documents in the legal field, especially for tasks such as text summarization and classification. While increasing procedural efficiency is often the primary motivation behind natural language processing in the field, several works have proposed solutions for human rights-related issues, such as assessment of public policy and institutional social settings. One such issue is the presence of gender biases in court decisions, which has been largely studied in social sciences fields; biased institutional responses to gender-based violence are a violation of international human rights dispositions since they prevent gender minorities from accessing rights and hamper their dignity. Natural language processing-based approaches can help detect these biases on a larger scale. Still, the development and use of such tools require researchers and practitioners to be mindful of legal and ethical aspects concerning data sharing and use, reproducibility, domain expertise, and value-charged choices. In this work, we (a) present an experimental framework developed to automatically detect gender biases in court decisions issued in Brazilian Portuguese and (b) describe and elaborate on features we identify to be critical in such a technology, given its proposed use as a support tool for research and assessment of court~activity.
Incremental procedural and sensorimotor learning in cognitive humanoid robots
Apr 30, 2023



The ability to automatically learn movements and behaviors of increasing complexity is a long-term goal in autonomous systems. Indeed, this is a very complex problem that involves understanding how knowledge is acquired and reused by humans as well as proposing mechanisms that allow artificial agents to reuse previous knowledge. Inspired by Jean Piaget's theory's first three sensorimotor substages, this work presents a cognitive agent based on CONAIM (Conscious Attention-Based Integrated Model) that can learn procedures incrementally. Throughout the paper, we show the cognitive functions required in each substage and how adding new functions helps address tasks previously unsolved by the agent. Experiments were conducted with a humanoid robot in a simulated environment modeled with the Cognitive Systems Toolkit (CST) performing an object tracking task. The system is modeled using a single procedural learning mechanism based on Reinforcement Learning. The increasing agent's cognitive complexity is managed by adding new terms to the reward function for each learning phase. Results show that this approach is capable of solving complex tasks incrementally.
