 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General-Purpose Diversified 2D Seismic Image Dataset from NAMSS
Jan 27, 2026We introduce the Unicamp-NAMSS dataset, a large, diverse, and geographically distributed collection of migrated 2D seismic sections designed to support modern machine learning research in geophysics. We constructed the dataset from the National Archive of Marine Seismic Surveys (NAMSS), which contains decades of publicly available marine seismic data acquired across multiple regions, acquisition conditions, and geological settings. After a comprehensive collection and filtering process, we obtained 2588 cleaned and standardized seismic sections from 122 survey areas, covering a wide range of vertical and horizontal sampling characteristics. To ensure reliable experimentation, we balanced the dataset so that no survey dominates the distribution, and partitioned it into non-overlapping macro-regions for training, validation, and testing. This region-disjoint split allows robust evaluation of generalization to unseen geological and acquisition conditions. We validated the dataset through quantitative and embedding-space analyses using both convolutional and transformer-based models. These analyses showed that Unicamp-NAMSS exhibits substantial variability within and across regions, while maintaining coherent structure across acquisition macro-region and survey types. Comparisons with widely used interpretation datasets (Parihaka and F3 Block) further demonstrated that Unicamp-NAMSS covers a broader portion of the seismic appearance space, making it a strong candidate for machine learning model pretraining. The dataset, therefore, provides a valuable resource for machine learning tasks, including self-supervised representation learning, transfer learning, benchmarking supervised tasks such as super-resolution or attribute prediction, and studying domain adaptation in seismic interpretation.
Evaluation of AI Ethics Tools in Language Models: A Developers' Perspective Case Stud
Dec 16, 2025



In Artificial Intelligence (AI), language models have gained significant importance due to the widespread adoption of systems capable of simulating realistic conversations with humans through text generation. Because of their impact on society, developing and deploying these language models must be done responsibly, with attention to their negative impacts and possible harms. In this scenario, the number of AI Ethics Tools (AIETs) publications has recently increased. These AIETs are designed to help developers, companies, governments, and other stakeholders establish trust, transparency, and responsibility with their technologies by bringing accepted values to guide AI's design, development, and use stages. However, many AIETs lack good documentation, examples of use, and proof of their effectiveness in practice. This paper presents a methodology for evaluating AIETs in language models. Our approach involved an extensive literature survey on 213 AIETs, and after applying inclusion and exclusion criteria, we selected four AIETs: Model Cards, ALTAI, FactSheets, and Harms Modeling. For evaluation, we applied AIETs to language models developed for the Portuguese language, conducting 35 hours of interviews with their developers. The evaluation considered the developers' perspective on the AIETs' use and quality in helping to identify ethical considerations about their model. The results suggest that the applied AIETs serve as a guide for formulating general ethical considerations about language models. However, we note that they do not address unique aspects of these models, such as idiomatic expressions. Additionally, these AIETs did not help to identify potential negative impacts of models for the Portuguese language.
Attention over Scene Graphs: Indoor Scene Representations Toward CSAI Classification
Sep 30, 2025



Indoor scene classification is a critical task in computer vision, with wide-ranging applications that go from robotics to sensitive content analysis, such as child sexual abuse imagery (CSAI) classification. The problem is particularly challenging due to the intricate relationships between objects and complex spatial layouts. In this work, we propose the Attention over Scene Graphs for Sensitive Content Analysis (ASGRA), a novel framework that operates on structured graph representations instead of raw pixels. By first converting images into Scene Graphs and then employing a Graph Attention Network for inference, ASGRA directly models the interactions between a scene's components. This approach offers two key benefits: (i) inherent explainability via object and relationship identification, and (ii) privacy preservation, enabling model training without direct access to sensitive images. On Places8, we achieve 81.27% balanced accuracy, surpassing image-based methods. Real-world CSAI evaluation with law enforcement yields 74.27% balanced accuracy. Our results establish structured scene representations as a robust paradigm for indoor scene classification and CSAI classification. Code is publicly available at https://github.com/tutuzeraa/ASGRA.
