 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Basics on Predicting Transfer Performance
Paper and Code
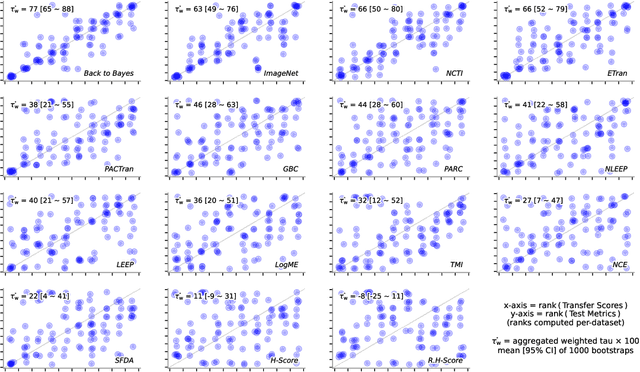
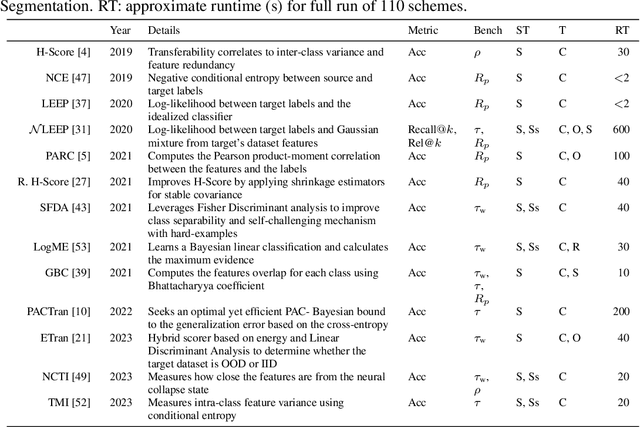
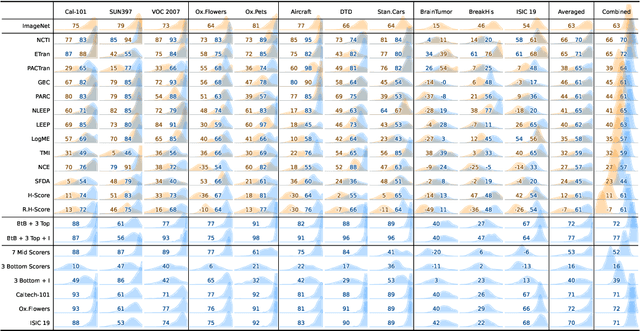
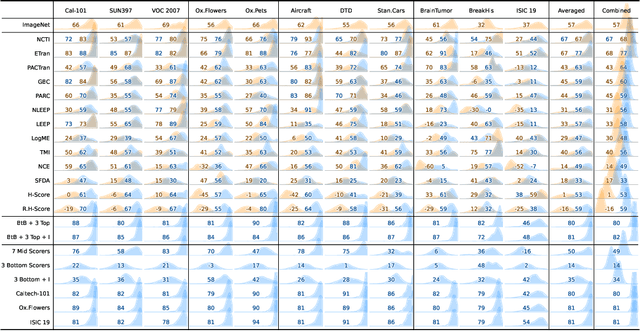
In the evolving landscape of deep learning, selecting the best pre-trained models from a growing number of choices is a challenge. Transferability scorers propose alleviating this scenario, but their recent proliferation, ironically, poses the challenge of their own assessment. In this work, we propose both robust benchmark guidelines for transferability scorers, and a well-founded technique to combine multiple scorers, which we show consistently improves their results. We extensively evaluate 13 scorers from literature across 11 datasets, comprising generalist, fine-grained, and medical imaging datasets. We show that few scorers match the predictive performance of the simple raw metric of models on ImageNet, and that all predictors suffer on medical datasets. Our results highlight the potential of combining different information sources for reliably predicting transferability across varied domains.