A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems
Mar 05, 2022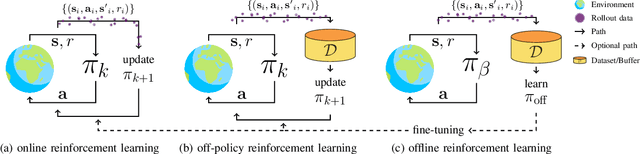
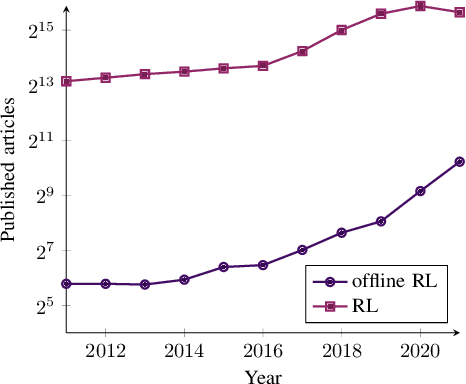
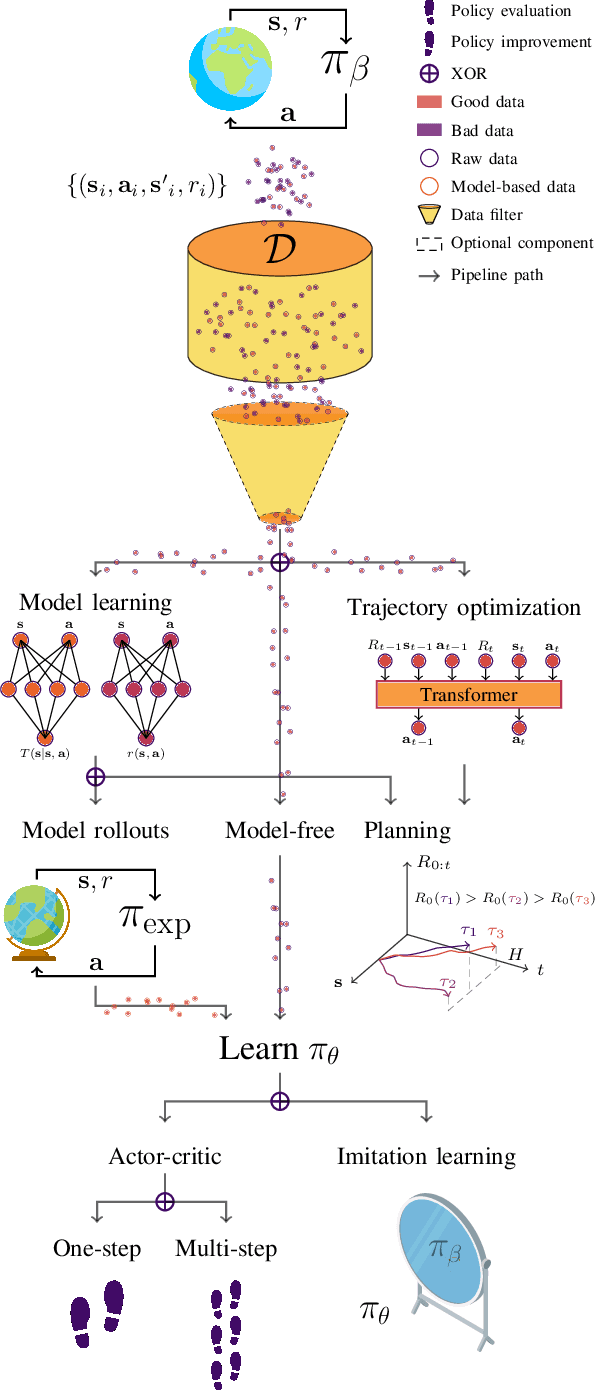
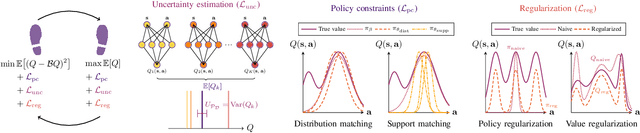
With the widespread adoption of deep learning, reinforcement learning (RL) has experienced a dramatic increase in popularity, scaling to previously intractable problems, such as playing complex games from pixel observations, sustaining conversations with humans, and controlling robotic agents. However, there is still a wide range of domains inaccessible to RL due to the high cost and danger of interacting with the environment. Offline RL is a paradigm that learns exclusively from static datasets of previously collected interactions, making it feasible to extract policies from large and diverse training datasets. Effective offline RL algorithms have a much wider range of applications than online RL, being particularly appealing for real-world applications such as education, healthcare, and robotics. In this work, we propose a unifying taxonomy to classify offline RL methods. Furthermore, we provide a comprehensive review of the latest algorithmic breakthroughs in the field, and a review of existing benchmarks' properties and shortcomings. Finally, we provide our perspective on open problems and propose future research directions for this rapidly growing field.
CIDEr-R: Robust Consensus-based Image Description Evaluation
Sep 28, 2021
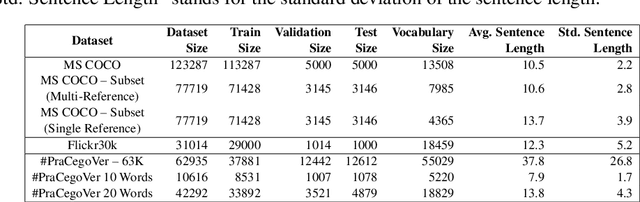

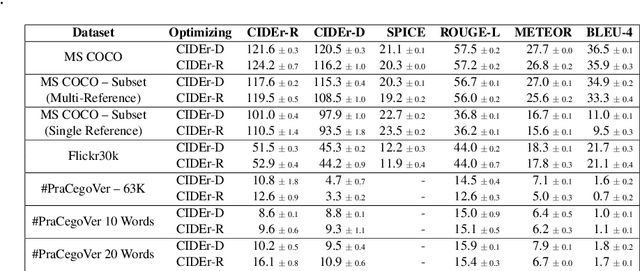
This paper shows that CIDEr-D, a traditional evaluation metric for image description, does not work properly on datasets where the number of words in the sentence is significantly greater than those in the MS COCO Captions dataset. We also show that CIDEr-D has performance hampered by the lack of multiple reference sentences and high variance of sentence length. To bypass this problem, we introduce CIDEr-R, which improves CIDEr-D, making it more flexible in dealing with datasets with high sentence length variance. We demonstrate that CIDEr-R is more accurate and closer to human judgment than CIDEr-D; CIDEr-R is more robust regarding the number of available references. Our results reveal that using Self-Critical Sequence Training to optimize CIDEr-R generates descriptive captions. In contrast, when CIDEr-D is optimized, the generated captions' length tends to be similar to the reference length. However, the models also repeat several times the same word to increase the sentence length.