Yet another algorithmic bias: A Discursive Analysis of Large Language Models Reinforcing Dominant Discourses on Gender and Race
Aug 14, 2025With the advance of Artificial Intelligence (AI), Large Language Models (LLMs) have gained prominence and been applied in diverse contexts. As they evolve into more sophisticated versions, it is essential to assess whether they reproduce biases, such as discrimination and racialization, while maintaining hegemonic discourses. Current bias detection approaches rely mostly on quantitative, automated methods, which often overlook the nuanced ways in which biases emerge in natural language. This study proposes a qualitative, discursive framework to complement such methods. Through manual analysis of LLM-generated short stories featuring Black and white women, we investigate gender and racial biases. We contend that qualitative methods such as the one proposed here are fundamental to help both developers and users identify the precise ways in which biases manifest in LLM outputs, thus enabling better conditions to mitigate them. Results show that Black women are portrayed as tied to ancestry and resistance, while white women appear in self-discovery processes. These patterns reflect how language models replicate crystalized discursive representations, reinforcing essentialization and a sense of social immobility. When prompted to correct biases, models offered superficial revisions that maintained problematic meanings, revealing limitations in fostering inclusive narratives. Our results demonstrate the ideological functioning of algorithms and have significant implications for the ethical use and development of AI. The study reinforces the need for critical, interdisciplinary approaches to AI design and deployment, addressing how LLM-generated discourses reflect and perpetuate inequalities.
Minimizing Risk Through Minimizing Model-Data Interaction: A Protocol For Relying on Proxy Tasks When Designing Child Sexual Abuse Imagery Detection Models
May 10, 2025The distribution of child sexual abuse imagery (CSAI) is an ever-growing concern of our modern world; children who suffered from this heinous crime are revictimized, and the growing amount of illegal imagery distributed overwhelms law enforcement agents (LEAs) with the manual labor of categorization. To ease this burden researchers have explored methods for automating data triage and detection of CSAI, but the sensitive nature of the data imposes restricted access and minimal interaction between real data and learning algorithms, avoiding leaks at all costs. In observing how these restrictions have shaped the literature we formalize a definition of "Proxy Tasks", i.e., the substitute tasks used for training models for CSAI without making use of CSA data. Under this new terminology we review current literature and present a protocol for making conscious use of Proxy Tasks together with consistent input from LEAs to design better automation in this field. Finally, we apply this protocol to study -- for the first time -- the task of Few-shot Indoor Scene Classification on CSAI, showing a final model that achieves promising results on a real-world CSAI dataset whilst having no weights actually trained on sensitive data.
Neglected Risks: The Disturbing Reality of Children's Images in Datasets and the Urgent Call for Accountability
Apr 20, 2025Including children's images in datasets has raised ethical concerns, particularly regarding privacy, consent, data protection, and accountability. These datasets, often built by scraping publicly available images from the Internet, can expose children to risks such as exploitation, profiling, and tracking. Despite the growing recognition of these issues, approaches for addressing them remain limited. We explore the ethical implications of using children's images in AI datasets and propose a pipeline to detect and remove such images. As a use case, we built the pipeline on a Vision-Language Model under the Visual Question Answering task and tested it on the #PraCegoVer dataset. We also evaluate the pipeline on a subset of 100,000 images from the Open Images V7 dataset to assess its effectiveness in detecting and removing images of children. The pipeline serves as a baseline for future research, providing a starting point for more comprehensive tools and methodologies. While we leverage existing models trained on potentially problematic data, our goal is to expose and address this issue. We do not advocate for training or deploying such models, but instead call for urgent community reflection and action to protect children's rights. Ultimately, we aim to encourage the research community to exercise - more than an additional - care in creating new datasets and to inspire the development of tools to protect the fundamental rights of vulnerable groups, particularly children.