Attention, please! A survey of Neural Attention Models in Deep Learning
Mar 31, 2021
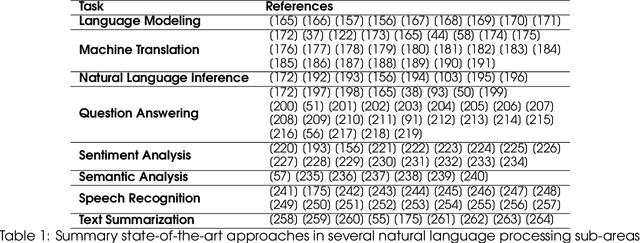
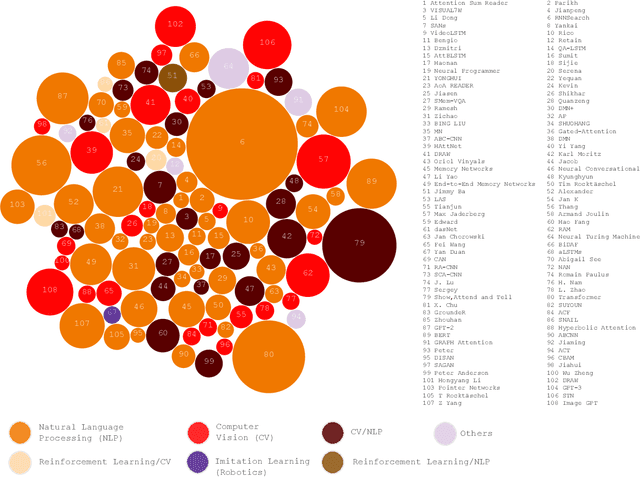
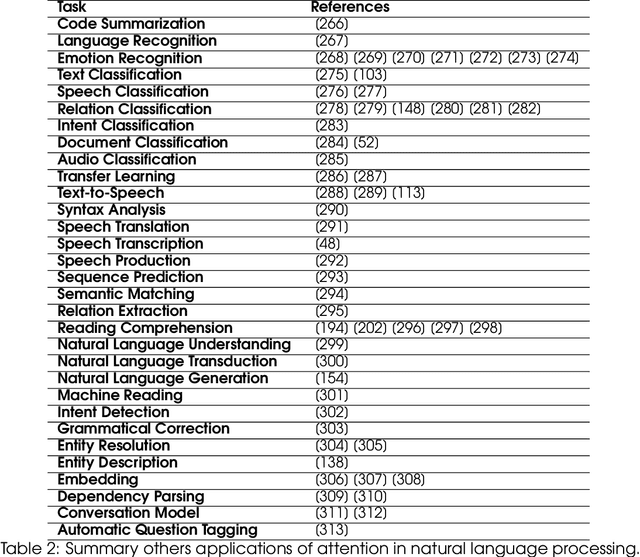
In humans, Attention is a core property of all perceptual and cognitive operations. Given our limited ability to process competing sources, attention mechanisms select, modulate, and focus on the information most relevant to behavior. For decades, concepts and functions of attention have been studied in philosophy, psychology, neuroscience, and computing. For the last six years, this property has been widely explored in deep neural networks. Currently, the state-of-the-art in Deep Learning is represented by neural attention models in several application domains. This survey provides a comprehensive overview and analysis of developments in neural attention models. We systematically reviewed hundreds of architectures in the area, identifying and discussing those in which attention has shown a significant impact. We also developed and made public an automated methodology to facilitate the development of reviews in the area. By critically analyzing 650 works, we describe the primary uses of attention in convolutional, recurrent networks and generative models, identifying common subgroups of uses and applications. Furthermore, we describe the impact of attention in different application domains and their impact on neural networks' interpretability. Finally, we list possible trends and opportunities for further research, hoping that this review will provide a succinct overview of the main attentional models in the area and guide researchers in developing future approaches that will drive further improvements.