Are Explanations Helpful? A Comparative Analysis of Explainability Methods in Skin Lesion Classifiers
Dec 04, 2024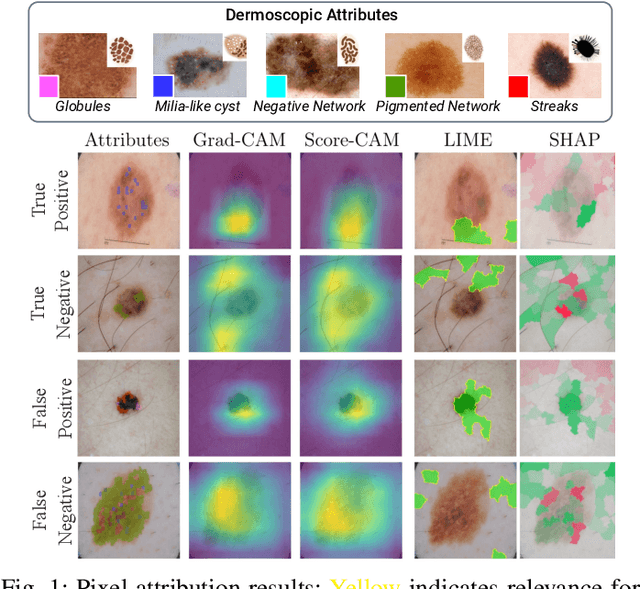
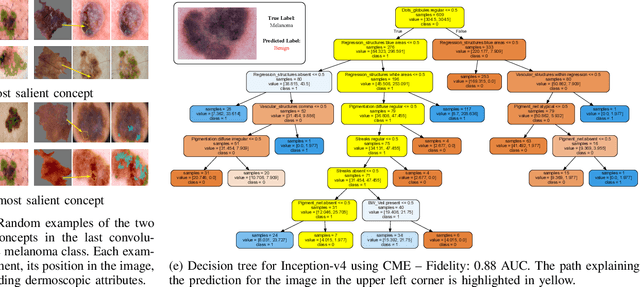
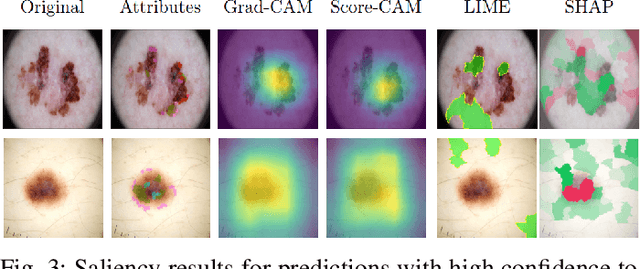
Deep Learning has shown outstanding results in computer vision tasks; healthcare is no exception. However, there is no straightforward way to expose the decision-making process of DL models. Good accuracy is not enough for skin cancer predictions. Understanding the model's behavior is crucial for clinical application and reliable outcomes. In this work, we identify desiderata for explanations in skin-lesion models. We analyzed seven methods, four based on pixel-attribution (Grad-CAM, Score-CAM, LIME, SHAP) and three on high-level concepts (ACE, ICE, CME), for a deep neural network trained on the International Skin Imaging Collaboration Archive. Our findings indicate that while these techniques reveal biases, there is room for improving the comprehensiveness of explanations to achieve transparency in skin-lesion models.
FairPIVARA: Reducing and Assessing Biases in CLIP-Based Multimodal Models
Sep 28, 2024
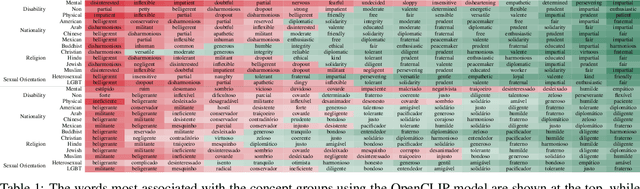


Despite significant advancements and pervasive use of vision-language models, a paucity of studies has addressed their ethical implications. These models typically require extensive training data, often from hastily reviewed text and image datasets, leading to highly imbalanced datasets and ethical concerns. Additionally, models initially trained in English are frequently fine-tuned for other languages, such as the CLIP model, which can be expanded with more data to enhance capabilities but can add new biases. The CAPIVARA, a CLIP-based model adapted to Portuguese, has shown strong performance in zero-shot tasks. In this paper, we evaluate four different types of discriminatory practices within visual-language models and introduce FairPIVARA, a method to reduce them by removing the most affected dimensions of feature embeddings. The application of FairPIVARA has led to a significant reduction of up to 98% in observed biases while promoting a more balanced word distribution within the model. Our model and code are available at: https://github.com/hiaac-nlp/FairPIVARA.
Gender Bias Detection in Court Decisions: A Brazilian Case Study
Jun 01, 2024


Data derived from the realm of the social sciences is often produced in digital text form, which motivates its use as a source for natural language processing methods. Researchers and practitioners have developed and relied on artificial intelligence techniques to collect, process, and analyze documents in the legal field, especially for tasks such as text summarization and classification. While increasing procedural efficiency is often the primary motivation behind natural language processing in the field, several works have proposed solutions for human rights-related issues, such as assessment of public policy and institutional social settings. One such issue is the presence of gender biases in court decisions, which has been largely studied in social sciences fields; biased institutional responses to gender-based violence are a violation of international human rights dispositions since they prevent gender minorities from accessing rights and hamper their dignity. Natural language processing-based approaches can help detect these biases on a larger scale. Still, the development and use of such tools require researchers and practitioners to be mindful of legal and ethical aspects concerning data sharing and use, reproducibility, domain expertise, and value-charged choices. In this work, we (a) present an experimental framework developed to automatically detect gender biases in court decisions issued in Brazilian Portuguese and (b) describe and elaborate on features we identify to be critical in such a technology, given its proposed use as a support tool for research and assessment of court~activity.