#PraCegoVer: A Large Dataset for Image Captioning in Portuguese
Mar 21, 2021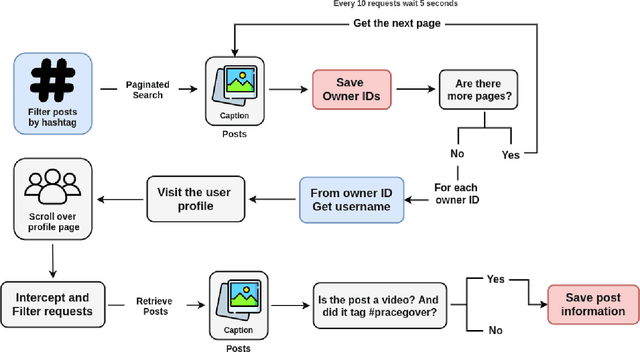


Automatically describing images using natural sentences is an important task to support visually impaired people's inclusion onto the Internet. It is still a big challenge that requires understanding the relation of the objects present in the image and their attributes and actions they are involved in. Then, visual interpretation methods are needed, but linguistic models are also necessary to verbally describe the semantic relations. This problem is known as Image Captioning. Although many datasets were proposed in the literature, the majority contains only English captions, whereas datasets with captions described in other languages are scarce. Recently, a movement called PraCegoVer arose on the Internet, stimulating users from social media to publish images, tag #PraCegoVer and add a short description of their content. Thus, inspired by this movement, we have proposed the #PraCegoVer, a multi-modal dataset with Portuguese captions based on posts from Instagram. It is the first large dataset for image captioning in Portuguese with freely annotated images. Further, the captions in our dataset bring additional challenges to the problem: first, in contrast to popular datasets such as MS COCO Captions, #PraCegoVer has only one reference to each image; also, both mean and variance of our reference sentence length are significantly greater than those in the MS COCO Captions. These two characteristics contribute to making our dataset interesting due to the linguistic aspect and the challenges that it introduces to the image captioning problem. We publicly-share the dataset at https://github.com/gabrielsantosrv/PraCegoVer.