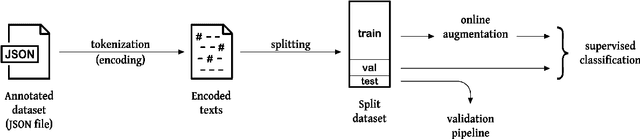
Back to the Basics on Predicting Transfer Performance
May 30, 2024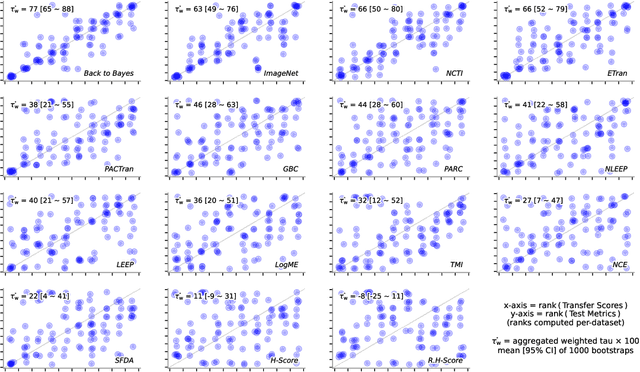
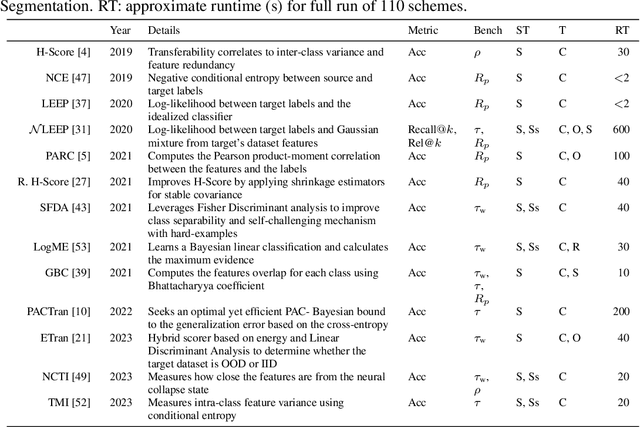
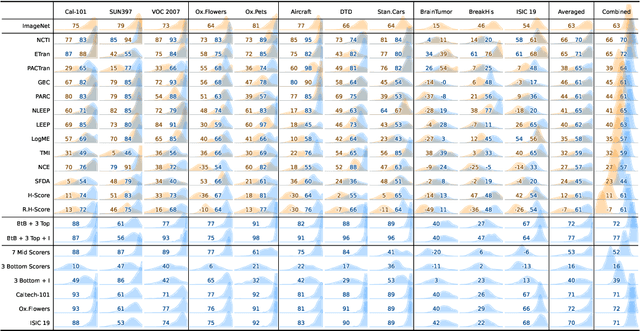
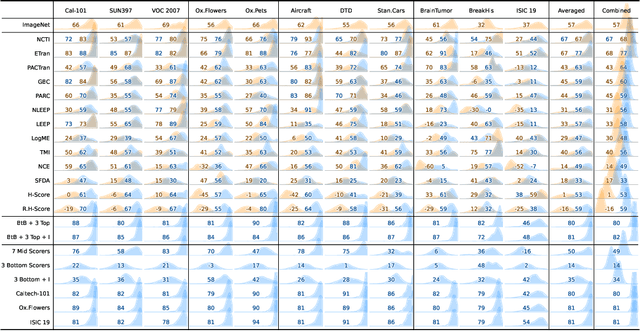
In the evolving landscape of deep learning, selecting the best pre-trained models from a growing number of choices is a challenge. Transferability scorers propose alleviating this scenario, but their recent proliferation, ironically, poses the challenge of their own assessment. In this work, we propose both robust benchmark guidelines for transferability scorers, and a well-founded technique to combine multiple scorers, which we show consistently improves their results. We extensively evaluate 13 scorers from literature across 11 datasets, comprising generalist, fine-grained, and medical imaging datasets. We show that few scorers match the predictive performance of the simple raw metric of models on ImageNet, and that all predictors suffer on medical datasets. Our results highlight the potential of combining different information sources for reliably predicting transferability across varied domains.