Using Soft Actor-Critic for Low-Level UAV Control
Oct 05, 2020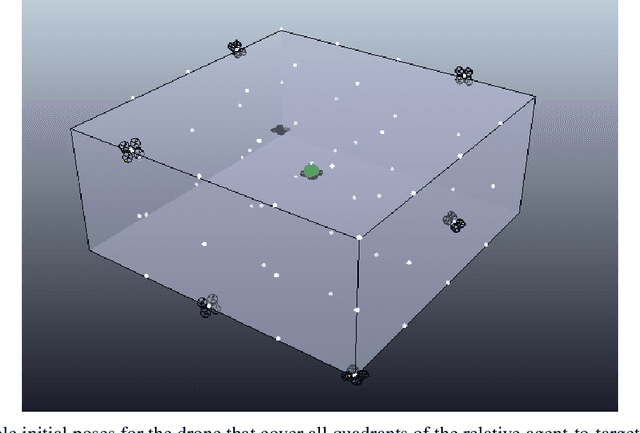
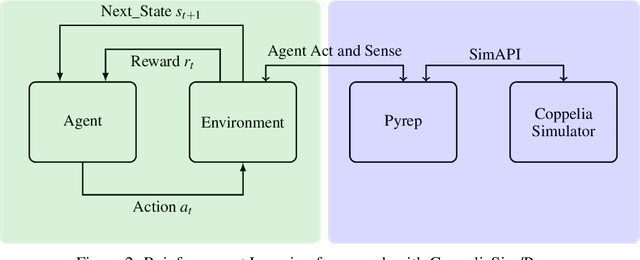
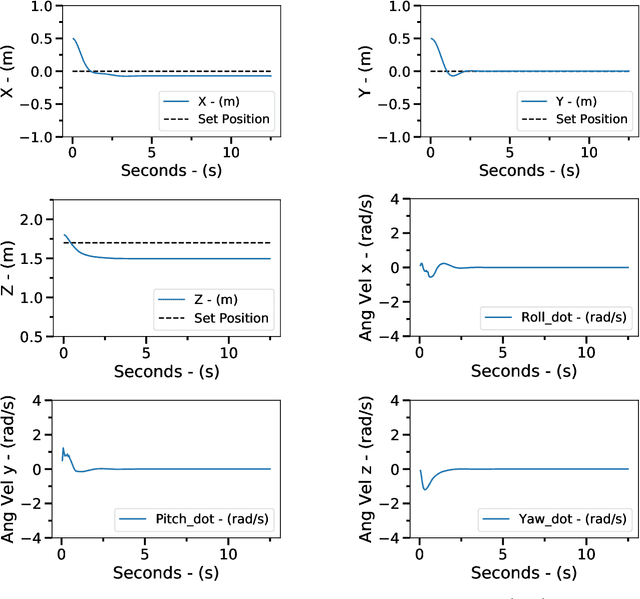
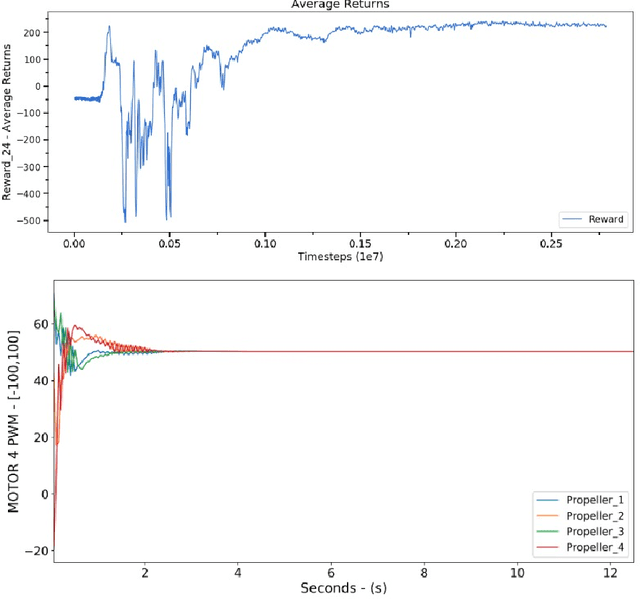
Unmanned Aerial Vehicles (UAVs), or drones, have recently been used in several civil application domains from organ delivery to remote locations to wireless network coverage. These platforms, however, are naturally unstable systems for which many different control approaches have been proposed. Generally based on classic and modern control, these algorithms require knowledge of the robot's dynamics. However, recently, model-free reinforcement learning has been successfully used for controlling drones without any prior knowledge of the robot model. In this work, we present a framework to train the Soft Actor-Critic (SAC) algorithm to low-level control of a quadrotor in a go-to-target task. All experiments were conducted under simulation. With the experiments, we show that SAC can not only learn a robust policy, but it can also cope with unseen scenarios. Videos from the simulations are available in https://www.youtube.com/watch?v=9z8vGs0Ri5g and the code in https://github.com/larocs/SAC_uav.